
Proxmox VE 매뉴얼을 Google Translate로 기계번역하고, 살짝 교정했습니다.
https://pve.proxmox.com/pve-docs/pve-admin-guide.html
version 8.1.4, Wed Mar 6 18:21:39 CET 2024
QEMU(Quick Emulator의 약어)는 물리적 컴퓨터를 에뮬레이션하는 오픈 소스 하이퍼바이저입니다. QEMU가 실행되는 호스트 시스템의 관점에서 볼 때, QEMU는 파티션, 파일, 네트워크 카드와 같은 여러 로컬 리소스에 액세스할 수 있는 사용자 프로그램이며, 이러한 리소스는 마치 실제 장치인 것처럼 에뮬레이트된 컴퓨터로 전달됩니다. .
에뮬레이트된 컴퓨터에서 실행되는 게스트 운영 체제는 이러한 장치에 액세스하고 실제 하드웨어에서 실행되는 것처럼 실행됩니다. 예를 들어, ISO 이미지를 QEMU에 매개변수로 전달할 수 있으며, 에뮬레이트된 컴퓨터에서 실행 중인 OS는 CD 드라이브에 삽입된 실제 CD-ROM을 보게 됩니다.
QEMU는 ARM에서 Sparc까지 다양한 하드웨어를 에뮬레이션할 수 있지만 Proxmox VE는 서버 하드웨어의 압도적인 대다수를 차지하므로 32비트 및 64비트 PC 클론 에뮬레이션에만 관련됩니다. PC 클론의 에뮬레이션은 에뮬레이트된 아키텍처가 호스트 아키텍처와 동일할 때 QEMU 속도를 크게 높이는 프로세서 확장의 가용성으로 인해 가장 빠른 것 중 하나입니다.
참고: 때때로 KVM(커널 기반 가상 머신)이라는 용어가 나타날 수 있습니다. 이는 QEMU가 Linux KVM 모듈을 통해 가상화 프로세서 확장을 지원하여 실행되고 있음을 의미합니다. Proxmox VE의 맥락에서 QEMU와 KVM은 상호 교환적으로 사용될 수 있습니다. Proxmox VE의 QEMU는 항상 KVM 모듈을 로드하려고 시도하기 때문입니다.
Proxmox VE 내부의 QEMU는 블록 및 PCI 장치에 액세스하는 데 필요하므로 루트 프로세스로 실행됩니다.
10.1. 에뮬레이트된 장치 및 반가상화 장치
QEMU가 에뮬레이션한 PC 하드웨어에는 마더보드, 네트워크 컨트롤러, SCSI, IDE 및 SATA 컨트롤러, 직렬 포트(전체 목록은 kvm(1) 매뉴얼 페이지에서 볼 수 있음)가 포함되며 모두 소프트웨어로 에뮬레이트됩니다. 이러한 모든 장치는 기존 하드웨어 장치와 정확히 동일한 소프트웨어이며, 게스트에서 실행 중인 OS에 적절한 드라이버가 있는 경우 실제 하드웨어에서 실행되는 것처럼 장치를 사용합니다. 이를 통해 QEMU는 수정되지 않은 운영 체제를 실행할 수 있습니다.
그러나 하드웨어에서 실행해야 하는 작업을 소프트웨어에서 실행하려면 호스트 CPU에 많은 추가 작업이 필요하므로 성능 비용이 발생합니다. 이를 완화하기 위해 QEMU는 게스트 운영 체제 반가상화 장치에 제공할 수 있으며, 여기서 게스트 OS는 QEMU 내부에서 실행 중임을 인식하고 하이퍼바이저와 협력합니다.
QEMU는 virtio 가상화 표준을 사용하므로 반가상화 일반 디스크 컨트롤러, 반가상화 네트워크 카드, 반가상화 직렬 포트, 반가상화 SCSI 컨트롤러 등을 포함하는 반가상화 virtio 장치를 제공할 수 있습니다.
팁: virtio 장치는 성능이 크게 향상되고 일반적으로 유지 관리가 더 잘되므로 가능할 때마다 사용하는 것이 좋습니다. 에뮬레이트된 IDE 컨트롤러에 비해 virtio 일반 디스크 컨트롤러를 사용하면 bonnie++(8)로 측정했을 때 순차 쓰기 처리량이 두 배로 늘어납니다. virtio 네트워크 인터페이스를 사용하면 iperf(1)로 측정했을 때 에뮬레이트된 Intel E1000 네트워크 카드 처리량의 최대 3배를 제공할 수 있습니다. [33]
10.2. 가상머신 설정
일반적으로 Proxmox VE는 가상 머신(VM)에 대해 정상적인 기본값을 선택하려고 시도합니다. 성능 저하를 초래하거나 데이터를 위험에 빠뜨릴 수 있으므로 변경하는 설정의 의미를 이해해야 합니다.
10.2.1. 일반 설정
VM의 일반 설정에는 다음이 포함됩니다.
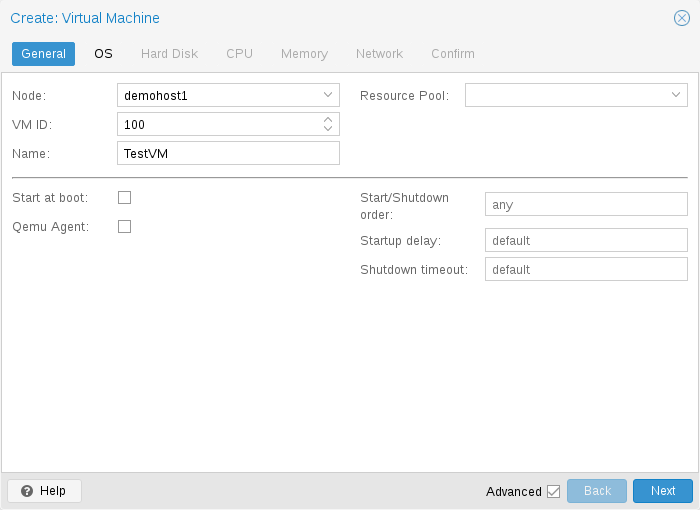
- Node: VM이 실행될 물리적 서버
- VM ID: VM을 식별하는 데 사용되는 Proxmox VE 설치의 고유 번호
- Name: VM을 설명하는 데 사용할 수 있는 자유 형식 텍스트 문자열
- Resource Pool: VM의 논리적 그룹
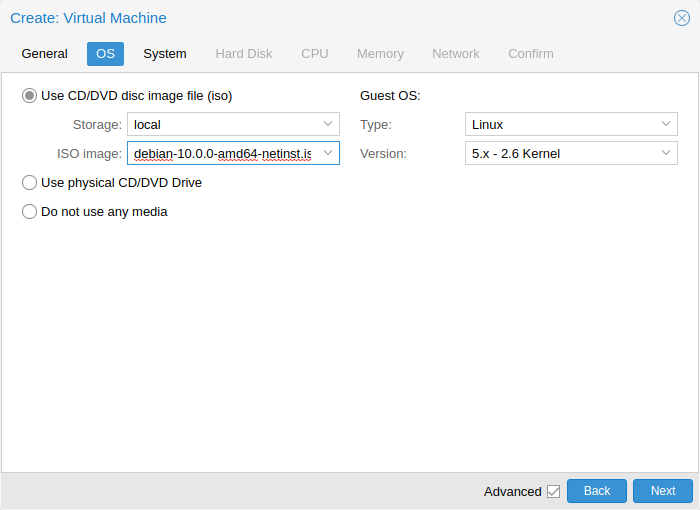
10.2.2. OS 설정
가상 머신(VM)을 생성할 때 적절한 운영 체제(OS)를 설정하면 Proxmox VE가 일부 낮은 수준의 매개 변수를 최적화할 수 있습니다. 예를 들어 Windows OS는 BIOS 시계가 현지 시간을 사용할 것으로 예상하는 반면 Unix 기반 OS는 BIOS 시계가 UTC 시간을 가질 것으로 예상합니다.
10.2.3. 환경 설정
VM 생성 시 새 VM의 일부 기본 시스템 구성 요소를 변경할 수 있습니다. 사용할 표시 유형을 지정할 수 있습니다.
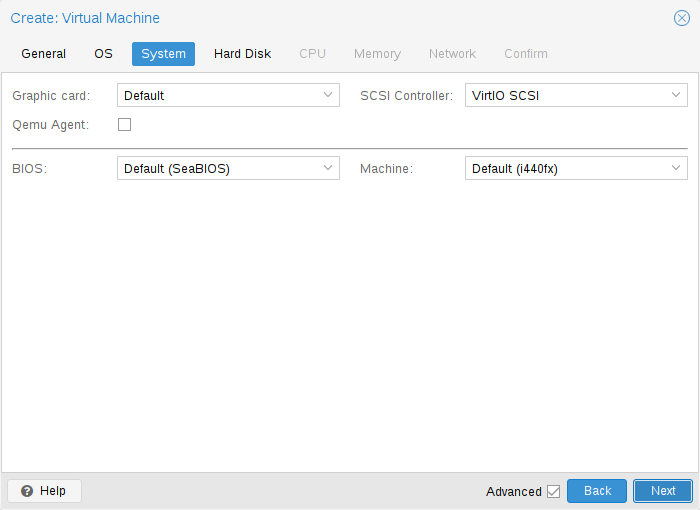
또한 SCSI 컨트롤러를 변경할 수도 있습니다. QEMU 게스트 에이전트를 설치할 계획이거나 선택한 ISO 이미지가 이미 배송되어 자동으로 설치되는 경우 QEMU 에이전트 상자를 선택하면 Proxmox VE가 해당 기능을 사용하여 추가 정보를 표시할 수 있음을 알 수 있습니다. 일부 작업(예: 종료 또는 스냅샷)을 보다 지능적으로 완료합니다.
