
기업에서는 대규모 ML(기계 학습) 모델 및 고성능 컴퓨팅에 대한 작업 속도를 높이기 위해 VM에 점점 더 많은 가상화된 GPU(vGPU)를 배포하고 있습니다. 이에 대한 한 가지 명확한 사용 사례는 GPU에 대한 수요가 높은 LLM(대형 언어 모델)의 교육 및 미세 조정입니다. 이 문서에서는 다양한 크기의 vGPU 프로필이 서버 클러스터에 수용될 때 호스트에 VM을 배치하기 위한 새로운 기능을 설명합니다. 더 작은 프로필을 통합하여 클러스터에 더 큰 프로필을 위한 공간을 확보하고 GPU 리소스 사용 방식을 최적화하는 방법을 보여줍니다.
이러한 대규모 모델에는 많은 수의 매개변수를 처리하고 합리적인 시간 내에 모델 교육 프로세스를 실행하기 위해 vSphere에 전체 메모리 프로필 vGPU로 표시되는 두 개 이상의 물리적 GPU가 필요한 경우가 많습니다. LLM 교육 프로세스는 몇 시간 또는 며칠 동안 GPU를 차지할 수 있습니다.
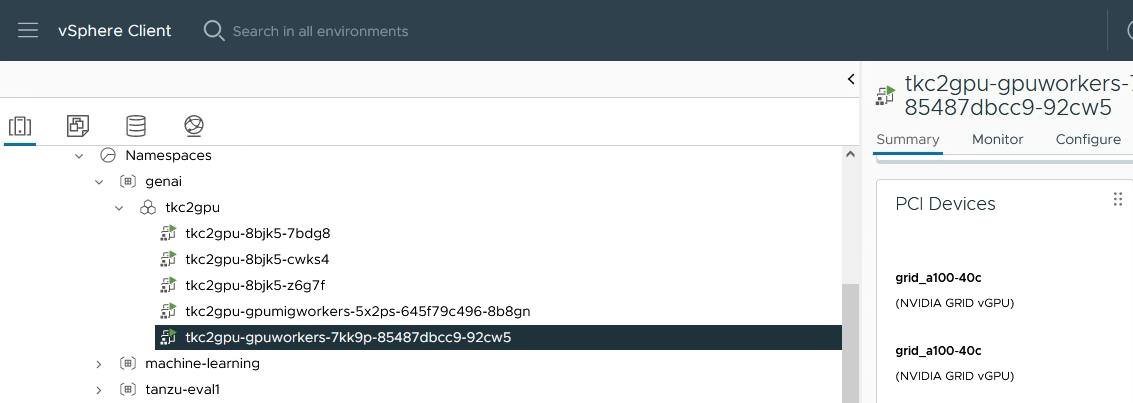
그림 1: 두 개의 A100 40GB GPU를 모두 사용하는 두 개의 전체 vGPU 프로필이 있는 VM의 vSphere Client 보기
전체 메모리 vGPU 프로필의 예는 “grid_a100-40c”입니다. 이는 시스템 관리자가 GPU 메모리 40GB를 모두 VM에 제공하기로 선택했음을 나타냅니다. 위 설정에서는 하나의 VM에서 이러한 vGPU 프로필 두 개를 볼 수 있습니다. 최신 A100 모델의 경우 이 프로필은 또 다른 예로서 “grid_a100_80c”입니다.
더 많은 vGPU 성능이 필요하면 2개, 4개 또는 8개의 물리적 GPU가 호스트의 VM에 완전히 할당될 수 있습니다. vSphere 8에서는 VM에 최대 8개의 vGPU 프로필을 할당할 수 있으며 vSphere 8.0 업데이트 2 릴리스에서는 이 수가 16개로 늘어납니다.
공통 호스트 하드웨어 클러스터를 공유하는 다양한 크기의 VM이 있는 경우 특정 크기의 VM 배치(vGPU 프로필 측면에서)에 따라 나중에 동일한 시스템 또는 클러스터에 적합한 다른 VM이 결정되는 상황이 있을 수 있습니다.
