
1 개요
많은 조직이 고객 요구사항을 더 빠르게 충족하고 비즈니스 민첩성을 달성하기 위해 VMware vSphere® 클론을 성공적으로 채택했습니다. 그러나 개발 및 운영 팀은 vSphere 플랫폼에서 제공되는 다양한 유형의 클론의 성능 측면과 배포 속도에 대한 질문을 받게 되는 경우가 많습니다.
vSphere는 Full Clone, Linked Clone, Instant Clone의 세 가지 유형의 클론을 제공합니다. 이 백서에서는 다양한 워크로드를 사용하여 클론 성능을 평가하고 다양한 클론 유형의 프로비저닝 속도에 대해 설명합니다. 또한 프로비저닝 속도를 개선하기 위한 몇 가지 팁과 요령을 제공합니다.
2 소개
게스트 운영 체제 및 애플리케이션을 설치하는 데 시간이 많이 걸릴 수 있습니다. 클론을 사용하면 가상 시스템의 복사본을 편리하게 만들 수 있습니다. vSphere는 세 가지 유형의 클론을 제공합니다.
풀 클론(Full Clone)
풀 클론은 복제 작업 후 상위 VM과 아무것도 공유하지 않는 독립 하위 VM입니다. 전체 복제본의 진행 중인 작업은 상위 VM과 완전히 별개의 작업입니다.
링크드 클론(Linked Clone)
연결된 클론은 상위 VM과 가상 디스크를 지속적으로 공유하는 하위 VM입니다. 연결된 클론은 상위 스냅샷으로 만들어지며 스냅샷 기반 델타 디스크를 사용합니다. 하위 디스크는 COW(Copy-on-Write) 메커니즘을 사용하며, 이 메커니즘에서는 쓰기에 의해 복사될 때까지 가상 디스크에 데이터가 없습니다. 이 최적화는 스토리지 공간을 절약합니다.
인스턴트 클론(Instant Clone)
인스턴트 클론은 상위 VM과 지속적으로 가상 디스크 및 메모리를 공유하는 하위 VM입니다. 링크드 클론과 마찬가지로 인스턴트 클론도 델타 디스크를 활용하여 스토리지 공간을 절약합니다. 또한 인스턴트 클론은 상위 VM의 메모리 상태를 공유하여 효율적인 메모리 사용을 제공합니다. 인스턴트 클론은 항상 전원이 꺼진 VM 대신 실행 중인 VM에서 생성되며 컨테이너와 거의 같은 기능을 합니다. 인스턴트 클론은 전체 클론 또는 연결된 클론과는 달리 항상 전원이 켜진 상태에서 생성되며 프로비저닝 전에 사용자가 상위 VM 내에서 실행되는 게스트 애플리케이션과 연결할 수 있습니다.
풀 클론은 상위 가상 시스템과 가상 디스크 또는 메모리를 공유하지 않으므로 일반적으로 연결된 클론 또는 인스턴트 클론보다 성능이 우수합니다. 그러나 풀 클론은 다른 클론 유형보다 프로비저닝 시간이 더 오래 걸립니다.
3 Scope of Paper
vSphere Client, pyVomi, PowerCLI 또는 다른 SDK 클라이언트에서 프로비저닝된 클론의 동작은 모두 공통 vSphere API를 사용하므로 동일하며, 클론을 프로비저닝하거나 게스트를 사용자 지정하는 기능이 표시됩니다. SDK의 선택은 사용자의 선호도에 따라 달라집니다.
VMware PowerCLI™와 같은 다른 언어에도 동일한 원칙이 적용되지만 pyVomi 기반 프로그램에 초점을 맞출 것입니다. (pyVomi는 vSphere 및 VMware vCenter Server®를 관리할 수 있는 VMware vSphere API용 Python SDK입니다.) 우리는 서로 다른 클론 유형의 성능 측면과 프로비저닝 속도에만 초점을 맞추고 있습니다. 인스턴트 클론에 대한 게스트 사용자 지정과 같은 고려 사항은 본 문서의 범위를 벗어납니다.
추가 리소스:
- vSphere Web Services SDK
https://code.vmware.com/docs/11721/vmware-vsphere-web-services-sdk-programming-guide/ - VMware APIs and SDKs
https://code.vmware.com/sdks - Guest customization support for instant clones https://www.virtuallyghetto.com/2020/05/guest-customization-support-for-instant-clone-in-vsphere-7.html
4 성능 테스트 구성 및 방법론
이 절에서는 테스트베드 구성, 워크로드 및 일반 테스트 방법에 대해 설명합니다.
4.1 테스트베드 구성
테스트 베드는 VMware ESXi™ 7.0 U1을 실행하는 두 대의 Dell R930 서버로 구성되었습니다. 각 쿼드 소켓 서버는 24개의 코어를 가진 두 개의 인텔 Xeon E7-8890 프로세서를 가지고 있었으며 2.20GHz에서 실행되었으며 4TB 메모리를 가지고 있었다. 각 호스트에는 두 개의 Intel 10GbE 네트워크 어댑터가 있습니다. 관리 및 프로비저닝 네트워크는 고유한 10GbE 네트워크 어댑터를 사용했습니다. 스토리지에는 Dell EMC Unity 600 All-Flash 어레이의 10TB VMFS 볼륨과 Dell EMC VNX7600 All-Flash 어레이의 2TB VMFS 볼륨이 포함되어 있습니다.
4.2 워크로드
이 연구에서는 여러 워크로드를 사용했으며, 그 다음에 설명합니다.
4.2.1 OLTP 데이터베이스 워크로드
우리는 오픈 소스 HammerDB(https://hammerdb.com/)를 TPC-C(http://www.tpc.org/tpcc/) 워크로드 프로파일)와 함께 클라이언트 로드 생성기로 사용했다. 성능 메트릭은 TPM(분당 트랜잭션)입니다.
참고: 이것은 기능의 이점을 테스트하기 위한 TPC-C 워크로드의 비준수 공정 사용 구현입니다. 공식 결과와 비교해서는 안 됩니다.
소프트웨어:
- VM config: 12 vCPUs, 32GB memory, 3 vmdk files (100GB system disk, 250GB database disk, 100GB log disk)
- Guest OS/Application: RHEL 7.6 / Oracle 12.2
- Benchmark: HammerDB using a TPC-C database size of 1000 warehouses
- HammerDB client: 10 users with 500ms think-time, 5 min ramp-up, 5 min steady-state
4.2.2 JVM 워크로드
우리는 산업 표준 SPECjbb 2015(https://www.spec.org/jbb2015/)를 클라이언트 로드 생성기로 사용했다. 성능 메트릭은 10회 이상 평균 처리된 요청(PR)입니다.
참고: NAT의 결과는 이 벤치마크에 대한 SPEC의 상표권 메트릭스와 비교할 수 없습니다.
소프트웨어:
- VM config: 4 vCPUs, 32GB memory, 1 vmdk file (16 GB disk)
- Guest OS/Application: CentOS / JVM
- SPECjbb benchmark parameters:
JAVA_OPTS : -Xms30g -Xmx30g -Xmn27g -XX:+UseLargePages -XX:LargePageSizeInBytes=2m -XX:-UseBiasedLocking -XX:+UseParallelOldGC
specjbb.control (type/ir/duration): PRESET:10000:300000
4.2.3 인-메모리 키-값 저장소 워크로드
우리는 게스트 애플리케이션으로 오픈 소스 Redis(https://redis.io/)를 클라이언트 로드 생성기로 오픈 소스 memtier_benchmark(https://redislabs.com/blog/memtier_benchmark-a-high-throughput-benchmarking-tool-for-redis-memcached/)를 선택했다. Redis는 데이터베이스, 캐시 또는 메시지 브로커로 사용할 수 있는 인기 있는 메모리 내 키 값 저장소입니다. 성능 메트릭은 4천만 개의 작업을 실행하는 평균 시간입니다.
소프트웨어:
- VM config: 4 vCPUs, 12GB memory, 2 vmdk files (100GB OS disk, 100GB Redis/apps disk)
- Guest OS/Application: RHEL 7.6 / Redis
- Memtier benchmark parameters (2 sets of performance data with different SET:GET ratio):
memtier_benchmark -t 10 -n 200000 --ratio 100:0 -c 20 --hide-histogram -x 1 --key-pattern R:R --distinct-client-seed -d 256 --pipeline=5
memtier_benchmark -t 10 -n 200000 --ratio 0:100 -c 20 --hide-histogram -x 1 --key-pattern R:R --distinct-client-seed -d 256 --pipeline=5
4.2.4 가상 데스크톱 워크로드
VMware Horizon(https://www.vmware.com/products/horizon.html) 기술은 하이브리드 및 멀티 클라우드 구현 전반에 걸쳐 가상 데스크톱 및 애플리케이션을 안전하게 제공합니다. 가상 데스크톱 구축 플랫폼의 성능을 측정하는 워크로드로 VMware View Planner(https://www.vmware.com/products/view-planner.html)를 선택했습니다.
소프트웨어:
- VM config: 2 vCPUs, 4GB memory, 100GB thin disk (20GB consumed storage)
- Guest OS/Application: Windows 10 / View Planner
- View Planner run mode: Local
4.2.5 FIO 워크로드
FIO는 파일 시스템 I/O 성능을 측정하는 데 사용되는 I/O 마이크로 벤치마크입니다. 성능 메트릭은 초당 입출력(IOPS)입니다.