Proxmox VE를 사용하면 SeaBIOS 및 OVMF와 같은 다양한 펌웨어 및 머신 유형을 사용하여 VM을 부팅할 수 있습니다. 대부분의 경우 PCIe 패스스루를 사용하려는 경우에만 기본 SeaBIOS에서 OVMF로 전환하려고 합니다.
Machine 유형
VM의 머신 유형은 VM의 가상 마더보드의 하드웨어 레이아웃을 정의합니다. 기본 Intel 440FX 또는 가상 PCIe 버스도 제공하는 Q35 칩셋 중에서 선택할 수 있으므로 PCIe 하드웨어를 통과하려는 경우 바람직할 수 있습니다.
Machine 버전
각 머신 유형은 QEMU에서 버전이 지정되며 특정 QEMU 바이너리는 다양한 머신 버전을 지원합니다. 새 버전에서는 새로운 기능, 수정 사항 또는 일반적인 개선 사항이 지원될 수 있습니다. 그러나 가상 하드웨어의 속성도 변경됩니다. 게스트 관점에서 갑작스러운 변화를 방지하고 VM 상태의 호환성을 보장하기 위해 실시간 마이그레이션과 RAM을 사용한 스냅샷은 새 QEMU 인스턴스에서 동일한 머신 버전을 계속 사용합니다.
Windows 게스트의 경우 Windows는 콜드 부팅 간에도 가상 하드웨어의 변경 사항에 민감하기 때문에 생성 중에 머신 버전이 고정됩니다. 예를 들어, 네트워크 장치의 열거는 시스템 버전에 따라 다를 수 있습니다. Linux와 같은 다른 OS는 일반적으로 이러한 변경 사항을 잘 처리할 수 있습니다. 이러한 경우 기본적으로 최신 머신 버전이 사용됩니다. 즉, 새로 시작한 후에는 QEMU 바이너리가 지원하는 최신 머신 버전이 사용됩니다(예: QEMU 8.1이 지원하는 최신 머신 버전은 각 머신 유형에 대해 버전 8.1입니다).
최신 컴퓨터 버전으로 업데이트
매우 오래된 머신 버전은 QEMU에서 더 이상 사용되지 않을 수 있습니다. 예를 들어 i440fx 머신 유형의 버전 1.4~1.7이 이에 해당합니다. 이러한 머신 버전에 대한 지원은 어느 시점에서 중단될 것으로 예상됩니다. 사용 중단 경고가 표시되면 머신 버전을 최신 버전으로 변경해야 합니다. 먼저 작동 중인 백업을 확보하고 게스트가 하드웨어를 보는 방식의 변경에 대비하십시오. 일부 시나리오에서는 특정 드라이버를 다시 설치해야 할 수도 있습니다. 또한 이러한 머신 버전으로 촬영된 RAM 스냅샷(예: runningmachine 구성 항목)도 확인해야 합니다. 안타깝게도 스냅샷의 머신 버전을 변경할 수 있는 방법이 없으므로 스냅샷의 데이터를 복구하려면 스냅샷을 로드해야 합니다.
10.2.4. 하드 디스크
Bus/Controller
QEMU는 다양한 스토리지 컨트롤러를 에뮬레이션할 수 있습니다.
팁: 성능상의 이유와 더 나은 유지 관리를 위해 VirtIO SCSI 또는 VirtIO Block 컨트롤러를 사용하는 것이 좋습니다.
- IDE 컨트롤러는 1984년 PC/AT 디스크 컨트롤러로 거슬러 올라가는 디자인을 가지고 있습니다. 이 컨트롤러가 최근 디자인으로 대체되더라도 여러분이 생각할 수 있는 모든 OS는 이를 지원하므로 2003년 이전에 출시된 OS를 실행하려는 경우 탁월한 선택이 됩니다. 이 컨트롤러에는 최대 4개의 장치를 연결할 수 있습니다. .
- 2003년에 출시된 SATA(Serial ATA) 컨트롤러는 더욱 현대적인 디자인을 갖추고 있어 더 높은 처리량과 더 많은 수의 장치를 연결할 수 있습니다. 이 컨트롤러에는 최대 6개의 장치를 연결할 수 있습니다.
- 1985년에 설계된 SCSI 컨트롤러는 서버급 하드웨어에서 흔히 볼 수 있으며 최대 14개의 저장 장치를 연결할 수 있습니다. Proxmox VE는 기본적으로 LSI 53C895A 컨트롤러를 에뮬레이션합니다. 성능을 목표로 한다면 VirtIO SCSI 싱글 유형의 SCSI 컨트롤러와 연결된 디스크에 대한 IO 스레드 설정을 활성화하는 것이 좋습니다. 이는 Proxmox VE 7.3 이후 새로 생성된 Linux VM의 기본값입니다. 각 디스크에는 자체 VirtIO SCSI 컨트롤러가 있으며 QEMU는 전용 스레드에서 디스크 IO를 처리합니다. Linux 배포판은 2012년부터 이 컨트롤러를 지원하고, FreeBSD는 2014년부터 지원합니다. Windows OS의 경우 설치 중에 드라이버가 포함된 추가 ISO를 제공해야 합니다.
- VirtIO 또는 virtio-blk라고도 하는 VirtIO 블록 컨트롤러는 이전 유형의 반가상화 컨트롤러입니다. 기능 측면에서 VirtIO SCSI 컨트롤러로 대체되었습니다.
Image Format
각 컨트롤러에는 구성된 스토리지에 있는 파일 또는 블록 장치로 지원되는 여러 개의 에뮬레이트된 하드 디스크를 연결합니다. 저장 유형 선택에 따라 하드 디스크 이미지의 형식이 결정됩니다. 블록 장치(LVM, ZFS, Ceph)를 제공하는 스토리지에는 원시 디스크 이미지 형식이 필요한 반면, 파일 기반 스토리지(Ext4, NFS, CIFS, GlusterFS)에서는 원시 디스크 이미지 형식 또는 QEMU 이미지 형식을 선택할 수 있습니다.
QEMU 이미지 형식은 스냅샷과 디스크 이미지의 씬 프로비저닝을 허용하는 Copy On Write 형식입니다.
원시 디스크 이미지는 Linux의 블록 장치에서 dd 명령을 실행할 때 얻는 것과 유사한 하드 디스크의 비트 간 이미지입니다. 이 형식은 씬 프로비저닝이나 스냅샷 자체를 지원하지 않으므로 이러한 작업을 위해서는 스토리지 계층의 협력이 필요합니다. 그러나 QEMU 이미지 형식보다 최대 10% 더 빠를 수 있습니다. [34]
VMware 이미지 형식은 디스크 이미지를 다른 하이퍼바이저로 가져오거나 내보내려는 경우에만 의미가 있습니다.
Cache Mode
하드 드라이브의 캐시 모드 설정은 호스트 시스템이 게스트 시스템에 블록 쓰기 완료를 알리는 방식에 영향을 미칩니다. 캐시 없음 기본값은 각 블록이 호스트 페이지 캐시를 무시하고 물리적 스토리지 쓰기 큐에 도달할 때 쓰기가 완료되었음을 게스트 시스템에 알리는 것을 의미합니다. 이는 안전과 속도 사이의 적절한 균형을 제공합니다.
VM 백업을 수행할 때 Proxmox VE 백업 관리자가 디스크를 건너뛰도록 하려면 해당 디스크에 백업 없음 옵션을 설정할 수 있습니다.
복제 작업을 시작할 때 Proxmox VE 스토리지 복제 메커니즘이 디스크를 건너뛰도록 하려면 해당 디스크에서 복제 건너뛰기 옵션을 설정할 수 있습니다. Proxmox VE 5.0부터 복제를 위해서는 디스크 이미지가 zfspool 유형의 스토리지에 있어야 하므로 VM에 복제가 구성되어 있을 때 다른 스토리지에 디스크 이미지를 추가하려면 이 디스크 이미지에 대한 복제를 건너뛰어야 합니다.
Trim/Discard
스토리지가 씬 프로비저닝을 지원하는 경우(Proxmox VE 가이드의 스토리지 장 참조) 드라이브에서 Discard 옵션을 활성화할 수 있습니다. Discard가 설정되고 TRIM 지원 게스트 OS[35]를 사용하면 VM의 파일 시스템이 파일을 삭제한 후 블록을 사용되지 않은 것으로 표시하면 컨트롤러는 이 정보를 스토리지에 전달한 다음 그에 따라 디스크 이미지를 축소합니다. 게스트가 TRIM 명령을 실행할 수 있으려면 드라이브에서 Discard 옵션을 활성화해야 합니다. 일부 게스트 운영 체제에서는 SSD 에뮬레이션 플래그를 설정해야 할 수도 있습니다. VirtIO 블록 드라이브의 폐기는 Linux 커널 5.0 이상을 사용하는 게스트에서만 지원됩니다.