여기에서는 전체 메모리 vGPU 프로필을 통해 하나 이상의 전체 물리적 GPU를 VM에 전체 할당하는 방법에 대해 설명합니다. VM 통합을 위한 새로운 기능의 현재 구현에서는 부분 메모리 vGPU 프로필을 고려하지 않습니다. 여기에 적용할 수 있는 vGPU 프로필의 종류는 시간 분할 전체 메모리 할당 프로필(하나 이상의 GPU의 모든 메모리 점유)입니다.
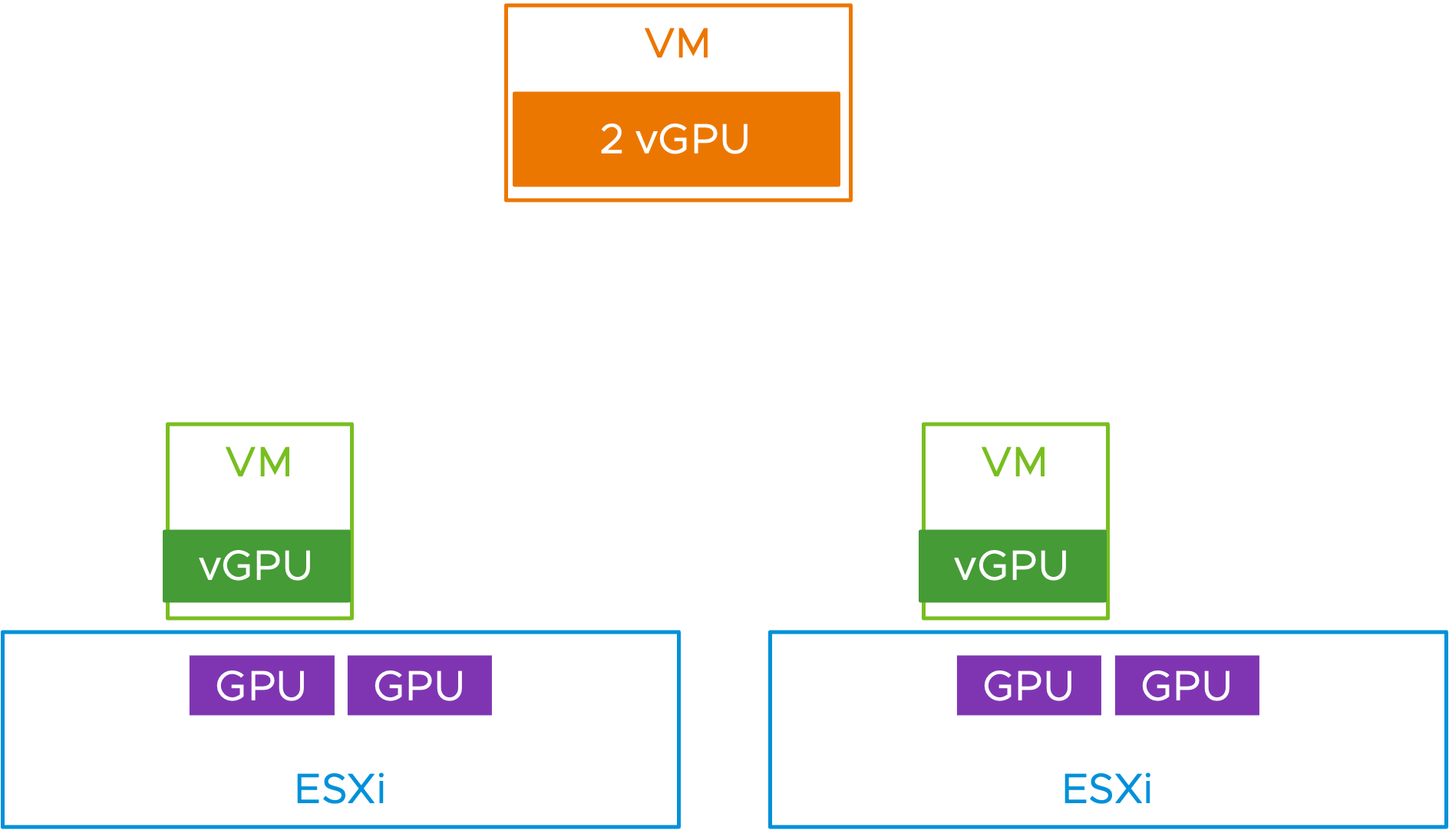
그림 2 – 1개의 더 큰 2 vGPU VM을 호스트 서버에 배치하는 것을 방해하는 2개의 단일 vGPU VM
예시 시나리오를 살펴보겠습니다. 클러스터에 2개의 호스트 서버가 있고 각 호스트 서버에 2개의 물리적 GPU가 있다고 가정해 보겠습니다. GPU는 VM의 여러 vGPU에 대한 요구 사항인 시간 분할 모드에 있습니다.