소프트웨어:
- VM config: 4 vCPUs, 32GB memory, 2 vmdks (100GB system disk, 50GB data disk)
- FIO benchmark parameters (2 sets of performance data with random I/O and sequential I/O):
-ioengine=libaio -iodepth=32 –rw=randrw –bs=4096 -direct=1 -numjobs=4 -group_reporting=1 -size=50G –time_based -runtime=300 -randrepeat=1
-ioengine=libaio -iodepth=32 –rw=readwrite –bs=4096 -direct=1 -numjobs=4 -group_reporting=1 -size=50G –time_based -runtime=300 -randrepeat=1
5 단일 클론 프로비저닝 시간 및 성능
먼저 단일 클론 생성에 대해 설명한 후 성능과 프로비저닝 시간을 비교합니다.
5.1 복제 생성
vSphere Client를 사용하여 전체 복제본을 생성할 수 있습니다. 이 클라이언트는 새 MAC 주소와 복제본에 대한 고유 식별자를 가진 새 전체 복제본을 생성하는 워크플로우를 제공합니다. ESXi 호스트의 명령줄 인터페이스를 통해 링크드 클론과 인스턴트 클론을 생성해야 합니다.
우리는 다음과 같은 사이비 코드를 사용했다.
5.1.1 풀 클론 생성
fcspec = vim.vm.Clonespec()
relocateSpec = vim.vm.RelocateSpec()
relocateSpec.diskMoveType = vim.vm.RelocateSpec.DiskMoveOptions.moveAllDiskBackingsAndDisallowSharing
fcspec.location = relocateSpec
vm.Clone(vm.parent, fcname, fcspec)
5.1.2 링크드 클론 생성
lcspec = vim.vm.Clonespec()
relocateSpec = vim.vm.RelocateSpec()
relocateSpec.diskMoveType = vim.vm.RelocateSpec.DiskMoveOptions.createNewChildDiskBacking
lcspec.location = relocateSpec
vm.Clone(vm.parent, lcname, lcspec)
5.1.3 인스턴트 클론 생성
icspec = vim.vm.InstantCloneSpec()
icspec.location = vim.vm.RelocateSpec()
icspec.name = icname
vm.InstantClone(icspec)
5.2 시험 작업 흐름
다음 일반 워크플로우를 사용하여 다양한 유형의 클론의 성능을 비교했습니다.
| 클론 | 시험 작업흐름 |
| 풀 클론 | • 기본 VM에서 전체 클론(하위 VM) 생성 • 전체 클론의 성능 측정 |
| 링크드 클론 | • 기본 VM에서 새 상위 VM 생성 • 상위 VM 전원 켜기 • 상위 VM의 스냅샷 생성 • 상위 VM에서 링크드 클론(하위 VM) 생성 • 링크드 클론의 성능 측정 |
| 인스턴트 클론 | • 기본 VM에서 새 상위 VM 생성 • 상위 VM 전원 켜기 • 모든 게스트 애플리케이션 실행 • 상위 VM에서 인스턴트 클론(하위 VM) 생성 • 인스턴트 클론의 성능 측정 |
5.3 성능 및 프로비저닝 시간
이 섹션에서는 VMFS 데이터스토어에 생성된 다양한 유형의 클론의 성능 및 프로비저닝 시간을 중점적으로 다룹니다. 이후 섹션에서는 vSAN 및 vVOL을 비롯한 다른 데이터스토어에 있는 클론의 성능 측면에 대해 살펴봅니다.
5.3.1 HammerDB 작업량
아래 그림 1은 VMFS 데이터스토어에서 HammerDB 워크로드를 실행할 때의 세 가지 유형의 클론의 성능 및 프로비저닝 시간을 비교합니다. 테스트 시나리오에서는 로컬 복제 작업을 사용했는데, 이는 상위 VM과 동일한 호스트에 하위 VM을 생성했음을 의미합니다.
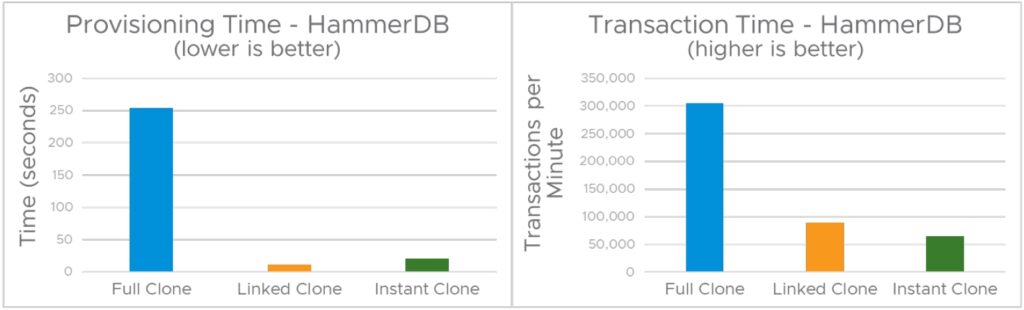
위의 그림 1과 같이 링크드 클론의 프로비저닝 시간은 풀 클론보다 23배 빠르며, 풀 클론을 생성하는 동안 전체 디스크 컨텐츠를 복사하는 데 시간이 걸리기 때문에 인스턴트 클론은 12배 빠릅니다. 링크드 클론(11초)에 비해 인스턴트 클론의 프로비저닝 시간(21초)이 약간 더 높습니다. 상위 메모리 페이지를 모두 쓰기 복사로 표시해야 하기 때문입니다. 이것은 일회성 작업이기 때문에 동일한 상위에서 후속 인스턴트 클론의 프로비저닝 시간이 링크드 클론의 프로비저닝 시간과 더 비슷합니다.
그림 1은 또한 풀 클론의 성능이 Disk I/O 집약적인 워크로드의 링크드 클론 및 인스턴트 클론보다 훨씬 뛰어나다는 것을 보여줍니다. 그 이유는 vSphere가 기존 redo 로그를 사용하여 VMFS 데이터스토어의 스냅샷 기반 델타 디스크를 관리하므로 디스크 I/O 지연 시간이 더 길어지므로 I/O 집약적인 워크로드의 게스트 성능에 상당한 영향을 미치기 때문입니다. 링크드 클론 및 인스턴트 클론은 쓰기에 의해 복사될 때까지 데이터가 포함되지 않는 스냅샷 기반 델타 디스크를 사용하기 때문에 이 지연 시간이 예상됩니다. 델타 디스크에 기록된 영역에 대한 읽기 요청은 델타 디스크에서 반환되고, 델타 디스크에 기록되지 않은 영역에 대한 읽기 요청은 상위 VM의 디스크로 리디렉션됩니다. 이러한 최적화는 스토리지 공간을 절약하지만, 특히 디스크 I/O 집약적인 워크로드의 경우 성능에 영향을 미칩니다. HammerDB 워크로드는 디스크 I/O 집약적이지만 CPU 및 메모리를 비롯한 다른 시스템 리소스에도 부담을 줍니다. 이 때문에 링크드 클론은 상위 VM과 메모리 상태를 공유하지 않기 때문에 인스턴트 클론의 성능이 링크드 클론보다 약간 낮습니다.
5.3.2 SPECjbb 작업량
아래의 그림 2는 SPECjbb 2015 워크로드를 실행할 때의 세 가지 유형의 클론의 프로비저닝 시간과 성능을 비교한 것입니다.
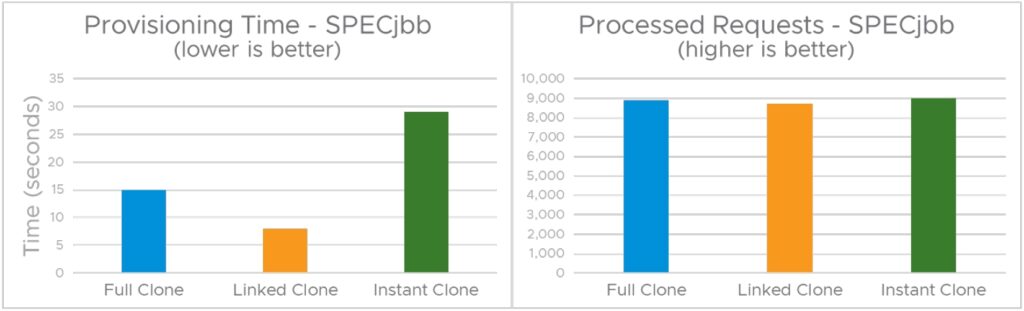
먼저, 퍼포먼스에 집중합시다. HammerDB 워크로드를 사용하는 클론 간에 관찰된 성능 차이와 대조적으로 그림 2는 SPECjbb 워크로드를 실행할 때 세 클론 모두에서 거의 동일한 성능을 보여 줍니다. 세 가지 클론 유형 간의 성능 메트릭(SPECjbb 처리 요청) 차이는 노이즈 범위(< 5%)에 있습니다. 이는 링크드 클론과 인스턴트 클론이 디스크 I/O 집약적인 워크로드에는 적합하지 않지만 CPU 및 메모리 집약적인 워크로드에는 좋은 성능을 발휘한다는 것을 보여줍니다.
역자 주 : "좋은 성능" 보다는 "영향을 덜 받는다"로 이해하면 좋을 것 같습니다.
그림 2에 표시된 풀 클론의 프로비저닝 시간은 이전 테스트 시나리오에서 HammerDB 워크로드(그림 1 참조)를 사용한 풀 클론 프로비저닝 시간 254초와 비교하여 15초밖에 되지 않았습니다. 이 시간 차이는 VM이 총 450GB 스토리지인 3개의 vmdk 파일로 구성된 HammerDB 시나리오와 비교하여 VM이 단일 16GB vmdk로 구성되었기 때문입니다. 따라서 풀 클론 프로비저닝 시간이 VM 스토리지에 비례한다는 것을 확인할 수 있습니다. 다시 한 번 말씀드리면, 부모의 모든 메모리 페이지를 쓰기 복사로 표시해야 하기 때문에 인스턴트 복제본의 프로비저닝 시간이 링크드 클론보다 더 길다는 것을 알 수 있습니다.