드라이브를 회전식 하드 디스크가 아닌 솔리드 스테이트 드라이브로 게스트에게 표시하려면 해당 드라이브에서 SSD 에뮬레이션 옵션을 설정할 수 있습니다. 기본 스토리지가 실제로 SSD로 지원되어야 한다는 요구 사항은 없습니다. 이 기능은 모든 유형의 물리적 미디어와 함께 사용할 수 있습니다. VirtIO Block 드라이브에서는 SSD 에뮬레이션이 지원되지 않습니다.
IO Thread
옵션 IO Thread는 VirtIO 컨트롤러가 있는 디스크를 사용하거나 에뮬레이트된 컨트롤러 유형이 VirtIO SCSI 단일인 경우 SCSI 컨트롤러와 함께 디스크를 사용할 때만 사용할 수 있습니다. IO 스레드가 활성화되면 QEMU는 기본 이벤트 루프 또는 vCPU 스레드에서 모든 I/O를 처리하는 대신 스토리지 컨트롤러당 하나의 I/O 스레드를 생성합니다. 한 가지 이점은 기본 스토리지의 작업 분산 및 활용도가 향상된다는 것입니다. 또 다른 이점은 I/O 집약적인 호스트 워크로드에 대한 게스트의 지연 시간(중단)이 줄어든다는 점입니다. 기본 스레드나 vCPU 스레드 모두 디스크 I/O로 차단될 수 없기 때문입니다.
10.2.5. CPU
CPU 소켓은 CPU를 연결할 수 있는 PC 마더보드의 물리적 슬롯입니다. 그러면 이 CPU에는 독립적인 처리 장치인 하나 이상의 코어가 포함될 수 있습니다. 4개의 코어가 있는 단일 CPU 소켓이 있는지, 아니면 2개의 코어가 있는 2개의 CPU 소켓이 있는지는 성능 관점에서 거의 관련이 없습니다. 그러나 일부 소프트웨어 라이선스는 컴퓨터에 있는 소켓 수에 따라 달라지므로, 이 경우 라이선스에서 허용하는 소켓 수를 설정하는 것이 좋습니다.
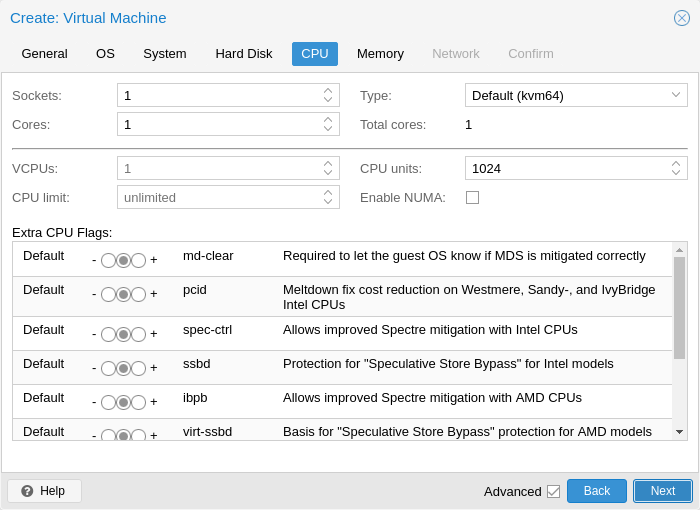
가상 CPU(코어 및 소켓) 수를 늘리면 일반적으로 VM 사용에 따라 크게 달라지지만 성능이 향상됩니다. 멀티스레드 애플리케이션은 물론 많은 가상 CPU의 이점을 누릴 수 있습니다. 추가하는 각 가상 CPU에 대해 QEMU는 호스트 시스템에서 새로운 실행 스레드를 생성하기 때문입니다. VM의 워크로드가 확실하지 않은 경우 일반적으로 총 코어 수를 2로 설정하는 것이 안전합니다.
참고: 모든 VM의 전체 코어 수가 서버의 코어 수보다 크면 완전히 안전합니다(예: 코어가 8개만 있는 머신에 각각 4개의 코어가 있는 4개의 VM(= 총 16개)). 이 경우 호스트 시스템은 마치 표준 멀티스레드 애플리케이션을 실행하는 것처럼 서버 코어 간에 QEMU 실행 스레드의 균형을 유지합니다. 그러나 Proxmox VE는 물리적으로 사용 가능한 것보다 더 많은 가상 CPU 코어로 VM을 시작하는 것을 방지합니다. 이는 컨텍스트 전환 비용으로 인해 성능이 저하되기 때문입니다.
# qm set <vmid> -vga <displaytype>,clipboard=vnc
자원 제한
cpulimit
가상 코어 수 외에도 VM에 사용 가능한 총 “Host CPU Time”은 cpulimit 옵션을 사용하여 설정할 수 있습니다. CPU 시간을 백분율로 나타내는 부동 소수점 값이므로 1.0은 100%, 2.5~250% 등입니다. 단일 프로세스가 하나의 단일 코어를 완전히 사용하는 경우 CPU 시간 사용량은 100%입니다. 4개의 코어가 있는 VM이 모든 코어를 완전히 활용하는 경우 이론적으로 400%를 사용하게 됩니다. 실제로 QEMU는 vCPU 코어 외에 VM 주변 장치에 대한 추가 스레드를 가질 수 있으므로 사용량이 조금 더 높을 수 있습니다.
이 설정은 VM이 일부 프로세스를 병렬로 실행하기 때문에 여러 vCPU가 있어야 하지만 VM 전체가 모든 vCPU를 동시에 100% 실행할 수 없어야 하는 경우에 유용할 수 있습니다.
예를 들어 8개의 가상 CPU를 사용하면 이점을 얻을 수 있는 가상 머신이 있지만 VM이 전체 로드에서 실행되는 8개의 코어를 모두 최대화하는 것을 원하지 않는다고 가정해 보겠습니다. 그렇게 하면 서버에 과부하가 걸리고 다른 가상 CPU가 남게 되기 때문입니다. CPU 시간이 너무 적은 기계와 컨테이너. 이 문제를 해결하려면 cpulimit를 4.0(=400%)으로 설정하면 됩니다. 즉, VM이 8개의 프로세스를 동시에 실행하여 8개의 가상 CPU를 모두 활용하는 경우 각 vCPU는 물리적 코어에서 최대 50% CPU 시간을 받게 됩니다. 그러나 VM 워크로드가 4개의 가상 CPU만 완전히 활용하는 경우에도 물리적 코어에서 최대 100%, 총 400%의 CPU 시간을 받을 수 있습니다.
참고: VM은 해당 구성에 따라 네트워킹 또는 IO 작업뿐만 아니라 실시간 마이그레이션과 같은 추가 스레드를 사용할 수 있습니다. 따라서 VM은 가상 CPU가 사용할 수 있는 것보다 더 많은 CPU 시간을 사용하는 것으로 나타날 수 있습니다. VM이 할당된 vCPU보다 더 많은 CPU 시간을 사용하지 않도록 하려면 cpulimit를 총 코어 수와 동일한 값으로 설정합니다.
CPUUNTIS
요즘에는 CPU 공유 또는 CPU 가중치라고도 하는 cpuunits 옵션을 사용하면 실행 중인 다른 VM과 비교하여 VM이 얻는 CPU 시간을 제어할 수 있습니다. 기본값은 100(또는 호스트가 레거시 cgroup v1을 사용하는 경우 1024)인 상대 가중치입니다. VM에 대해 이 값을 늘리면 가중치가 더 낮은 다른 VM과 비교하여 스케줄러에 의해 우선 순위가 지정됩니다.
예를 들어 VM 100이 기본값을 100으로 설정하고 VM 200이 200으로 변경된 경우 후자의 VM 200은 첫 번째 VM 100보다 두 배의 CPU 대역폭을 받게 됩니다.
자세한 내용은 man systemd.resource-control을 참조하세요. 여기서 CPUQuota는 cpulimits에 해당하고 CPUWeight는 cpuunits 설정에 해당합니다. 참조 및 구현 세부정보를 보려면 참고 섹션을 방문하세요.
affinity
선호도 옵션을 사용하면 VM의 vCPU를 실행하는 데 사용되는 물리적 CPU 코어를 지정할 수 있습니다. I/O 프로세스와 같은 주변 VM 프로세스는 이 설정의 영향을 받지 않습니다. CPU 선호도는 보안 기능이 아닙니다.
CPU 선호도를 강제하는 것은 특정 경우에 적합할 수 있지만 복잡성과 유지 관리 노력이 증가합니다. 예를 들어 나중에 VM을 더 추가하거나 CPU 코어가 더 적은 노드로 VM을 마이그레이션하려는 경우입니다. 또한 일부 CPU는 완전히 활용되고 다른 CPU는 거의 유휴 상태인 경우 쉽게 비동기화되어 시스템 성능이 제한될 수 있습니다.
선호도는 taskset CLI 도구를 통해 설정됩니다. man cpuset의 List Format으로 호스트 CPU 번호(lscpu 참조)를 허용합니다. 이 ASCII 십진수 목록에는 숫자뿐만 아니라 숫자 범위도 포함될 수 있습니다. 예를 들어 affinity 0-1,8-11(0, 1, 8, 9, 10, 11로 확장됨)을 사용하면 VM이 이러한 6개의 특정 호스트 코어에서만 실행될 수 있습니다.
CPU 유형
QEMU는 486부터 최신 Xeon 프로세서까지 다양한 CPU 유형을 에뮬레이션할 수 있습니다. 각각의 새로운 프로세서 세대에는 하드웨어 지원 3D 렌더링, 난수 생성, 메모리 보호 등과 같은 새로운 기능이 추가됩니다. 또한 버그 또는 보안 수정 사항이 포함된 마이크로코드 업데이트를 통해 현재 세대를 업그레이드할 수 있습니다.