예를 들어 다양한 크기의 ML 또는 HPC 작업을 위해 일부 VM에는 1개의 전체 메모리 프로필 vGPU가 있고 다른 VM에는 2개의 전체 메모리 프로필 vGPU가 있기를 원합니다.
사용자는 자신의 VM을 생성하고 전원을 켭니다. 처음 두 개의 VM은 1개의 vGPU 프로필 VM입니다(각각 전체 GPU를 차지함). 이는 vSphere 8 업데이트 2 이전에 두 호스트 각각에 배치됩니다. 즉, 함께 묶어서 묶는 대신 효과적으로 각 호스트에 분산시킵니다.
이제 새로운 2-vGPU VM을 프로비저닝하려는 경우 이를 위한 공간이 없습니다. 하지만 호스트 전체에서 총 2개의 무료 GPU를 사용할 수 있습니다. 우리는 여기서 하드웨어를 최대한 활용하지 않습니다. 물론 VM 중 하나를 vMotion할 수 있지만 이는 특히 VM과 호스트 수가 많은 경우 시스템 관리자에게 추가 작업입니다.
VMware vSphere 8 업데이트 2는 유사한 크기의 vGPU 프로필 VM이 하나 이상의 호스트에 함께 유지되도록 하는 고급 기능을 클러스터에 추가하여 이러한 문제를 해결합니다. 클러스터의 vSphere Client에서 고급 매개변수를 다음과 같이 설정합니다.
VgpuVmConsolidation = 1
이 새로운 통합 기능을 사용하면 처음 두 개의 1-vGPU VM이 초기 VM 배치 시 하나의 호스트에 압축됩니다. DRS 배치 프로세스에서는 vGPU 프로필의 존재 여부와 크기를 고려합니다. 이제 2개의 전체 프로필 vGPU가 필요한 세 번째 VM을 프로비저닝할 수 있는 두 번째 호스트가 제공됩니다.