5.3.3 Memtier 벤치마크
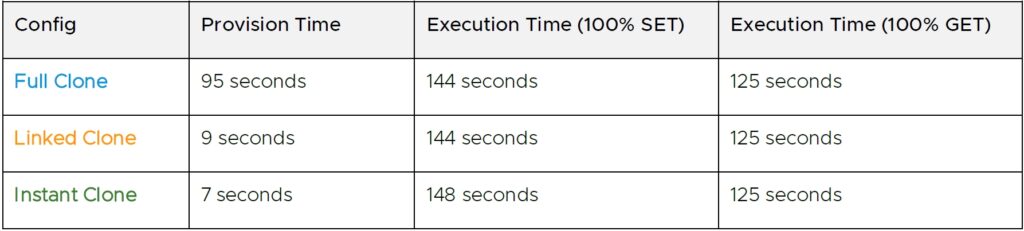
표 2는 Redis/Memtier 워크로드를 실행할 때의 클론의 프로비저닝 시간과 성능을 비교합니다.
SPECjbb 결과와 마찬가지로 GET:SET 혼합을 변경한 두 가지 테스트 시나리오에서 모든 클론에서 거의 동일한 성능을 관찰됩니다. Redis/Memtier 워크로드가 CPU 및 메모리 집약적이며 디스크 I/O 구성 요소가 없기 때문에 이러한 문제가 예상됩니다. 다시 한 번, 링크드 클론 및 인스턴트 클론의 프로비저닝 시간이 풀 클론 프로비저닝 시간보다 훨씬 짧은 것으로 확인됩니다.
5.3.4 성능이 상위 VM에 미치는 영향
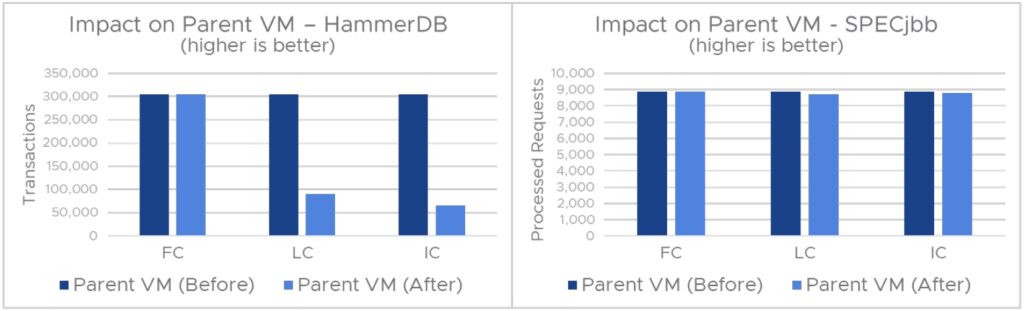
그림 3은 클론 생성 전후에 상위 VM을 실행할 때의 성능 영향을 보여줍니다. 전체 클론을 생성해도 HammerDB 및 SPECjbb 워크로드의 상위 VM 성능에 영향을 주지 않습니다. 이 문제는 전체 클론이 복제 작업 후 상위 VM과 아무것도 공유하지 않는 독립 하위 VM이기 때문에 발생합니다. 이와 비교하여 인스턴트 클론 또는 연결된 클론이 프로비저닝되면 두 클론 모두 지속적으로 상위 VM과 가상 디스크를 공유하기 때문에 상위 VM도 새로운 스냅샷 기반 델타 디스크를 얻게 됩니다. 인스턴트 클론의 경우 상위 VM도 하위 VM과 메모리 상태를 공유합니다. 프로비저닝 작업 후 상위 VM의 성능은 프로비저닝된 하위 VM의 성능과 동일합니다.
요약하면 단일 클론 테스트 시나리오에서 세 개의 워크로드에서 다음과 같은 관찰 결과를 도출합니다.
- 전체 클론의 프로비저닝 시간은 다음 두 가지 요소로 묶여 있습니다.
- 총 VM 스토리지 크기
- 소스 및 대상 데이터스토어의 디스크 I/O 처리량
참고: VM 스토리지 크기는 VM에서 사용하는 실제 스토리지 공간을 나타냅니다. VM 씬 디스크의 사용되지 않는 스토리지 공간은 프로비저닝 시간에 영향을 주지 않습니다.
- VM 크기 또는 디스크 I/O 처리량에 따라 인스턴트 및 링크드 클론의 프로비저닝 시간이 달라지지 않습니다.
- 링크드 클론 및 인스턴트 클론은 Disk I/O 집약적인 워크로드에 적합하지 않습니다.
- 각 복제본은 CPU 및 메모리 집약적인 워크로드에서 우수한 성능을 발휘합니다.
- 프로비저닝 작업 후 상위 VM의 성능은 프로비저닝된 하위 VM의 성능과 유사합니다.
6 원격 복제 프로비저닝 시간
인스턴트 클론은 상위 VM의 호스트에서만 생성할 수 있습니다. 연결된 클론은 공유 스토리지가 있는 상태에서 상위 VM과 다른 호스트에 생성할 수 있습니다. 이에 비해 원격 호스트에서는 종속성 없이 풀 클론을 생성할 수 있습니다.
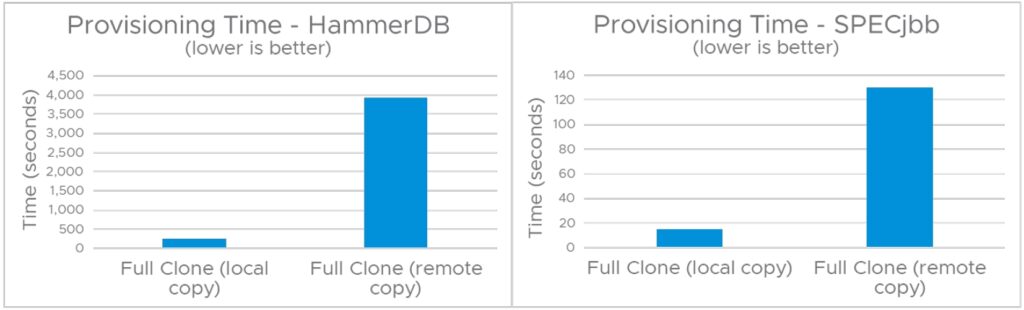
그림 4는 네트워크를 통한 복제의 성능 영향을 보여줍니다. 전체 복제 작업은 호스트의 스토리지 인터페이스(소스 데이터스토어와 대상 데이터스토어에 모두 액세스할 수 있는 호스트)를 사용하여 디스크 콘텐츠를 전송하므로 프로비저닝 네트워크 활용률과 호스트의 CPU 활용률이 감소합니다. 상위 VM의 호스트나 하위 클론의 호스트가 소스 데이터스토어와 대상 데이터스토어에 모두 액세스할 수 없는 경우 복제 작업은 NFC(Network File Copy) 서비스를 사용하여 네트워크를 통해 상위 VM 가상 디스크를 복사합니다.
NFC(nfclib를 사용하는)는 호스트의 스토리지 인터페이스(disklib/DataMover를 활용하는)에 비해 비효율적이라는 것을 관찰했다. 원격 풀 클론의 프로비저닝 시간이 HammerDB VM의 로컬 전체 클론보다 15배 느리고 SPECjbb VM의 프로비저닝 시간이 9배 느립니다. 또한 성능 테스트 결과, 원격 복제 작업 시 사용된 최대 네트워크 대역폭은 vmdk 파일 유형(씩 또는 씬) 및 디스크 컨텐츠에 따라 500Mbps에서 1.2Gbps 사이인 것으로 나타났습니다. 더욱이, NFC 서비스는 복수의 vmknics를 활용하지 않는다. ESXi에 새로운 최적화를 추가하여 원격 복제 작업의 프로비저닝 시간을 단축하려고 합니다.
7 다중 클론 성능 및 프로비저닝 시간
이 섹션에서는 VMFS 데이터스토어에 HammerDB 및 SPECjbb 워크로드를 사용하는 여러 클론이 있는 경우 서로 다른 유형의 클론(즉시, 링크 및 전체 클론)의 성능 및 프로비저닝 시간을 비교합니다.
7.1 성과
그림 5는 HammerDB 워크로드를 실행하는 하위 VM의 총 성능을 보여줍니다.
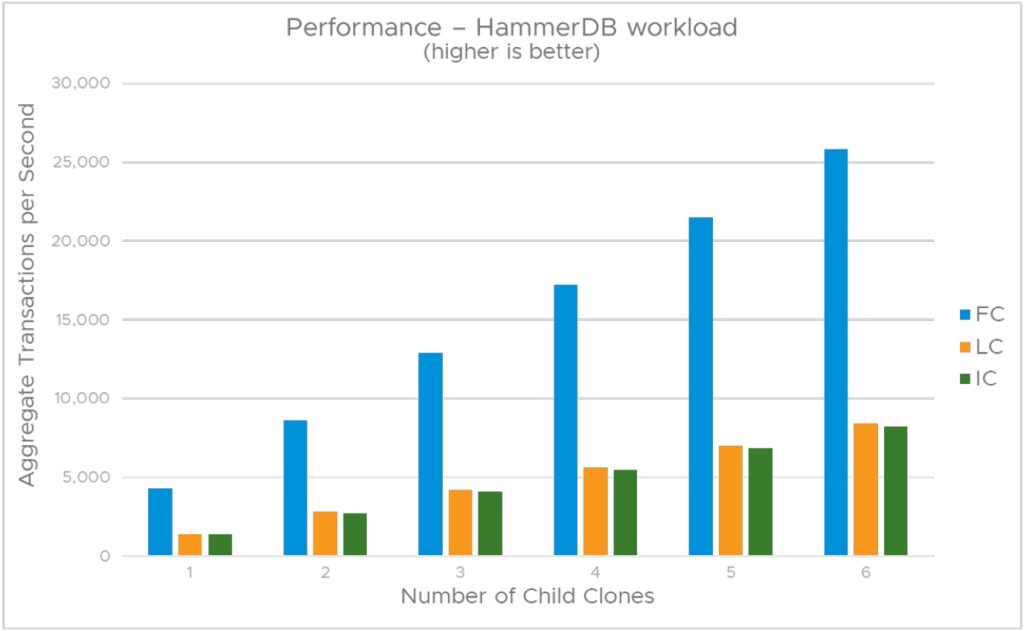
테스트에서는 하위 VM 수를 1개에서 6개로 변경했습니다. 링크드 클론과 인스턴트 클론의 성능(초당 총 트랜잭션 수)이 매우 유사하며 전체 클론 성능의 1/3을 차지한다는 것을 관찰했습니다. 링크드 클론 및 인스턴트 클론의 이러한 저조한 성능은 단일 클론/HammerDB 테스트 시나리오의 결과와 일치하며, redo 로그가 존재하여 디스크 I/O 지연 시간이 더 길어지기 때문입니다.