일반적으로 VM에 대해 호스트 시스템의 CPU와 거의 일치하는 프로세서 유형을 선택해야 합니다. 이는 호스트 CPU 기능(CPU 플래그라고도 함)을 VM에서 사용할 수 있음을 의미합니다. 정확하게 일치하려는 경우 CPU 유형을 호스트로 설정할 수 있습니다. 이 경우 VM은 호스트 시스템과 정확히 동일한 CPU 플래그를 갖게 됩니다.
하지만 여기에는 단점이 있습니다. 서로 다른 호스트 간에 VM의 실시간 마이그레이션을 수행하려는 경우 VM은 CPU 유형이나 마이크로코드 버전이 다른 새 시스템에 있을 수 있습니다. 게스트에 전달된 CPU 플래그가 누락되면 QEMU 프로세스가 중지됩니다. 이 QEMU에는 이 문제를 해결하기 위해 Proxmox VE가 기본적으로 사용하는 자체 가상 CPU 유형도 있습니다.
백엔드 기본값은 기본적으로 모든 x86_64 호스트 CPU에서 작동하는 kvm64이고 새 VM을 생성할 때 UI 기본값은 x86-64-v2-AES입니다. 이를 위해서는 Intel의 경우 Westmere에서 시작하는 호스트 CPU 또는 AMD의 경우 최소 4세대 Opteron이 필요합니다. .
간단히 말해서:
실시간 마이그레이션에 관심이 없거나 모든 노드가 동일한 CPU 및 동일한 마이크로코드 버전을 갖는 동종 클러스터가 있는 경우 이론상으로는 게스트에게 최대 성능을 제공하므로 CPU 유형을 호스트로 설정하십시오.
실시간 마이그레이션 및 보안에 관심이 있고 Intel CPU만 있거나 AMD CPU만 있는 경우 클러스터의 가장 낮은 세대 CPU 모델을 선택하십시오.
보안 없이 실시간 마이그레이션을 고려하거나 Intel/AMD 클러스터가 혼합된 경우 호환 가능한 가장 낮은 가상 QEMU CPU 유형을 선택하세요.
참고: Intel과 AMD 호스트 CPU 간의 실시간 마이그레이션은 작동을 보장하지 않습니다.
QEMU에 정의된 AMD 및 Intel CPU 유형 목록도 참조하세요.
QEMU CPU 유형
QEMU는 또한 Intel 및 AMD 호스트 CPU와 호환되는 가상 CPU 유형을 제공합니다.
참고: 가상 CPU 유형에 대한 스펙터 취약성을 완화하려면 관련 CPU 플래그를 추가해야 합니다. 멜트다운/스펙터 관련 CPU 플래그를 참조하세요.
역사적으로 Proxmox VE에는 Pentium 4 수준의 CPU 플래그가 활성화된 kvm64 CPU 모델이 있었기 때문에 특정 워크로드에서는 성능이 좋지 않았습니다.
2020년 여름, AMD, Intel, Red Hat 및 SUSE는 협력하여 x86-64 기준 위에 최신 플래그를 활성화하여 세 가지 x86-64 마이크로아키텍처 수준을 정의했습니다. 자세한 내용은 x86-64-ABI 사양을 참조하세요.
참고: CentOS 9와 같은 일부 최신 배포판은 이제 x86-64-v2 플래그를 최소 요구 사항으로 사용하여 구축되었습니다.
- kvm64(x86-64-v1): Intel CPU >= Pentium 4, AMD CPU >= Phenom과 호환됩니다.
- x86-64-v2: Intel CPU >= Nehalem, AMD CPU >= Opteron_G3과 호환됩니다. x86-64-v1과 비교하여 CPU 플래그를 추가했습니다: +cx16, +lahf-lm, +popcnt, +pni, +sse4.1, +sse4.2, +ssse3.
- x86-64-v2-AES: Intel CPU >= Westmere, AMD CPU >= Opteron_G4와 호환됩니다. x86-64-v2와 비교하여 CPU 플래그를 추가했습니다: +aes.
- x86-64-v3: Intel CPU >= Broadwell, AMD CPU >= EPYC와 호환됩니다. x86-64-v2-AES와 비교하여 CPU 플래그를 추가했습니다: +avx, +avx2, +bmi1, +bmi2, +f16c, +fma, +movbe, +xsave.
- x86-64-v4: Intel CPU >= Skylake, AMD CPU >= EPYC v4 Genoa와 호환됩니다. x86-64-v3과 비교하여 CPU 플래그를 추가했습니다: +avx512f, +avx512bw, +avx512cd, +avx512dq, +avx512vl.
사용자정의 CPU 유형
구성 가능한 기능 세트를 사용하여 사용자 정의 CPU 유형을 지정할 수 있습니다. 이는 관리자가 구성 파일 /etc/pve/virtual-guest/cpu-models.conf에서 유지 관리합니다. 형식에 대한 자세한 내용은 man cpu-models.conf를 참조하세요.
지정된 사용자 정의 유형은 /nodes에 대한 Sys.Audit 권한이 있는 모든 사용자가 선택할 수 있습니다. CLI 또는 API를 통해 VM에 대한 사용자 지정 CPU 유형을 구성하는 경우 이름 앞에 custom-이 붙어야 합니다.
멜트다운/스펙터 관련 CPU 플래그
Meltdown 및 Spectre 취약점[36]과 관련된 몇 가지 CPU 플래그가 있으며, VM의 선택한 CPU 유형이 이미 기본적으로 활성화되어 있지 않는 한 수동으로 설정해야 합니다.
이러한 CPU 플래그를 사용하려면 두 가지 요구 사항을 충족해야 합니다.
- 호스트 CPU는 이 기능을 지원하고 이를 게스트의 가상 CPU에 전파해야 합니다.
- 게스트 운영 체제는 공격을 완화하고 CPU 기능을 활용할 수 있는 버전으로 업데이트되어야 합니다.
그렇지 않으면 웹 UI에서 CPU 옵션을 편집하거나 VM 구성 파일에서 CPU 옵션의 플래그 속성을 설정하여 가상 CPU의 원하는 CPU 플래그를 설정해야 합니다.
Spectre v1,v2,v4 수정 사항의 경우 CPU 또는 시스템 공급업체가 CPU에 대한 소위 “마이크로코드 업데이트”도 제공해야 합니다. 펌웨어 업데이트 장을 참조하세요. 영향을 받는 모든 CPU를 spec-ctrl을 지원하도록 업데이트할 수 있는 것은 아닙니다.
Proxmox VE 호스트가 취약한지 확인하려면 root로 다음 명령을 실행하십시오.
for f in /sys/devices/system/cpu/vulnerabilities/*; do echo "${f##*/} -" $(cat "$f"); done호스트가 여전히 취약한지 감지하기 위해 커뮤니티 스크립트도 사용할 수 있습니다. [37]
인텔 프로세서
- pcid: 이는 사용자 공간에서 커널 메모리를 효과적으로 숨기는 KPTI(커널 페이지 테이블 격리)라는 멜트다운(CVE-2017-5754) 완화의 성능 영향을 줄입니다. PCID가 없으면 KPTI는 상당히 비싼 메커니즘입니다[38].
Proxmox VE 호스트가 PCID를 지원하는지 확인하려면 루트로 다음 명령을 실행하십시오.
# grep ' pcid ' /proc/cpuinfo
이것이 빈 값으로 반환되지 않으면 호스트의 CPU가 pcid를 지원합니다.
- spec-ctrl
리트폴린(retpoline)이 충분하지 않은 경우 Spectre v1(CVE-2017-5753) 및 Spectre v2(CVE-2017-5715) 수정 사항을 활성화하는 데 필요합니다. -IBRS 접미사가 있는 Intel CPU 모델에는 기본적으로 포함됩니다. -IBRS 접미사가 없는 Intel CPU 모델의 경우 명시적으로 켜져야 합니다. 업데이트된 호스트 CPU 마이크로코드(intel-microcode >= 20180425)가 필요합니다. - ssbd
Spectre V4(CVE-2018-3639) 수정 사항을 활성화하는 데 필요합니다. 모든 Intel CPU 모델에는 기본적으로 포함되어 있지 않습니다. 모든 Intel CPU 모델에 대해 명시적으로 켜져 있어야 합니다. 업데이트된 호스트 CPU 마이크로코드(intel-microcode >= 20180703)가 필요합니다.