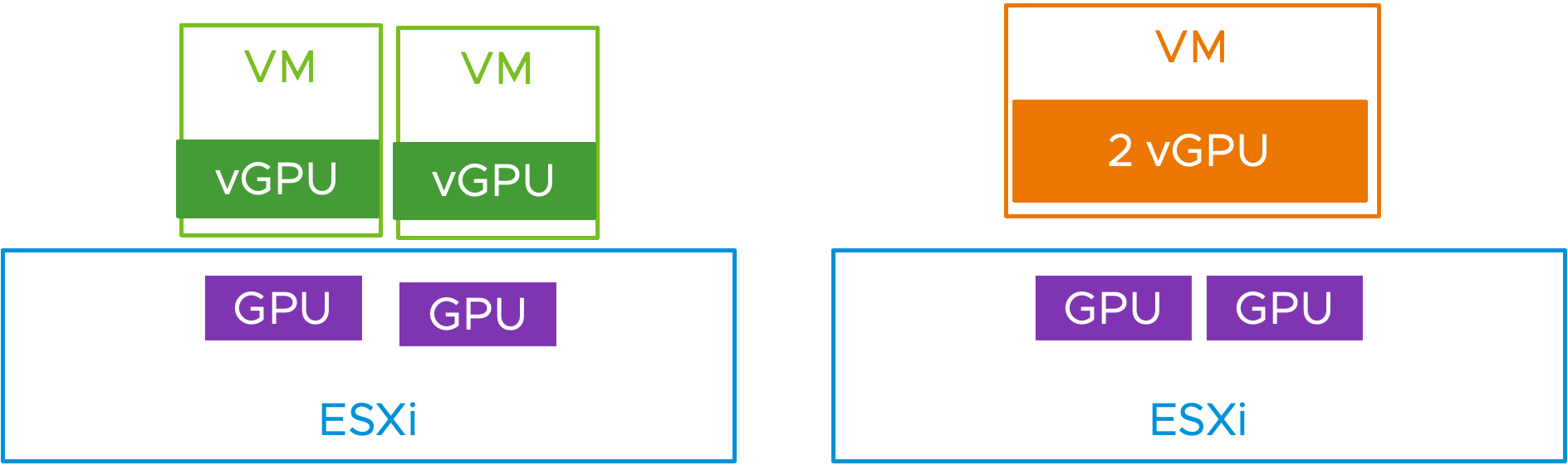
그림 3: 이제 두 개의 vGPU VM이 두 번째 GPU 호스트에 배치됩니다.
이 vSphere 8 업데이트 2 기능을 사용하면 해당 접근 방식을 사용하려는 경우 DRS가 통합을 달성하는 데 가장 적합한 호스트(즉, 이상적으로는 bin-packed VM)를 선택할 수 있습니다. vGPU VM에 대해 DRS 자동화가 활성화된 경우 권장 사항에 따라 vMotion이 발생합니다.
이상적으로 bin-packed 상태에 접근하려면 여러 DRS 패스가 필요할 수 있지만 각 패스가 조각화를 악화시켜서는 안 됩니다.
하나의 호스트에서 여러 vMotion 이벤트가 발생하는 것을 방지하기 위해 VgpuVmConsolidation 기능이 켜져 있을 때 두 번째 DRS 고급 구성 옵션도 설정합니다.
LBMaxVmotionPerHost = 1
두 번째 예
통합이 필요한 경우 VM을 더 적은 수의 호스트로 통합하는 것이 더 나은 옵션인 두 번째 시나리오는 다음과 같습니다. 이번에는 각각 동일한 모델의 4개의 물리적 GPU를 갖춘 3개의 호스트 서버가 있으며, 2개의 vGPU VM과 4개의 vGPU VM을 혼합하여 이러한 호스트에 배치하려고 합니다. 이 시나리오는 고객 배포에서 나타났습니다.
vSphere 8.0 업데이트 2 이전 버전에서는 더 작은 VM을 여러 호스트에 기본적으로 분산시키는 것과 관련하여 위에서 본 것과 동일한 배치 문제에 직면할 수 있습니다. 두 대의 서버에서 총 4개의 GPU를 사용할 수 있더라도 아래 다이어그램 상단에 있는 4개의 vGPU VM을 호스트에 배치할 수 없습니다. 두 개의 호스트 서버에 걸쳐 VM을 분할할 수 없습니다.