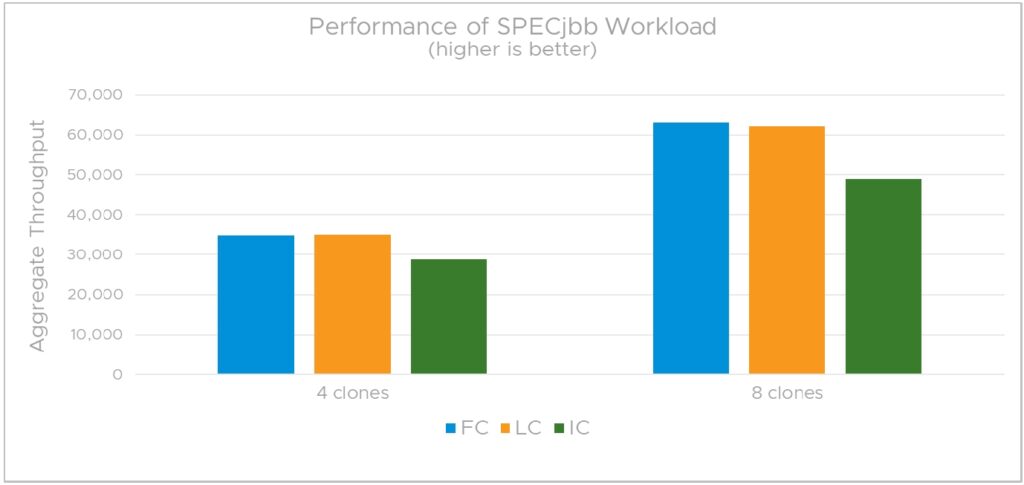
그림 6은 SPECjbb 2105 워크로드를 실행할 때 하위 VM의 총 성능을 보여 줍니다. 테스트에서는 하위 VM 수를 4개에서 8개로 변경했습니다. 첫째, 풀 클론 및 링크드 클론의 성능(초당 총 트랜잭션 수)은 본 문서 앞부분의 단일 클론 성능 시나리오에서 보듯이 4-클론 및 8-클론 시나리오 모두에서 거의 동일하다는 것을 관찰합니다. SPECjbb 2015는 CPU 및 메모리 사용량이 매우 높지만 디스크 I/O 구성 요소가 없기 때문에 이는 놀라운 일이 아닙니다. 최소한의 디스크 I/O 구성 요소를 갖춘 워크로드의 경우 링크드 클론과 풀 클론의 성능이 거의 동일할 것으로 예상됩니다.
그림 6은 하위 VM이 여러 개 있는 경우 인스턴트 클론의 성능이 링크드 클론 및 풀 클론보다 약 20% 낮음을 보여줍니다. 모든 인스턴트 클론은 상위 VM과 동일한 물리적 메모리 페이지를 공유하므로 메모리 집약적인 워크로드를 실행할 때 이러한 성능에 영향을 미칠 것으로 예상됩니다.
7.2 프로비저닝 시간
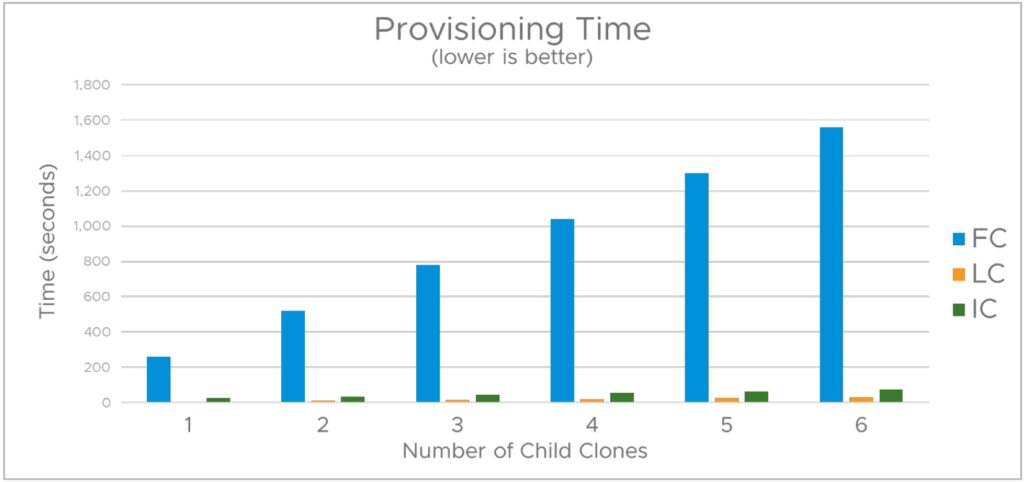
그림 7은 하위 클론 수가 증가함에 따라 다양한 유형의 클론의 프로비저닝 시간이 증가하는 방식을 비교합니다. 클론은 한 번에 하나씩 직렬 방식으로 생성되었습니다. 이후 섹션에서는 여러 클론을 병렬로 프로비저닝하는 방법에 대해 살펴봅니다.
클론을 연속적으로 생성할 때 총 풀 클론 프로비저닝 시간이 프로비저닝된 하위 클론 수에 따라 선형적으로 증가한다는 것을 관찰합니다. 일반적으로 링크드 클론과 인스턴트 클론의 프로비저닝 시간이 풀 클론 프로비저닝 시간보다 빠릅니다.
인스턴트 클론은 링크드 클론보다 프로비저닝 시간이 약간 더 길지만, 인스턴트 클론은 항상 전원이 켜진 상태로 생성되므로 프로비저닝 전에 사용자가 상위 VM 내에서 실행되는 게스트 애플리케이션에 연결할 수 있습니다.
7.3 인스턴트 클론 프로비저닝 시간 이해
그림 8은 VM 메모리가 인스턴트 클론 프로비저닝 시간에 미치는 영향을 보여줍니다.
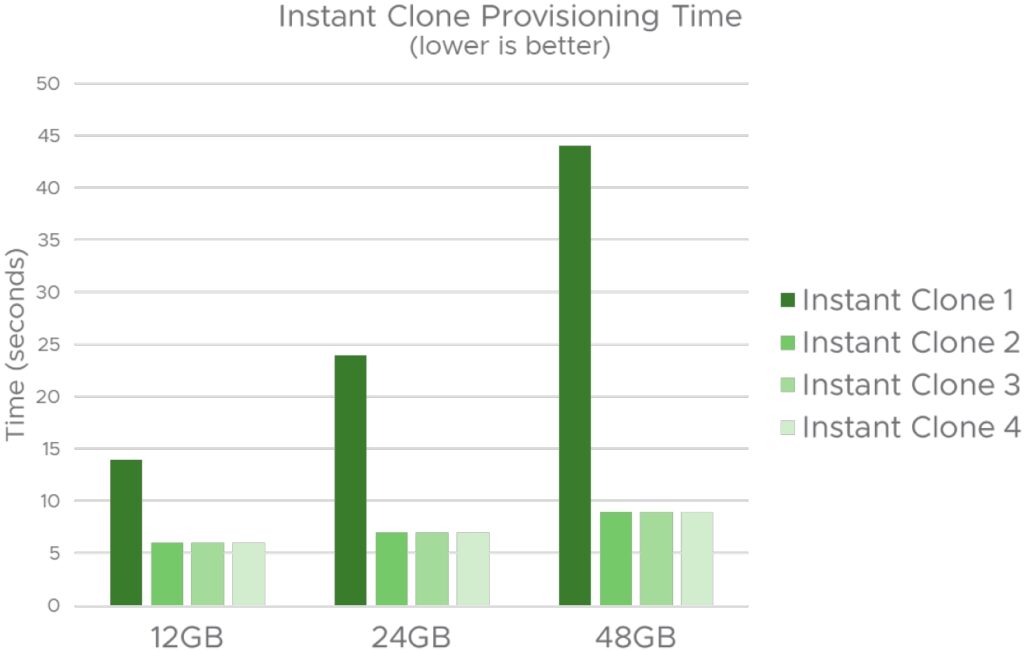
여기서 VM 메모리는 VM 할당 메모리를 참조하지 않고 ESXi에서 VM에 부여한 물리적 메모리를 참조합니다. 즉, 상위 VM 내에서 실행되는 게스트 애플리케이션이 터치한 메모리를 말합니다.
VM 메모리 크기를 12GB에서 48GB로 변경하는 세 가지 시나리오를 고려했습니다. 각 시나리오에서는 동일한 상위 항목에서 4개의 인스턴트 클론을 생성했습니다. 이 테스트에서 우리는 두 가지를 관찰합니다. 첫째, 상위 VM의 모든 메모리 페이지를 쓰기 복사로 표시해야 하기 때문에 첫 번째 인스턴트 클론의 프로비저닝 시간은 VM 메모리에 비례합니다. 또한 우리는 이 비용이 첫 번째 인스턴트 클론 생성 중에 발생하는 일회성 작업임을 확인하므로 동일한 상위에서 후속 인스턴트 클론의 프로비저닝 시간이 훨씬 짧다. ESXi에 새로운 최적화를 추가하여 첫 번째 인스턴트 클론의 프로비저닝 시간을 단축하려고 합니다.