AMD 프로세서
ibpb
리트폴린이 충분하지 않은 경우 Spectre v1(CVE-2017-5753) 및 Spectre v2(CVE-2017-5715) 수정 사항을 활성화하는 데 필요합니다. -IBPB 접미사가 있는 AMD CPU 모델에는 기본적으로 포함됩니다. -IBPB 접미사가 없는 AMD CPU 모델의 경우 명시적으로 켜져야 합니다. 게스트 CPU에 사용하려면 먼저 이 기능을 지원하는 호스트 CPU 마이크로코드가 필요합니다.
virt-ssbd
Spectre v4(CVE-2018-3639) 수정 사항을 활성화하는 데 필요합니다. 모든 AMD CPU 모델에는 기본적으로 포함되어 있지 않습니다. 모든 AMD CPU 모델에 대해 명시적으로 켜져 있어야 합니다. 최대 게스트 호환성을 위해 amd-ssbd도 제공되는 경우에도 이는 게스트에게 제공되어야 합니다. 이는 “host” CPU 모델을 사용할 때 명시적으로 활성화해야 합니다. 이는 물리적 CPU에 존재하지 않는 가상 기능이기 때문입니다.
amd-ssbd
Spectre v4(CVE-2018-3639) 수정 사항을 활성화하는 데 필요합니다. 모든 AMD CPU 모델에는 기본적으로 포함되어 있지 않습니다. 모든 AMD CPU 모델에 대해 명시적으로 켜져 있어야 합니다. 이는 virt-ssbd보다 더 높은 성능을 제공하므로 이를 지원하는 호스트는 가능하면 항상 이를 게스트에게 노출해야 합니다. 그럼에도 불구하고 일부 커널은 virt-ssbd에 대해서만 알고 있으므로 최대 게스트 호환성을 위해 virt-ssbd도 노출되어야 합니다.
amd-no-ssb
호스트가 Spectre V4(CVE-2018-3639)에 취약하지 않음을 나타내는 것이 좋습니다. 모든 AMD CPU 모델에는 기본적으로 포함되어 있지 않습니다. CPU의 향후 하드웨어 세대는 CVE-2018-3639에 취약하지 않으므로 amd-no-ssb를 노출하여 완화 기능을 활성화하지 말라고 게스트에게 알려야 합니다. 이는 virt-ssbd 및 amd-ssbd와 상호 배타적입니다.
NUMA
또한 선택적으로 VM에서 NUMA [39] 아키텍처를 에뮬레이트할 수도 있습니다. NUMA 아키텍처의 기본은 모든 코어에서 사용할 수 있는 전역 메모리 풀을 갖는 대신 메모리가 각 소켓에 가까운 로컬 뱅크로 분산된다는 것을 의미합니다. 메모리 버스가 더 이상 병목 현상을 일으키지 않으므로 속도가 향상될 수 있습니다. 시스템에 NUMA 아키텍처[40]가 있는 경우 옵션을 활성화하는 것이 좋습니다. 이렇게 하면 호스트 시스템에서 VM 리소스를 적절하게 배포할 수 있습니다. 이 옵션은 VM에서 코어 또는 RAM을 핫플러그하는 데에도 필요합니다.
NUMA 옵션을 사용하는 경우 소켓 수를 호스트 시스템의 노드 수로 설정하는 것이 좋습니다.
vCPU 핫플러그
최신 운영 체제에서는 실행 중인 시스템에 CPU를 핫플러그하고 어느 정도 핫언플러그하는 기능을 도입했습니다. 가상화를 사용하면 이러한 시나리오에서 실제 하드웨어가 일으킬 수 있는 많은 (물리적) 문제를 피할 수 있습니다. 하지만 이는 다소 새롭고 복잡한 기능이므로 반드시 필요한 경우에만 사용을 제한해야 합니다. 대부분의 기능은 잘 테스트되고 덜 복잡한 다른 기능으로 복제될 수 있습니다. 리소스 제한을 참조하세요.
Proxmox VE에서 연결된 CPU의 최대 수는 항상 cores * sockets입니다. 이 총 코어 수보다 적은 CPU 코어 수로 VM을 시작하려면 vcpus 설정을 사용할 수 있습니다. 이는 VM 시작 시 몇 개의 vCPU를 연결해야 하는지를 나타냅니다.
현재 이 기능은 Linux에서만 지원되며 3.10보다 최신 커널이 필요하며 4.7보다 최신 커널이 권장됩니다.
다음과 같이 udev 규칙을 사용하여 게스트에서 새 CPU를 온라인으로 자동 설정할 수 있습니다.
SUBSYSTEM=="cpu", ACTION=="add", TEST=="online", ATTR{online}=="0", ATTR{online}="1"이를 /etc/udev/rules.d/에 .rules로 끝나는 파일로 저장합니다.
참고: CPU 핫 제거는 시스템에 따라 다르며 게스트의 협력이 필요합니다. 삭제 명령은 CPU 제거가 실제로 발생한다고 보장하지 않습니다. 일반적으로 이는 x86/amd64의 ACPI와 같은 대상 종속 메커니즘을 사용하여 게스트 OS로 전달되는 요청입니다.
10.2.6. 메모리
각 VM에 대해 고정된 크기의 메모리를 설정하거나 Proxmox VE에 호스트의 현재 RAM 사용량에 따라 메모리를 동적으로 할당하도록 요청할 수 있는 옵션이 있습니다.
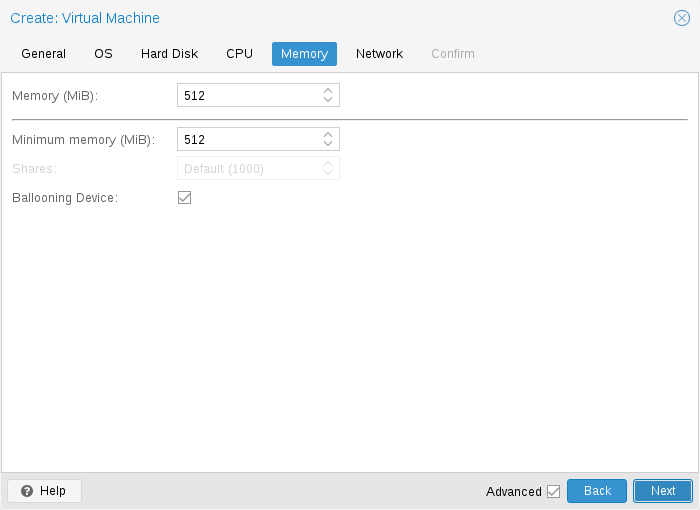
고정 메모리 할당
메모리와 최소 메모리를 동일한 양으로 설정하면 Proxmox VE는 사용자가 지정한 것을 VM에 할당합니다.
고정된 메모리 크기를 사용하는 경우에도 풍선 장치는 게스트가 실제로 사용하는 메모리 양과 같은 유용한 정보를 제공하기 때문에 VM에 추가됩니다. 일반적으로 ballooning은 활성화된 상태로 두어야 하지만, 디버깅 목적 등으로 비활성화하려면 Ballooning Device를 선택 취소하거나 설정하면 됩니다.
balloon: 0
구성에서.
자동 메모리 할당
최소 메모리를 메모리보다 낮게 설정하면 Proxmox VE는 지정한 최소 용량을 VM에서 항상 사용할 수 있는지 확인하고, 호스트의 RAM 사용량이 80% 미만인 경우 게스트에 최대 메모리까지 동적으로 추가합니다.
호스트의 RAM이 부족하면 VM은 일부 메모리를 호스트에 다시 릴리스하고 필요한 경우 실행 중인 프로세스를 교체하고 최후의 수단으로 oom killer를 시작합니다. 호스트와 게스트 간의 메모리 전달은 게스트 내부에서 실행되는 특수 balloon 커널 드라이버를 통해 수행되며, 이 드라이버는 호스트에서 메모리 페이지를 가져오거나 해제합니다. [41]
여러 VM이 자동 할당 기능을 사용하는 경우 각 VM이 차지해야 하는 여유 호스트 메모리의 상대적인 양을 나타내는 Shares 계수를 설정할 수 있습니다. 예를 들어 4개의 VM이 있고 그 중 3개는 HTTP 서버를 실행하고 마지막 하나는 데이터베이스 서버라고 가정해 보겠습니다. 데이터베이스 서버 RAM에 더 많은 데이터베이스 블록을 캐시하려면 예비 RAM을 사용할 수 있을 때 데이터베이스 VM의 우선순위를 지정하려고 합니다. 이를 위해 데이터베이스 VM에 공유 속성 3000을 할당하고 다른 VM은 공유 기본 설정인 1000으로 둡니다. 호스트 서버에는 32GB RAM이 있으며 현재 16GB를 사용하고 있으므로 32 * 80/100 – 16 = 9GB가 남습니다. 구성된 최소 메모리 양 외에 VM에 할당할 RAM입니다. 데이터베이스 VM은 9 * 3000 / (3000 + 1000 + 1000 + 1000) = 4.5GB 추가 RAM 및 각 HTTP 서버는 1.5GB.
2010년 이후에 출시된 모든 Linux 배포판에는 balloon 커널 드라이버가 포함되어 있습니다. Windows OS의 경우 벌룬 드라이버를 수동으로 추가해야 하며 게스트 속도가 느려질 수 있으므로 중요한 시스템에서는 사용하지 않는 것이 좋습니다.
VM에 RAM을 할당할 때 가장 좋은 방법은 항상 호스트에서 사용할 수 있는 RAM 1GB를 남겨 두는 것입니다.
10.2.7. 네트워크 장치
각 VM에는 다음 네 가지 유형의 여러 네트워크 인터페이스 컨트롤러(NIC)가 있을 수 있습니다.
https://pve.proxmox.com/pve-docs/images/screenshot/gui-create-vm-network.png
- Intel E1000이 기본값이며 Intel 기가비트 네트워크 카드를 에뮬레이트합니다.
- 최대 성능을 목표로 한다면 VirtIO 반가상화 NIC를 사용해야 합니다. 모든 VirtIO 장치와 마찬가지로 게스트 OS에도 적절한 드라이버가 설치되어 있어야 합니다.
- Realtek 8139는 이전 100MB/s 네트워크 카드를 에뮬레이트하므로 이전 운영 체제(2002년 이전에 출시됨)를 에뮬레이션할 때만 사용해야 합니다.