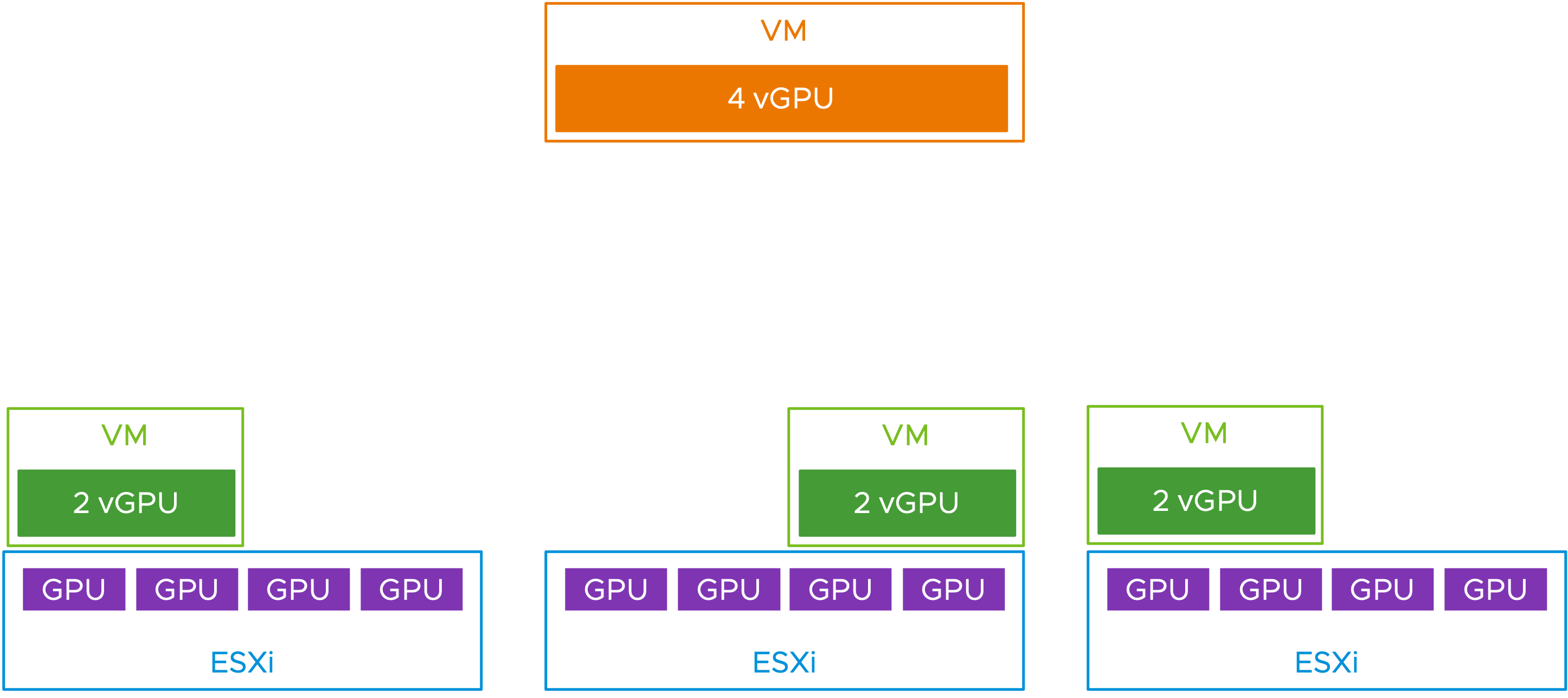
그림 4: 4개의 전체 vGPU VM이 호스트가 배치되기를 기다리고 있습니다.
그러나 DRS 클러스터 수준에서 VgpuVmConsolidation = 1을 설정하여 vSphere 8 업데이트 2의 통합 기능을 사용하면 해당 대규모 VM을 자체 호스트에 만족스럽게 배치하는 아래 시나리오를 대신 가질 수 있습니다.