8 대량 프로비저닝
클라우드 서비스는 일반적으로 구축 시간이 길어지는 데이터 센터 전반에 걸쳐 수십 또는 수백 개의 단일 템플릿 VM 인스턴스를 배포하는 것이 일반적입니다. 이 섹션에서는 프로비저닝 속도에 대해 논의하고 이를 개선하기 위한 제안을 합니다.
8.1 클론 생성
우리는 대량으로 클론을 만들기 위해 다음과 같은 의사 코드를 사용했다.
- 풀 클론 의사 코드 대량 생성
namePrefix = fcname
locSpec = vim.vm.RelocateSpec()
fcspec = vim.vm.Clonespec(location=locspec, powerOn=False, template=False)
bulkFC = [(myVm.Clone,
(vmFolder, namePrefix+str(vmIdx), fcspec))) for vmIdx in vmRange]
2. 링크드 클론 의사 코드 대량 생성
namePrefix = lcname
snapshot = myVm.snapshot.GetCurrentSnapshot()
locSpec = vim.vm.RelocateSpec()
locSpec.diskMoveType = vim.vm.RelocateSpec.DiskMoveOptions.createNewChildDiskBacking
lcspec = vim.vm.Clonespec(location=locSpec, powerOn=False, template=False, snapshot=snapshot)
bulkLC = [(myVm.Clone,
(vmFolder, namePrefix+str(vmIdx), lcspec))) for vmIdx in vmRange]
3. 인스턴트 클론 의사 코드 대량 생성
namePrefix = icname
locspec = vim.vm.RelocateSpec()
bulkIC = [(myVm.InstantClone,
(vim.vm.InstantCloneSpec(name=namePrefix+str(vmIdx), location=locspec),)) for vmIdx in vmRange]
8.2 프로비저닝 시간
그림 9는 SPECjbb 로컬 클론 100개의 프로비저닝 시간을 비교합니다.
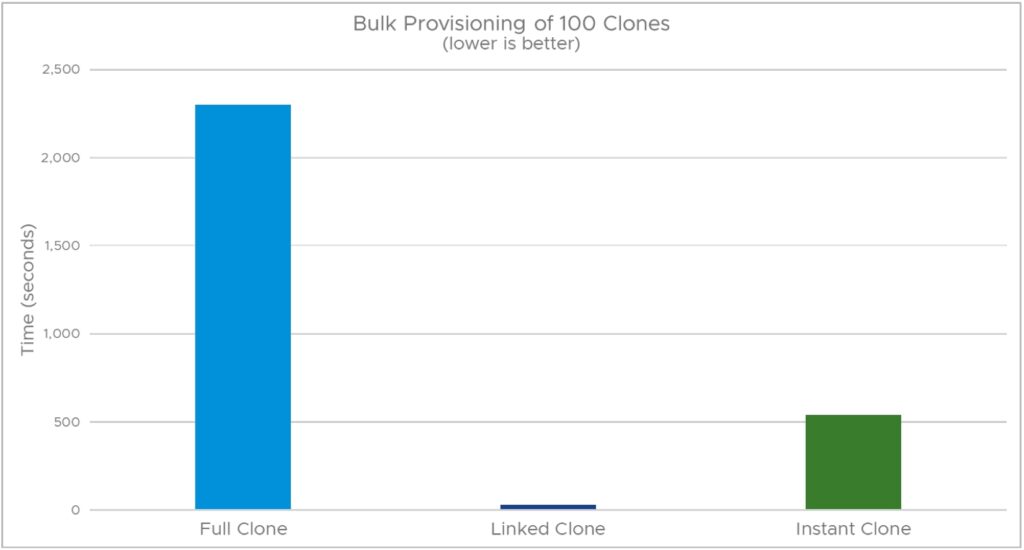
프로비저닝 시간이 30초밖에 되지 않는 링크드 클론은 전체 클론(2300초) 및 인스턴트 클론(539초)보다 성능이 훨씬 뛰어납니다.
8.3 전체 클론 프로비저닝 시간: 핫 클론 대 콜드 클론
기본적으로 vCenter에서는 활성 복제 작업의 동시성을 1로 제한합니다. 고급 vCenter 설정에는 동시성을 높일 수 있는 config.vpxd.ResourceManager.maxCostPerHost가 있습니다. 그러나 대량 프로비저닝 전에 상위 VM의 전원을 끄면 더 쉽게 동시성을 높일 수 있습니다. 그 이유는 vCenter가 실행 중인 상위 VM을 복제할 때(핫 클론 작업) 동시성을 1로 제한하지만 전원이 꺼진 상태(콜드 클론 작업)에서 콜드 부모 VM을 복제할 때는 동시성이 8로 증가하기 때문입니다.
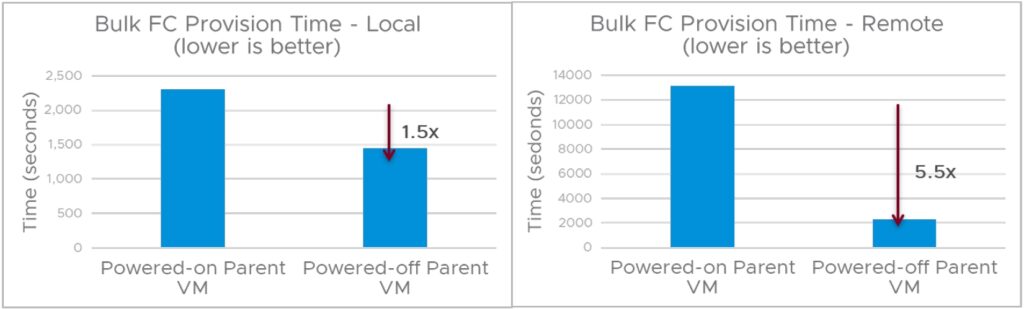
로컬 클론 및 원격 클론 프로비저닝 시나리오 모두에서 상위 시스템의 전원이 꺼질 때 프로비저닝 지속 시간이 크게 단축됩니다. 동시성이 8로 높기 때문입니다.
8.4 즉각적인 클론 프로비저닝 시간 단축
실행 중인 상위 VM 또는 고정 상위 VM에서 즉각적인 클론을 생성할 수 있습니다. 그림 11은 두 인스턴트 클론 생성 워크플로우 간의 차이를 보여줍니다.
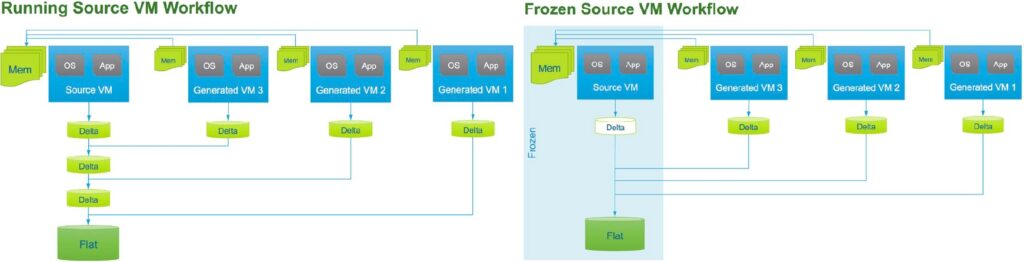
첫 번째 워크플로에서 실행 중인 상위 VM에서 인스턴트 클론이 생성되면 ESXi에서 잠시 상위 VM의 실행을 차단하고 VM 상태를 체크포인트한 다음 모든 페이지를 쓰기 복사로 표시합니다. 각 디스크에 대해 새 스냅샷(델타 디스크)이 생성되어 새 하위 VM과 디스크를 공유할 수 있습니다.
두 번째 워크플로에서는 일시 중지된 상위 VM에서 즉각적인 클론이 생성됩니다. 게스트 운영 체제 내에서 VMware Tools vmware-rpctool 유틸리티를 사용하고, instantclone.freez 명령이 명시되어 동결 작업이 개시되면 VM이 중지됩니다. 소스 VM이 일시 중지된 후 더 이상 실행되고 있지 않으며 상위 VM의 디스크는 읽기 전용 모드로 배치됩니다. 따라서 새 델타 디스크는 하위 VM에 대해서만 생성됩니다. 상위 VM의 전원이 꺼질 때까지 계속 정지 상태입니다.
이러한 워크플로우에 대한 자세한 내용은 New Instant Clone Architecture in vSphere 6.7” (
https://www.virtuallyghetto.com/2018/04/new-instant-clone-architecture-in-vsphere-6-7-part-1.html)를 참조하십시오. 다음은 실행 중인 Linux VM을 일시 중지하는 데 사용되는 예입니다.
// run the following command from a command terminal inside the guest vmware-rpctool "instantclone.freeze"
두 워크플로의 최종 결과는 동일하게 동작하는 인스턴트 클론을 생성합니다. 그러나 많은 인스턴트 클론을 배포할 때는 배포 시점과 프로비저닝 기간 모두에서 두 번째 워크플로를 사용하는 것이 좋습니다. 첫 번째 워크플로우(그림 11)를 사용하면 각 새로운 인스턴트 복제본에 대해 새 델타 디스크가 생성되므로 상위 VM의 디스크 체인 깊이가 깊어져 잠재적으로 디스크 체인 깊이 제한에 도달할 수 있습니다. 첫 번째 인스턴트 클론의 프로비저닝 시간은 두 워크플로 모두에서 거의 동일하지만, 첫 번째 워크플로우는 이후의 각 인스턴트 클론 프로비저닝 작업 중에 두 번째 워크플로와 비교하여 추가 지연 시간을 발생시킵니다. 예를 들어 두 번째 워크플로우는 후속 각 인스턴트 클론에 대해 추가 상위 델타 디스크를 생성하는 대기 시간을 발생시키지 않습니다. 또한 상위 VM이 동결되었으므로 상위 페이지를 후속 인스턴트 클론마다 Copy-on-write로 표시할 필요가 없습니다.