- vmxnet3은 또 다른 반가상화 장치로, 다른 하이퍼바이저에서 VM을 가져올 때만 사용해야 합니다.
Proxmox VE는 각 NIC에 대해 임의의 MAC 주소를 생성하므로 VM은 이더넷 네트워크에서 주소를 지정할 수 있습니다.
VM에 추가한 NIC는 두 가지 모델 중 하나를 따를 수 있습니다.
- 기본 Bridged mode에서 각 가상 NIC는 탭 장치(이더넷 NIC를 시뮬레이션하는 소프트웨어 루프백 장치)에 의해 호스트에서 지원됩니다. 이 탭 장치는 Proxmox VE의 기본적으로 vmbr0 브리지에 추가됩니다. 이 모드에서는 VM이 호스트가 있는 이더넷 LAN에 직접 액세스할 수 있습니다.
- 대체 NAT mode에서 각 가상 NIC는 내장 라우터와 DHCP 서버가 네트워크 액세스를 제공할 수 있는 QEMU 사용자 네트워킹 스택하고만 통신합니다. 이 내장 DHCP는 개인 10.0.2.0/24 범위의 주소를 제공합니다. NAT 모드는 브리지 모드보다 훨씬 느리므로 테스트용으로만 사용해야 합니다. 이 모드는 CLI 또는 API를 통해서만 사용할 수 있으며 웹 UI를 통해서는 사용할 수 없습니다.
No network device을 선택하여 VM을 생성할 때 네트워크 장치 추가를 건너뛸 수도 있습니다.
각 VM 네트워크 장치의 MTU 설정을 덮어쓸 수 있습니다. mtu=1 옵션은 MTU 값이 기본 브리지에서 상속되는 특별한 경우를 나타냅니다. 이 옵션은 VirtIO 네트워크 장치에만 사용할 수 있습니다.
다중 대기열
VirtIO 드라이버를 사용하는 경우 선택적으로 Multiqueue 옵션을 활성화할 수 있습니다. 이 옵션을 사용하면 게스트 OS가 여러 가상 CPU를 사용하여 네트워킹 패킷을 처리할 수 있으므로 전송되는 총 패킷 수가 늘어납니다.
Proxmox VE와 함께 VirtIO 드라이버를 사용할 때 각 NIC 네트워크 대기열은 호스트 커널로 전달되며, 여기서 대기열은 vhost 드라이버에 의해 생성된 커널 스레드에 의해 처리됩니다. 이 옵션을 활성화하면 각 NIC의 호스트 커널에 여러 네트워크 대기열을 전달할 수 있습니다.
Multiqueue를 사용하는 경우 게스트의 총 코어 수와 동일한 값으로 설정하는 것이 좋습니다. 또한 ethtool 명령을 사용하여 VM에서 각 VirtIO NIC의 다목적 채널 수를 설정해야 합니다.
ethtool -L ens1 combined X
여기서 X는 VM의 vcpus 수입니다.
Multiqueue 매개변수를 1보다 큰 값으로 설정하면 트래픽이 증가함에 따라 호스트 및 게스트 시스템의 CPU 로드가 증가한다는 점에 유의해야 합니다. VM이 라우터, 역방향 프록시 또는 긴 폴링을 수행하는 사용량이 많은 HTTP 서버로 실행되는 경우와 같이 VM이 많은 수의 들어오는 연결을 처리해야 하는 경우에만 이 옵션을 설정하는 것이 좋습니다.
10.2.8. 디스플레이
QEMU는 몇 가지 유형의 VGA 하드웨어를 가상화할 수 있습니다. 몇 가지 예는 다음과 같습니다:
- 기본값인 std는 Bochs VBE 확장 기능이 있는 카드를 에뮬레이트합니다.
- cirrus, 이것은 한때 기본값이었으며 모든 문제가 있는 아주 오래된 하드웨어 모듈을 에뮬레이션합니다. 이 디스플레이 유형은 실제로 필요한 경우에만 사용해야 합니다[42]. 예를 들어 Windows XP 또는 이전 버전을 사용하는 경우
- vmware는 VMWare SVGA-II 호환 어댑터입니다.
- qxl은 QXL 반가상화 그래픽 카드입니다. 이를 선택하면 VM에 대한 SPICE(원격 뷰어 프로토콜)도 활성화됩니다.
- virtio-gl(흔히 VirGL이라고 함)은 VM 내부에서 사용하기 위한 가상 3D GPU로, 특별한(비싼) 모델과 드라이버가 필요하지 않고 호스트 GPU에 워크로드를 오프로드할 수 있으며 호스트 GPU를 완전히 바인딩하지 않아도 되므로 여러 게스트 및/또는 호스트 간에 재사용이 가능합니다. .
참고: VirGL 지원에는 상대적으로 크고 모든 GPU 모델/공급업체에 대한 오픈 소스로 사용할 수 없기 때문에 기본적으로 설치되지 않는 몇 가지 추가 라이브러리가 필요합니다. 대부분의 설정에서는 다음과 같이 하면 됩니다: apt install libgl1 libegl1
메모리 옵션을 설정하여 가상 GPU에 제공되는 메모리 양을 편집할 수 있습니다. 이를 통해 특히 SPICE/QXL을 사용하여 VM 내부에서 더 높은 해상도를 구현할 수 있습니다.
메모리는 디스플레이 장치에 의해 예약되므로 SPICE(예: 듀얼 모니터의 경우 qxl2)에 대해 다중 모니터 모드를 선택하면 다음과 같은 의미가 있습니다.
- Windows에는 각 모니터마다 장치가 필요하므로 ostype이 일부 Windows 버전인 경우 Proxmox VE는 VM에 모니터당 추가 장치를 제공합니다. 각 장치는 지정된 양의 메모리를 갖습니다.
- Linux VM은 항상 더 많은 가상 모니터를 활성화할 수 있지만 다중 모니터 모드를 선택하면 장치에 제공되는 메모리에 모니터 수가 곱해집니다.
디스플레이 유형으로 serialX를 선택하면 VGA 출력이 비활성화되고 웹 콘솔이 선택한 직렬 포트로 리디렉션됩니다. 이 경우 구성된 디스플레이 메모리 설정은 무시됩니다.
VNC 클립보드
클립보드를 vnc로 설정하여 VNC 클립보드를 활성화할 수 있습니다.
# qm set <vmid> -vga <displaytype>,clipboard=vnc
클립보드 기능을 사용하려면 먼저 SPICE 게스트 도구를 설치해야 합니다. Debian 기반 배포판에서는 spice-vdagent를 설치하면 됩니다. 다른 운영 체제의 경우 공식 저장소에서 검색하거나 https://www.spice-space.org/download.html을 참조하세요.
SPICE 게스트 도구를 설치한 후에는 VNC 클립보드 기능(예: noVNC 콘솔 패널)을 사용할 수 있습니다. 그러나 SPICE, virtio 또는 virgl을 사용하는 경우 사용할 클립보드를 선택해야 합니다. 이는 클립보드가 vnc로 설정된 경우 기본 SPICE 클립보드가 VNC 클립보드로 대체되기 때문입니다.
10.2.9. USB 패스스루
USB 패스스루 장치에는 두 가지 유형이 있습니다.
- 호스트 USB 패스스루
- SPICE USB 패스스루
호스트 USB 패스스루는 VM에 호스트의 USB 장치를 제공하여 작동합니다. 이는 공급업체 및 제품 ID를 통해 수행하거나 호스트 버스 및 포트를 통해 수행할 수 있습니다.
공급업체/제품 ID는 다음과 같습니다: 0123:abcd. 여기서 0123은 공급업체의 ID이고 abcd는 제품의 ID입니다. 즉, 동일한 USB 장치의 두 부분이 동일한 ID를 가집니다.
버스/포트는 다음과 같습니다: 1-2.3.4. 여기서 1은 버스이고 2.3.4는 포트 경로입니다. 이는 호스트의 물리적 포트를 나타냅니다(USB 컨트롤러의 내부 순서에 따라 다름).
VM이 시작될 때 VM 구성에 장치가 있지만 호스트에는 장치가 없는 경우 VM은 문제 없이 부팅될 수 있습니다. 장치/포트가 호스트에서 사용 가능해지면 즉시 통과됩니다.
경고: 이러한 종류의 USB 패스스루를 사용하면 VM이 현재 상주하는 호스트에서만 하드웨어를 사용할 수 있으므로 VM을 온라인에서 다른 호스트로 이동할 수 없습니다.
두 번째 유형의 패스스루는 SPICE USB 패스스루입니다. 하나 이상의 SPICE USB 포트를 VM에 추가하면 SPICE 클라이언트에서 VM으로 로컬 USB 장치를 동적으로 전달할 수 있습니다. 이는 입력 장치나 하드웨어 동글을 일시적으로 리디렉션하는 데 유용할 수 있습니다.
클러스터 수준에서 장치를 매핑하여 HA와 함께 적절하게 사용할 수 있으며 하드웨어 변경 사항이 감지되고 루트가 아닌 사용자가 이를 구성할 수 있습니다. 자세한 내용은 리소스 매핑을 참조하세요.