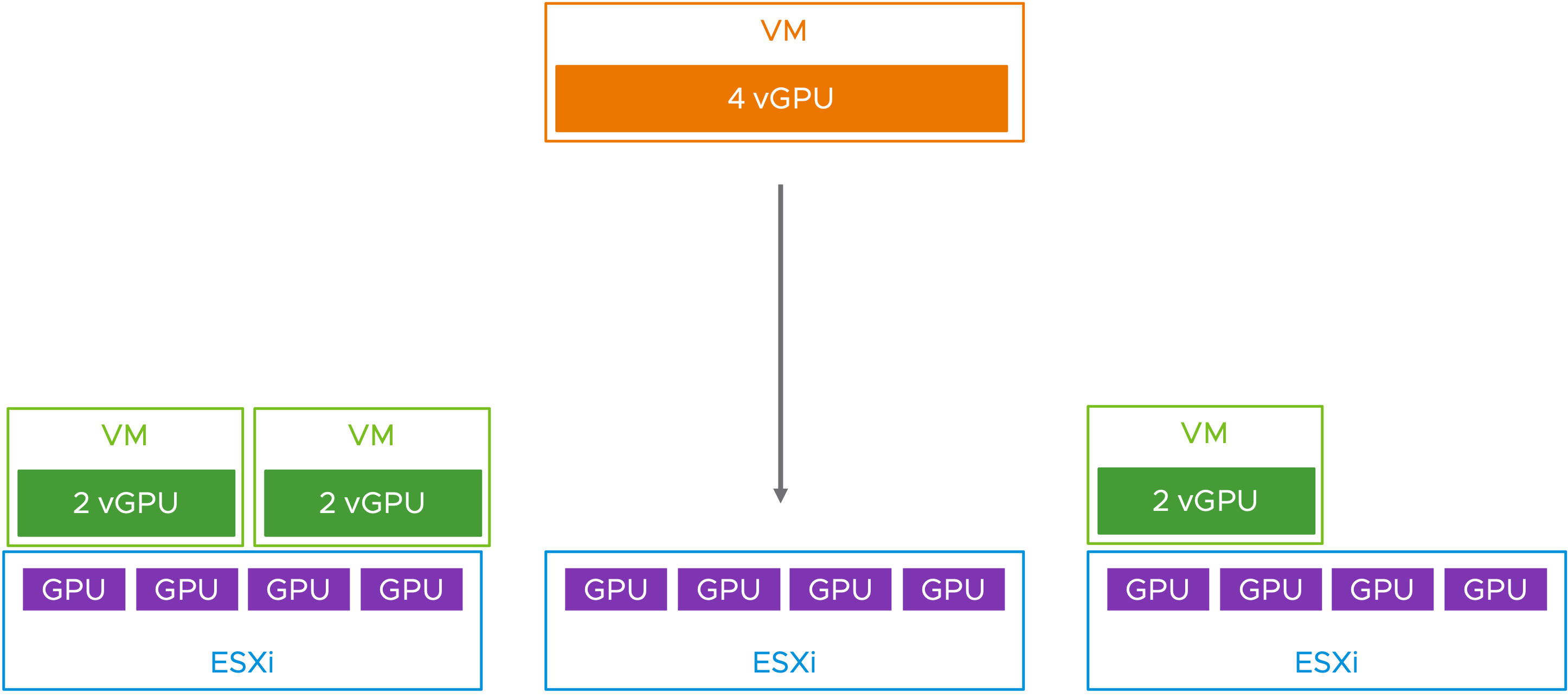
그림 5: 전체 프로필 4개의 vGPU VM이 호스트에 성공적으로 할당됨
이제 이 VM 통합 옵션을 사용하여 GPU 하드웨어와 서버를 훨씬 더 효과적으로 활용하고 있음을 알 수 있습니다. vGPU 프로필로 표시되는 하나 이상의 전체 GPU가 다양한 크기의 VM에 필요한 상황의 경우, 이 새로운 통합 옵션은 GPU 하드웨어 리소스를 최대한 활용하려는 사용자에게 매우 유용합니다.




2 comments
안녕하세요 강사님 항상 잘보고 있습니다.
vSAN 교육을 들었었는데 그때 강사님 메일 주소를 받지 못했네요
메일 주소를 알려 주실 수 있을까요?
댓글 정보만으로 어느 분인지 확인안됩니다.
여기에 제 이메일 주소를 적기는 좀 그렇구요.
학원에 물어보시면 알려주실겁니다.