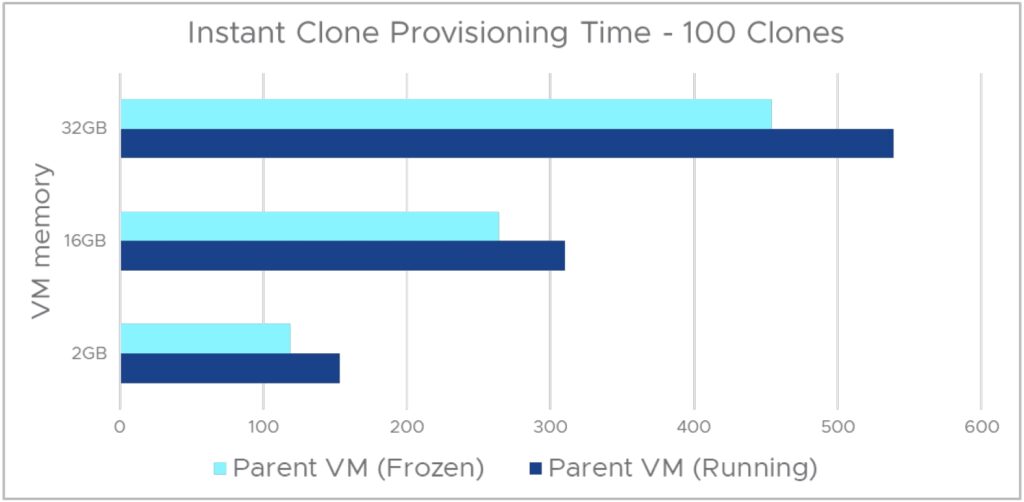
그림 12는 실행 중인 상위 VM과 동결된 상위 VM에서 100개의 즉각적인 클론의 프로비저닝 기간을 보여줍니다. 테스트 시나리오에서는 VM 메모리 크기를 2GB에서 32GB로 변경했습니다. 모든 시나리오에서 동결된 상위 VM을 사용할 경우 프로비저닝 시간이 15~20% 단축되는 것으로 확인되었습니다.
8.5 View Planner를 통한 Horizon View의 성능
이 섹션에서는 View Planner 벤치마크(https://www.vmware.com/products/view-planner.html)를 사용하여 가상 데스크톱 배포에서 다양한 유형의 클론의 성능을 살펴봅니다.
아래의 그림 13은 가상 데스크톱 배포 플랫폼의 확장성 및 성능을 CPU 집약적인 애플리케이션 그룹 A 및 스토리지 관련 애플리케이션 그룹 B에 대한 다양한 유형의 클론들과 비교합니다. View Planner의 성능 지표는 QoS(서비스 품질) 점수이며, 애플리케이션 응답 시간의 95% 이내여야 합니다.
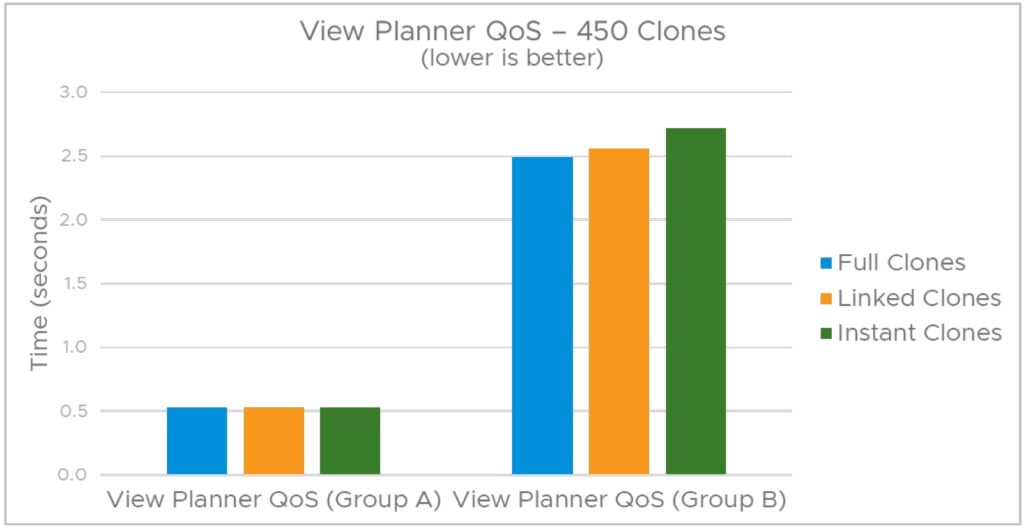
View Planner 워크로드 애플리케이션은 워드 프로세서, 스프레드시트, 웹 브라우저, 문서 뷰어 등 가상 데스크톱 사용자에게 일반적인 애플리케이션을 나타내며 CPU에 민감한(그룹 A) 및 스토리지 민감(그룹 B)으로 그룹화되어 각각 다른 QoS 요구 사항을 갖습니다. 그룹 A와 B에 대한 QoS 점수가 View Planner에서 제공하는 임계값 한계 내에 있는 경우, 그 경우에만 테스트를 통과한 것으로 간주됩니다. 그룹 A와 그룹 B 작업 모두에서 링크드 클론 및 인스턴트 클론은 VDI 테스트 시나리오에서 풀 클론과 매우 유사한 성능을 보였습니다.
9 vVOL 및 vSAN 데이터스토어에서 성능 복제
이 섹션에서는 VMFS, vSAN 및 vVOL을 비롯한 서로 다른 데이터스토어에 있는 클론의 성능 측면에 대해 살펴봅니다. 기본 스토리지가 클론 성능에 미치는 영향을 파악하려면 VMware에서 지원하는 다양한 스냅샷 형식을 알아야 합니다. 그 이유는 상위 VM의 스냅샷에서 클론이 생성되기 때문입니다.
VMware는 다양한 스냅샷 형식을 지원합니다. 선택한 스냅샷 형식의 유형은 기본 데이터스토어 및 VMDK 특성을 비롯한 여러 요인에 따라 달라집니다.
vmfsSparse
일반적으로 redo 로그 형식이라고 하는 vmfsSparse는 VMware에서 사용하는 원래 스냅샷 형식입니다. VMFS, NFS(VAAI-NAS 없음) 및 vSAN 5.5에 사용되는 형식입니다.
vsanSparse
VSAN 6.0에 도입된 vsanSparse(https://core.vmware.com/resource/vsansparse-snapshots-tech-note)는 메모리 내 메타데이터 캐시와 보다 효율적인 희소 파일 시스템 레이아웃을 사용하는 새로운 스냅샷 형식이며, vmfsSparse/redolog 형식에 비해 훨씬 더 기본 디스크 성능 수준에 가깝게 작동할 수 있습니다.
vVols/native 스냅샷
vVols 환경에서는 스냅샷 및 복제 작업과 같은 데이터 서비스가 스토리지 어레이로 오프로드됩니다. vVol을 사용하면 스토리지 벤더가 기본 스냅샷 기능을 사용하므로 vSphere 스냅샷은 거의 기본 Disk 성능 수준에서 작동할 수 있습니다.
9.1 시험 환경
VMFS 구성
Dell PowerEdge R930 서버:
- 각각 24코어 2.2GHz Intel Xeon E7-8890 CPU가 장착된 4개의 소켓
- 4TB 메모리
- Dell EMC Unity 600 All-Flash 어레이
vSAN 구성
각각 다음과 같이 구성된 Dell PowerEdge R740 서버의 4-노드 클러스터:
- 각각 20코어 2.4GHz Intel Xeon Gold 6148 CPU가 장착된 소켓 2개
- 768GB 메모리
- vSAN 버전 7.0.2-1.0.17873275
- vSAN 데이터스토어 – 호스트당 디스크 그룹 2개(NVMe 캐시 디스크 + 2*SATA SSD 용량 디스크)
vVOL 구성
Dell PowerEdge R740 서버:
- 각각 20코어 2.4GHz Intel Xeon Gold 6148 CPU가 장착된 소켓 2개
- 768GB 메모리
- vVOL 스토리지 어레이: Dell EMC PowerStore 5000T(NVMe 지원)
9.2 성능
표 3에는 VMFS, vSAN 및 vVOL을 비롯한 세 데이터스토어 모두에 다양한 워크로드가 있는 스냅샷이 있는 경우 게스트 애플리케이션 성능 손실에 대한 요약이 나와 있습니다. 각 데이터스토어 시나리오에서 스냅샷과 함께 표시되는 성능 손실은 해당 데이터스토어에 스냅샷이 없는 기준 성능에 비례합니다.