10.2.10. BIOS 및 UEFI
컴퓨터를 제대로 에뮬레이트하려면 QEMU가 펌웨어를 사용해야 합니다. BIOS 또는 (U)EFI라고도 하는 일반 PC에서 VM을 부팅할 때 첫 번째 단계 중 하나로 실행됩니다. 기본 하드웨어 초기화를 수행하고 운영 체제용 펌웨어 및 하드웨어에 대한 인터페이스를 제공하는 역할을 담당합니다. 기본적으로 QEMU는 이를 위해 오픈 소스 x86 BIOS 구현인 SeaBIOS를 사용합니다. SeaBIOS는 대부분의 표준 설정에 적합한 선택입니다.
일부 운영 체제(예: Windows 11)에서는 UEFI 호환 구현을 사용해야 할 수도 있습니다. 이러한 경우 오픈 소스 UEFI 구현인 OVMF를 대신 사용해야 합니다. [43]
예를 들어 VGA 패스스루를 수행하려는 경우 SeaBIOS가 부팅하기에 이상적인 펌웨어가 아닐 수 있는 다른 시나리오도 있습니다. [44]
OVMF를 사용하려면 고려해야 할 몇 가지 사항이 있습니다.
부팅 순서 등을 저장하려면 EFI 디스크가 필요합니다. 이 디스크는 백업 및 스냅샷에 포함되며 하나만 있을 수 있습니다.
다음 명령을 사용하여 이러한 디스크를 만들 수 있습니다.
# qm set <vmid> -efidisk0 <storage>:1,format=<format>,efitype=4m,pre-enrolled-keys=1
여기서 는 디스크를 갖고 싶은 저장소이고, 은 저장소가 지원하는 형식입니다. 또는 VM의 하드웨어 섹션에 있는 추가 → EFI 디스크를 사용하여 웹 인터페이스를 통해 이러한 디스크를 생성할 수 있습니다.
efitype 옵션은 사용해야 하는 OVMF 펌웨어 버전을 지정합니다. 새 VM의 경우 보안 부팅을 지원하고 향후 개발을 지원하기 위해 더 많은 공간이 할당되므로 항상 4m여야 합니다(GUI의 기본값).
pre-enroll-keys는 efidisk에 배포별 키와 Microsoft 표준 보안 부팅 키가 사전 로드되어 있어야 하는지 여부를 지정합니다. 또한 기본적으로 보안 부팅을 활성화합니다(VM 내의 OVMF 메뉴에서는 여전히 비활성화할 수 있음).
참고: 기존 VM(여전히 2m efidisk를 사용함)에서 보안 부팅을 사용하려면 efidisk를 다시 생성해야 합니다. 이렇게 하려면 이전 항목을 삭제하고(qm set-delete efidisk0) 위에 설명된 대로 새 항목을 추가하세요. 이렇게 하면 OVMF 메뉴에서 만든 모든 사용자 정의 구성이 재설정됩니다!
가상 디스플레이(VGA 패스스루 없음)와 함께 OVMF를 사용하는 경우 OVMF 메뉴(부팅 중에 ESC 버튼을 눌러 접근할 수 있음)에서 클라이언트 해상도를 설정하거나 디스플레이 유형으로 SPICE를 선택해야 합니다. .
10.2.11. TPM(신뢰할 수 있는 플랫폼 모듈)
신뢰할 수 있는 플랫폼 모듈은 암호화 키와 같은 비밀 데이터를 안전하게 저장하고 시스템 부팅 유효성을 검사하기 위한 변조 방지 기능을 제공하는 장치입니다.
특정 운영 체제(예: Windows 11)에서는 이러한 장치를 머신(물리적이든 가상이든)에 연결해야 합니다.
TPM은 tpmstate 볼륨을 지정하여 추가됩니다. 이는 일단 생성되면 변경할 수 없다는(제거만 가능) 점에서 efidisk와 유사하게 작동합니다. 다음 명령을 통해 추가할 수 있습니다.
# qm set <vmid> -tpmstate0 <storage>:1,version=<version>
여기서 는 상태를 적용할 스토리지이고 은 v1.2 또는 v2.0입니다. VM의 하드웨어 섹션에서 Add → TPM State를 선택하여 웹 인터페이스를 통해 추가할 수도 있습니다.
v2.0 TPM 사양은 더 새롭고 더 잘 지원되므로 v1.2 TPM이 필요한 특정 구현이 없으면 v1.2 TPM이 선호됩니다.
참고: 물리적 TPM과 비교할 때 에뮬레이트된 TPM은 실제 보안 이점을 제공하지 않습니다. TPM의 요점은 TPM 사양의 일부로 지정된 명령을 통하지 않는 한 TPM의 데이터를 쉽게 수정할 수 없다는 것입니다. 에뮬레이트된 장치를 사용하면 데이터 저장이 일반 볼륨에 발생하므로 액세스 권한이 있는 사람이 잠재적으로 편집할 수 있습니다.
10.2.12. VM 간 공유 메모리
호스트와 게스트 간 또는 여러 게스트 간에 메모리를 공유할 수 있는 VM 간 공유 메모리 장치(ivshmem)를 추가할 수 있습니다.
이러한 장치를 추가하려면 qm을 사용할 수 있습니다.
# qm set <vmid> -ivshmem size=32,name=foo
크기는 MiB 단위입니다. 파일은 /dev/shm/pve-shm-$name(기본 이름은 vmid) 아래에 위치합니다.
참고: 현재 장치를 사용하는 VM이 종료되거나 중지되는 즉시 장치가 삭제됩니다. 열려 있는 연결은 계속 유지되지만 동일한 장치에 대한 새 연결은 더 이상 만들 수 없습니다.
이러한 장치의 사용 사례는 호스트와 게스트 간의 고성능, 낮은 대기 시간 디스플레이 미러링을 가능하게 하는 Looking Glass [45] 프로젝트입니다.
10.2.13. 오디오 장치
오디오 장치를 추가하려면 다음 명령을 실행하십시오.
qm set <vmid> -audio0 device=<device>
지원되는 오디오 장치는 다음과 같습니다.
- ich9-intel-hda: Intel HD Audio Controller, ICH9 에뮬레이션
- intel-hda: Intel HD Audio Controller, ICH6 에뮬레이션
- AC97: 오디오 코덱 ’97, Windows XP와 같은 이전 운영 체제에 유용
두 가지 백엔드를 사용할 수 있습니다.
- spice
- none
spice 백엔드는 SPICE와 함께 사용할 수 있지만, 일부 소프트웨어가 작동하기 위해 VM에 오디오 장치가 필요한 경우 none 백엔드가 유용할 수 있습니다. 호스트의 물리적 오디오 장치를 사용하려면 장치 통과를 사용합니다(PCI 통과 및 USB 통과 참조). Microsoft의 RDP와 같은 원격 프로토콜에는 사운드 재생 옵션이 있습니다.
10.2.14. VirtIO RNG
RNG(Random Number Generator)는 시스템에 엔트로피(무작위성)를 제공하는 장치입니다. 가상 하드웨어 RNG를 사용하여 호스트 시스템에서 게스트 VM으로 이러한 엔트로피를 제공할 수 있습니다. 이는 특히 게스트 부팅 프로세스 중에 게스트의 엔트로피 부족 문제(사용 가능한 엔트로피가 충분하지 않아 시스템 속도가 느려지거나 문제가 발생할 수 있는 상황)를 방지하는 데 도움이 됩니다.
VirtIO 기반 에뮬레이트된 RNG를 추가하려면 다음 명령을 실행하십시오.
qm set <vmid> -rng0 source=<source>[,max_bytes=X,period=Y]
source는 호스트에서 엔트로피를 읽는 위치를 지정하며 다음 중 하나여야 합니다.
- /dev/urandom: 비차단 커널 엔트로피 풀(선호)
- /dev/random: 커널 풀 차단(권장되지 않음, 호스트 시스템에서 엔트로피 부족으로 이어질 수 있음)
- /dev/hwrng: 호스트에 연결된 하드웨어 RNG를 통과하려면(여러 개가 사용 가능한 경우 /sys/devices/virtual/misc/hw_random/rng_current에서 선택한 것이 사용됩니다)
제한은 max_bytes 및 period 매개변수를 통해 지정할 수 있으며, 밀리초 단위로 기간당 max_bytes로 읽혀집니다. 그러나 이는 선형 관계를 나타내지 않습니다. 1024B/1000ms는 1초 타이머에 최대 1KiB의 데이터를 사용할 수 있다는 의미이지 1초 동안 1KiB가 게스트에게 스트리밍된다는 의미는 아닙니다. 따라서 기간을 줄이면 더 빠른 속도로 게스트에 엔트로피를 주입할 수 있습니다.
기본적으로 제한은 1000ms당 1024바이트(1KiB/s)로 설정됩니다. 게스트가 너무 많은 호스트 리소스를 사용하는 것을 방지하려면 항상 제한기를 사용하는 것이 좋습니다. 원하는 경우 max_bytes 값 0을 사용하여 모든 제한을 비활성화할 수 있습니다.
10.2.15. 장치 부팅 순서
QEMU는 게스트에게 어떤 장치에서 부팅해야 하는지, 어떤 순서로 부팅해야 하는지 알려줄 수 있습니다. 이는 부팅 속성을 통해 구성에서 지정할 수 있습니다. 예를 들면 다음과 같습니다.
boot: order=scsi0;net0;hostpci0
이런 방식으로 게스트는 먼저 디스크 scsi0에서 부팅을 시도하고, 실패할 경우 계속해서 net0에서 네트워크 부팅을 시도하고, 실패할 경우 마지막으로 전달된 PCIe 장치에서 부팅을 시도합니다(다음과 같이 표시됨). NVMe의 경우 디스크를 실행하고, 그렇지 않으면 옵션 ROM으로 실행을 시도합니다.