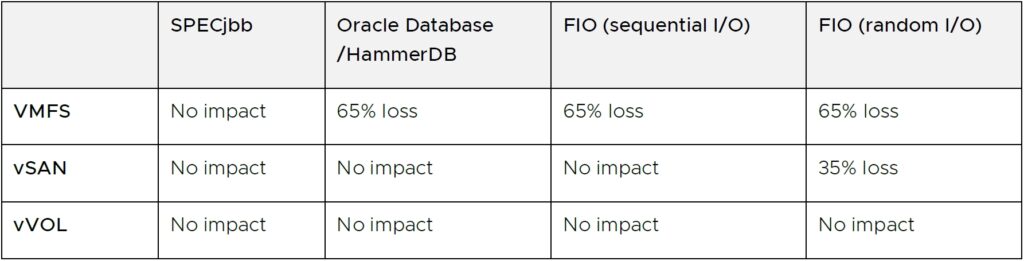
VMFS 데이터스토어를 사용할 때 VM 스냅샷이 있으면 게스트 애플리케이션 성능에 가장 큰 영향을 미칩니다. 일반적으로 디스크 I/O 구성 요소가 거의 65%의 처리량을 손실하는 게스트 애플리케이션을 관찰합니다. 이에 비해 vSAN 데이터스토어에 VM 스냅샷이 있으면 순차적 I/O가 대부분인 워크로드의 게스트 애플리케이션 성능에 미치는 영향이 최소화됩니다. 세 가지 시나리오 중 vVol을 사용할 때 스냅샷이 있으면 게스트 성능에 가장 적은 영향을 미칩니다. 실제로 테스트 결과 스냅샷 체인을 늘렸음에도 영향이 거의 0에 가까운 것으로 나타났습니다.
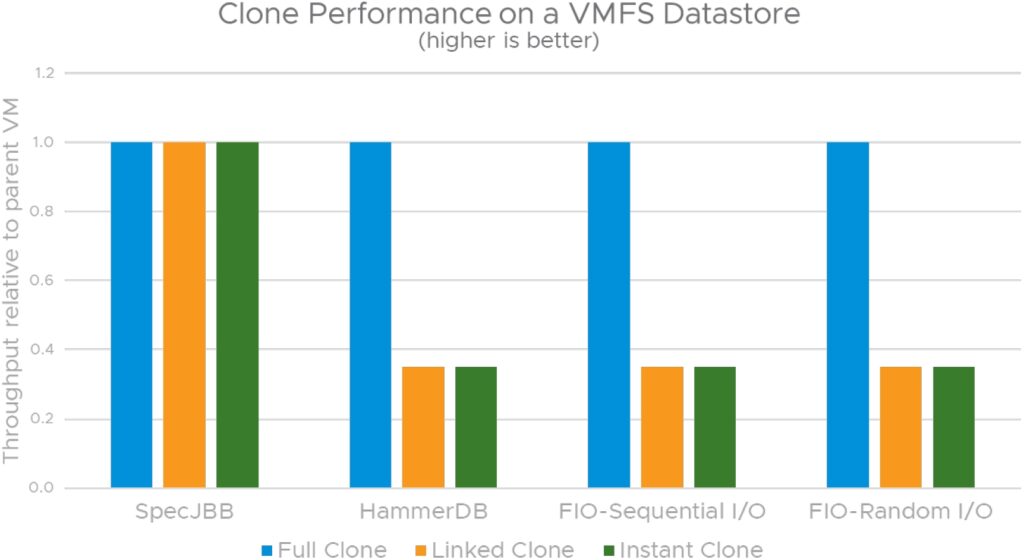
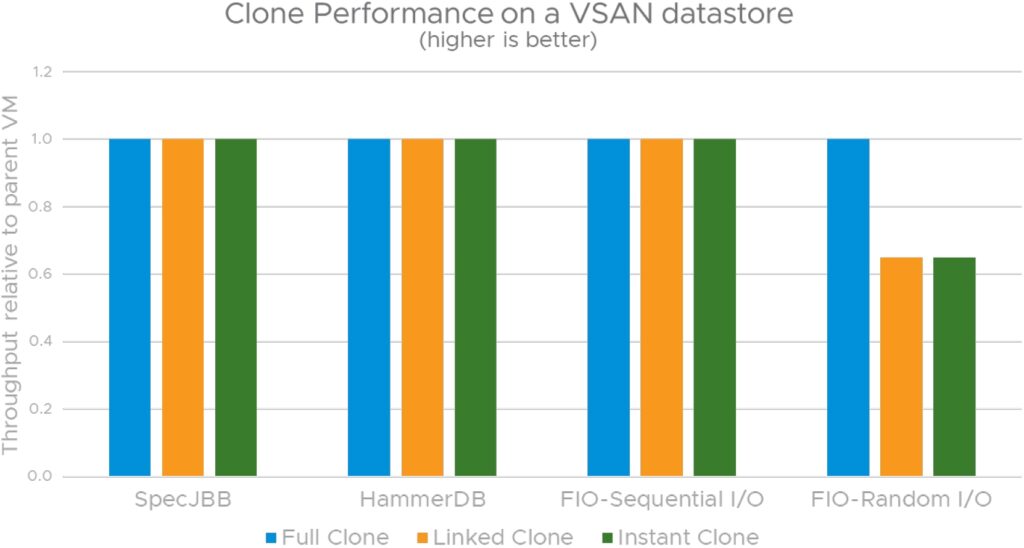
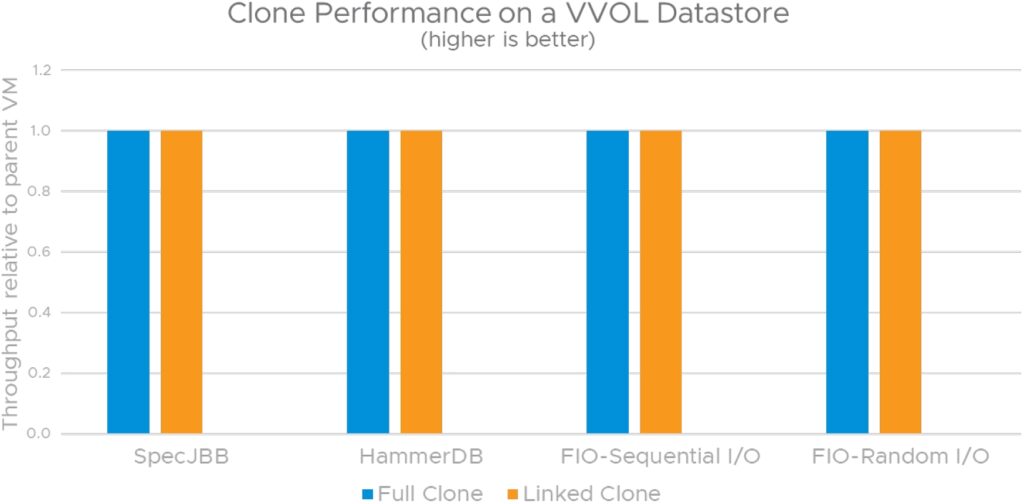
그림 14, 15 및 16은 VMFS, vSAN 및 vVOL 데이터스토어에서 다양한 워크로드가 포함된 클론(프로비저닝 작업 전에 상위 VM 내에서 실행되는 애플리케이션 성능과 비교)에서 표준화된 애플리케이션 성능을 보여 줍니다. 각 데이터스토어 시나리오에서 인스턴트 클론 및 링크드 클론에서 나타나는 성능 손실은 VM 스냅샷에서 발견된 성능 손실과 일치합니다. 이는 인스턴트 클론과 링크드 클론 모두 스냅샷 기반 델타 디스크를 사용하기 때문입니다. vVol은 인스턴트 클론을 지원하지 않습니다.
다양한 워크로드의 성능 데이터를 보면 vVOL 스토리지 어레이에서 지원하는 네이티브 스냅샷 덕분에 링크드 클론 및 VM 스냅샷을 사용할 때 vVOL이 가장 뛰어난 옵션임을 알 수 있습니다. 인스턴트 클론 및 VM 스냅샷을 사용할 경우 VMFS에 비해 vSAN을 사용하는 것이 좋습니다.
10 대량 프로비저닝 속도
아래 표에는 NVMe 또는 SSD가 지원하는 VMFS 데이터스토어를 가정한 여러 VM 배포에 대한 대량 프로비저닝 속도에 대한 지침이 나와 있습니다.
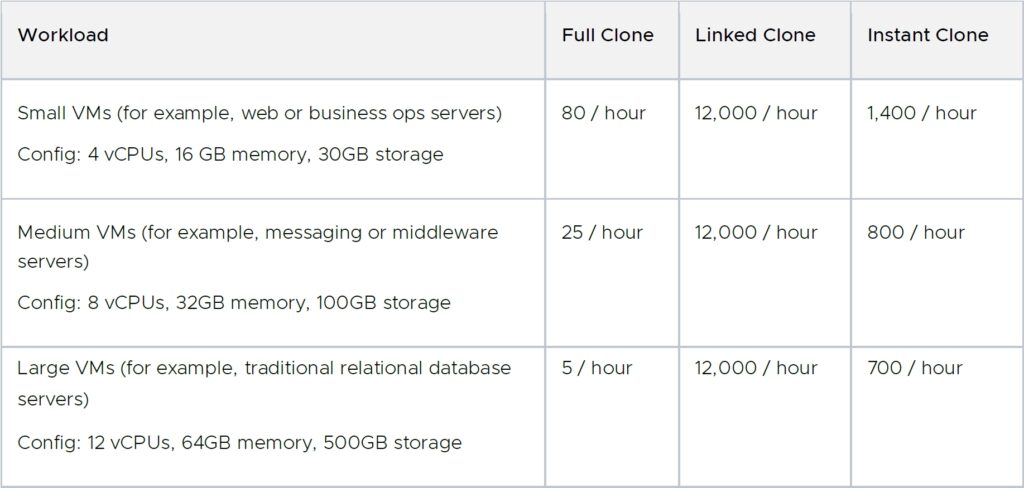
인스턴트 클론은 항상 전원이 켜진 상태로 생성되므로 일부 애플리케이션의 경우 핵심 요구사항인 프로비저닝 전에 상위 VM 내에서 실행되는 게스트 애플리케이션에 연결할 수 있기 때문에, 인스턴트 클론의 프로비저닝 시간이 연결된 클론보다 높습니다. 즉각적인 클론을 프로비저닝하는 것은 시간 대 기능의 트레이드오프입니다.
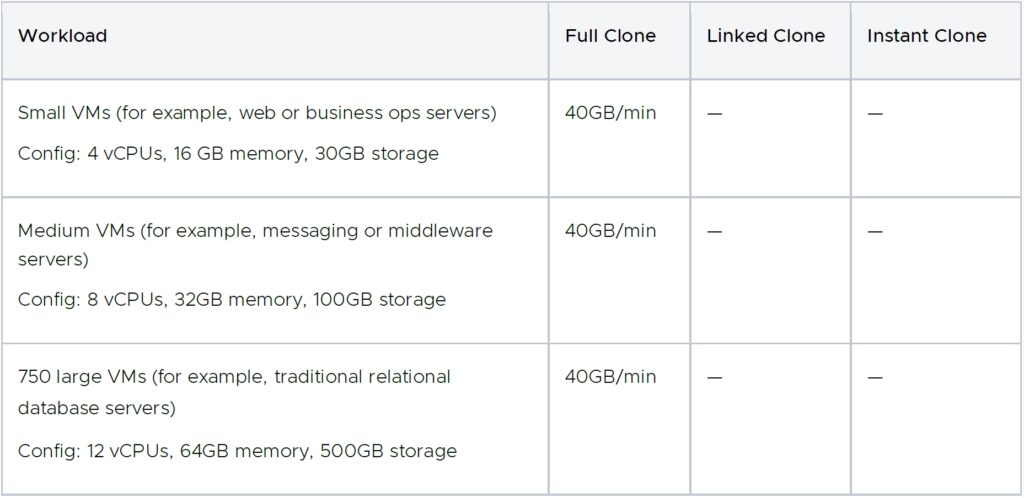
표 4에 표시된 것처럼 연결된 클론 및 인스턴트 클론의 프로비저닝 속도는 상당히 일정하며 VM 스토리지 크기에 영향을 받지 않습니다. 반대로 전체 클론 프로비저닝 속도는 총 VM 스토리지 크기와 소스 및 대상 데이터스토어의 디스크 I/O 처리량에 따라 달라집니다. VM 스토리지 크기는 VM에서 사용하는 실제 스토리지 공간을 의미합니다. 씬 디스크의 사용되지 않는 스토리지 공간은 프로비저닝 시간에 영향을 주지 않습니다. 따라서 VM 프로비저닝 속도를 스토리지 처리량 측면에서 표현하면 도움이 될 수 있습니다.
11 결론적 발언
가상 시스템 복제는 vCenter에서 가장 많이 사용되는 프로비저닝 작업 중 하나입니다. vSphere는 세 가지 유형의 클론(전체 클론, 링크드 클론, 인스턴트 클론)을 제공하며 각각 메모리 및 스토리지 효율성 및 성능이 다릅니다. 궁극적으로는 비즈니스 목표, 워크로드, 프로비저닝 시간 및 성능에 따라 클론 유형을 선택할 수 있습니다. 이 기술 백서에서는 이러한 서로 다른 클론의 성능 측면과 프로비저닝 속도에 대해 모두 논의했습니다.
테스트 결과는 다음과 같습니다.
- 풀 클론은 상위 VM과 디스크 또는 메모리 상태를 공유하지 않기 때문에 일반적으로 전체 클론이 링크드 클론 및 인스턴트 클론보다 성능이 우수합니다.
- VMFS 데이터스토어를 사용할 때 인스턴트 클론 및 링크드 클론은 스냅샷 기반 디스크 및 redo 로그에 의존하여 추가적인 디스크 I/O 지연 시간을 발생시키기 때문에 디스크 I/O 집약적인 워크로드에 적합하지 않습니다.
- 클론 또는 VM 스냅샷을 사용할 때는 vSAN 및 vVOL 데이터스토어가 VMFS 데이터스토어의 더 나은 대안입니다. 인스턴트 클론은 vVOL에서 지원되지 않습니다.
- 풀 클론과 거의 동일한 성능을 갖춘 인스턴트 클론 및 링크드 클론은 Horizon View 데스크톱 솔루션에 적합한 후보입니다.
- Horizon View를 넘어서는 즉각적인 클론 및 링크드 클론은 중요한 I/O 구성 요소 없이 CPU 및 메모리 집약적인 워크로드에서도 매우 우수한 성능을 발휘합니다.
- 링크드 클론은 일반적으로 상위 VM과 메모리 상태를 공유하지 않기 때문에 인스턴트 클론보다 성능이 약간 우수합니다.
- 인스턴트 클론 및 링크드 클론의 프로비저닝 시간이 풀 클론 프로비저닝 시간보다 훨씬 짧습니다.
- 풀 클론의 프로비저닝 시간은 총 VM 스토리지 크기와 소스 및 대상 데이터스토어의 디스크 I/O 처리량의 두 가지 요인에 의해 제한됩니다. VM 씬 디스크의 사용되지 않는 스토리지 공간은 프로비저닝 시간에 영향을 주지 않습니다.
- 핫 클론(실행 중인 상위 VM의 클론)과 비교하여 콜드 클론을 프로비저닝하면 대량 클론을 생성하는 동안 vCenter의 동시성이 향상되어 총 프로비저닝 시간이 크게 단축됩니다.
- 링크드 클론의 프로비저닝 시간은 VM 크기 또는 디스크 I/O 처리량에 따라 다르지 않습니다.
- 프로비저닝 시간이 VM의 메모리 크기에 어느 정도 좌우되기는 하지만 인스턴트 클론의 프로비저닝 시간은 디스크 I/O 처리량에 따라 달라지지 않습니다.
- 고정된 상위 VM에서 인스턴트 클론을 프로비저닝하는 것은 구축 측면과 프로비저닝 시간 측면에서 모두 유용합니다.
- 원격 풀 클론의 프로비저닝 시간은 로컬 전체 클론의 프로비저닝 시간보다 훨씬 느립니다.
12 부록
다음 pyVmomi 코드 예제는 게스트 사용자 지정 없이 인스턴트 클론을 생성하는 방법을 보여 줍니다.
import sys
sys.path.append('/usr/lib/vmware/site-packages')
import argparse
import atexit
import getpass
import logging
import ssl
import pyVmomi
import pyVim
import pyVim.connect
from pyVmomi import vim, vmodl
from pyVim.task import WaitForTask
LOG_FORMAT="%(asctime)s %(levelname)s %(name)s:%(funcName)s: %(message)s"
logging.basicConfig(level=logging.DEBUG, format=LOG_FORMAT)
log = logging.getLogger('ictool')
def prompt():
parser = argparse.ArgumentParser(description='VMware Instant Clone Helper')
parser.add_argument('--hostname', required=True, help='vCenter hostname or ip')
parser.add_argument('--port' , required=True, type=int, help='vCenter sdk port')
parser.add_argument('--username', required=True, help='vCenter username')
parser.add_argument('--password', help='vCenter password')
parser.add_argument('srcname', help='Name of Source VM')
parser.add_argument('dstname', help='Name of Destination VM')
args = parser.parse_args()
if args.password is None:
password = getpass.getpass()
log.debug("%s", args)
if args.password is None:
args.password = password
return args
def get_si(args):
log.info("Attempting to connect to %s:%s", args.hostname, args.port)
si = pyVim.connect.SmartConnect(host=args.hostname,
user=args.username,
pwd=args.password,
port=args.port,
sslContext=ssl._create_unverified_context())
atexit.register(pyVim.connect.Disconnect, si)
if not si:
log.error("Unable to connect to %s:%s", args.hostname, args.port)
sys.exit(0)
log.info('Successfully connected %s', si)
args._si = si
def get_vms(args):
log.debug("Querying all VMs")
content = args._si.content
view = content.viewManager.CreateContainerView(content.rootFolder, [vim.VirtualMachine], True)
vmlist = view.view
view.Destroy()
args._vmlist = vmlist
log.debug("Got %s VMs", len(vmlist))
def find_vm(args, name):
if not hasattr(args, '_vmlist'):
get_vms(args)
for vm in args._vmlist:
if vm.name == name:
return vm
log.error("Unable to find VM named %s", name)
sys.exit(1)
def main():
args = prompt()
si = get_si(args)
srcvm = find_vm(args, args.srcname)
log.info("Found %s as %s", args.srcname, srcvm)
icspec = vim.vm.InstantCloneSpec()
icspec.location = vim.vm.RelocateSpec()
icspec.name = args.dstname
log.info("InstantCloning %s to %s with spec %s",
args.srcname, args.dstname, icspec)
ictask = srcvm.InstantClone(icspec)
WaitForTask(ictask)
dstvm = ictask.info.result
log.info("Resulting vm %s is %s", args.dstname, dstvm)
if __name__ == '__main__':
main()작성자 정보
Sreekanth Setty는 VMware의 성능 엔지니어링 팀의 직원입니다. 그의 연구는 VMware 가상화 스택의 성능을 조사하고 개선하는 데 초점을 맞췄습니다. 가장 최근에는 실시간 마이그레이션 및 복제 공간에서도 마찬가지입니다. 그는 자신의 연구 결과를 많은 기술 논문에 발표했고 여러 기술 회의에서 발표해 왔다. 그는 텍사스 오스틴 대학에서 컴퓨터 공학 석사 학위를 받았다.
확인사항
저자는 Janitha Karunaratne와 Tanmay Nag에게 기고해 준 것에 대해 진심으로 감사한다. 또한 Yury Baskakov, Ying Yu, Nick Shi, Ruban Deventhiran, Tony Lin, Julie Brodeur를 포함한 팀원들에게 그들의 리뷰에 대해 감사를 표하고 싶다.
이 글은 아래 출처의 글을 기계번역한 것입니다.
출처 : https://www.vmware.com/techpapers/2021/cloning-vSphere7-perf.html