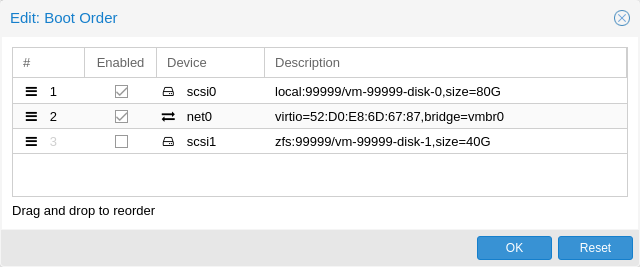
GUI에서는 끌어서 놓기 편집기를 사용하여 부팅 순서를 지정할 수 있으며, 확인란을 사용하여 부팅할 특정 장치를 활성화 또는 비활성화할 수 있습니다.
참고: 게스트가 OS를 부팅하거나 부트로더를 로드하기 위해 여러 디스크를 사용하는 경우 게스트가 다음을 수행할 수 있도록 모든 디스크를 부팅 가능으로 표시해야 합니다(즉, 확인란을 활성화하거나 구성 목록에 표시해야 함). 이는 최신 SeaBIOS 및 OVMF 버전이 부팅 가능으로 표시된 경우에만 디스크를 초기화하기 때문입니다.
어떤 경우든, 목록에 나타나지 않거나 체크 표시가 비활성화된 장치라도 운영 체제가 부팅되고 초기화되면 게스트는 계속 사용할 수 있습니다. 부팅 가능 플래그는 게스트 BIOS 및 부트로더에만 영향을 미칩니다.
10.2.16. 가상 머신의 자동 시작 및 종료
VM을 생성한 후 호스트 시스템이 부팅될 때 VM이 자동으로 시작되기를 원할 것입니다. 이를 위해서는 웹 인터페이스에 있는 VM의 옵션 탭에서 부팅 시 시작 옵션을 선택하거나 다음 명령을 사용하여 설정해야 합니다.
# qm set <vmid> -onboot 1
시작 및 종료 순서
예를 들어 VM 중 하나가 다른 게스트 시스템에 방화벽이나 DHCP를 제공하는 경우와 같이 VM의 부팅 순서를 미세 조정할 수 있는 경우도 있습니다. 이를 위해 다음 매개변수를 사용할 수 있습니다.
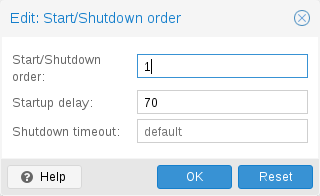
- Start/Shutdown order: 시작 순서 우선순위를 정의합니다. 예를 들어 VM을 가장 먼저 시작하려면 이 값을 1로 설정합니다. (종료에는 역방향 시작 순서를 사용하므로 시작 순서가 1인 머신이 마지막으로 종료됩니다.) 여러 VM이 호스트에 동일한 순서로 정의되어 있는 경우 추가로 VMID를 기준으로 오름차순으로 정렬됩니다.
- Startup delay: 이 VM 시작과 후속 VM 시작 사이의 간격을 정의합니다. 예를 들어 다른 VM을 시작하기 전에 240초를 기다리려면 240으로 설정합니다.
- Shutdown timeout: Proxmox VE가 종료 명령을 실행한 후 VM이 오프라인이 될 때까지 기다려야 하는 기간(초)을 정의합니다. 기본적으로 이 값은 180으로 설정됩니다. 이는 Proxmox VE가 종료 요청을 발행하고 시스템이 오프라인이 될 때까지 180초 동안 대기한다는 의미입니다. 시간 초과 후에도 머신이 여전히 온라인 상태이면 강제로 중지됩니다.
참고: HA 스택으로 관리되는 VM은 현재 부팅 시 시작 및 부팅 순서 옵션을 따르지 않습니다. HA 관리자 자체가 VM의 시작 및 중지를 보장하므로 시작 및 종료 알고리즘에 의해 이러한 VM은 건너뜁니다.
시작/종료 순서 매개변수가 없는 기계는 항상 매개변수가 설정된 기계 이후에 시작됩니다. 또한 이 매개변수는 클러스터 전체가 아닌 동일한 호스트에서 실행되는 가상 머신 간에만 적용할 수 있습니다.
호스트 부팅과 첫 번째 VM 부팅 사이에 지연이 필요한 경우 Proxmox VE 노드 관리 섹션을 참조하세요.
10.2.17. QEMU 게스트 에이전트
QEMU 게스트 에이전트는 VM 내부에서 실행되는 서비스로, 호스트와 게스트 간의 통신 채널을 제공합니다. 이는 정보를 교환하는 데 사용되며 호스트가 게스트에게 명령을 내릴 수 있도록 합니다.
예를 들어 VM 요약 패널의 IP 주소는 게스트 에이전트를 통해 가져옵니다.
또는 백업을 시작할 때 게스트 에이전트를 통해 게스트에게 fs-freeze 및 fs-thaw 명령을 통해 미해결 쓰기를 동기화하라는 지시가 전달됩니다.
게스트 에이전트가 제대로 작동하려면 다음 단계를 수행해야 합니다.
- 게스트에 에이전트를 설치하고 실행 중인지 확인하세요.
- Proxmox VE에서 에이전트를 통한 통신을 활성화합니다.
게스트 에이전트 설치
대부분의 Linux 배포판에서는 게스트 에이전트를 사용할 수 있습니다. 패키지 이름은 일반적으로 qemu-guest-agent입니다.
Windows의 경우 Fedora VirtIO 드라이버 ISO에서 설치할 수 있습니다.
게스트 에이전트 통신 활성화
Proxmox VE와 게스트 에이전트의 통신은 VM의 Options 패널에서 활성화할 수 있습니다. 변경 사항을 적용하려면 VM을 새로 시작해야 합니다.
QGA를 사용한 자동 TRIM
Run guest-trim 옵션을 활성화할 수 있습니다. 이 기능을 활성화하면 Proxmox VE는 스토리지에 0을 쓸 수 있는 다음 작업 후에 게스트에 트림 명령을 실행합니다.
- 디스크를 다른 저장소로 이동
- VM을 로컬 스토리지가 있는 다른 노드로 실시간 마이그레이션
씬 프로비저닝된 스토리지에서는 사용되지 않는 공간을 확보하는 데 도움이 될 수 있습니다.
참고: Linux의 ext4에는 중복된 TRIM 요청 발행을 피하기 위해 메모리 내 최적화를 사용하므로 주의할 점이 있습니다. 게스트는 기본 스토리지의 변경 사항을 모르기 때문에 첫 번째 게스트 트림만 예상대로 실행됩니다. 후속 재부팅은 그 이후에 변경된 파일 시스템의 일부만 고려합니다.
백업 시 파일 시스템 동결 및 해동
기본적으로 게스트 파일 시스템은 일관성을 제공하기 위해 백업이 수행될 때 fs-freeze QEMU 게스트 에이전트 명령을 통해 동기화됩니다.
Windows 게스트에서 일부 애플리케이션은 Windows VSS(Volume Shadow Copy Service) 계층에 연결하여 일관된 백업 자체를 처리할 수 있으며, fs-freeze가 이를 방해할 수 있습니다. 예를 들어, 일부 SQL Server에서 fs-freeze를 호출하면 차등 백업을 위해 SQL Server 백업 체인을 끊는 모드에서 VSS가 SQL Writer VSS 모듈을 호출하도록 트리거되는 것으로 관찰되었습니다.
이러한 설정의 경우 Freeze-fs-on-backup QGA 옵션을 0으로 설정하여 백업 시 Freeze-and-thaw 주기를 실행하지 않도록 Proxmox VE를 구성할 수 있습니다. 이는 Freeze/thaw guest filesystems on backup for consistency을 사용하는 GUI를 통해 수행할 수도 있습니다.
중요: 이 옵션을 비활성화하면 파일 시스템이 일관되지 않은 백업이 발생할 수 있으므로 수행 중인 작업을 알고 있는 경우에만 비활성화해야 합니다.
문제 해결
VM이 종료되지 않음
게스트 에이전트가 설치되어 실행 중인지 확인하세요.
게스트 에이전트가 활성화되면 Proxmox VE는 게스트 에이전트를 통해 종료와 같은 전원 명령을 보냅니다. 게스트 에이전트가 실행되고 있지 않으면 명령이 제대로 실행될 수 없으며 종료 명령이 실행되면 시간 초과가 발생합니다.
10.2.18. SPICE 향상
SPICE 향상은 원격 뷰어 경험을 향상시킬 수 있는 선택적 기능입니다.
GUI를 통해 이를 활성화하려면 가상 머신의 Options 패널로 이동하세요. CLI를 통해 활성화하려면 다음 명령을 실행하십시오.
qm set <vmid> -spice_enhancements foldersharing=1,videostreaming=all
참고 이러한 기능을 사용하려면 가상 머신의 디스플레이가 SPICE(qxl)로 설정되어야 합니다.
폴더 공유
게스트와 로컬 폴더를 공유합니다. spice-webdavd 데몬을 게스트에 설치해야 합니다. http://localhost:9843에 있는 로컬 WebDAV 서버를 통해 공유 폴더를 사용할 수 있게 만듭니다.
Windows 게스트의 경우 Spice WebDAV 데몬 설치 프로그램을 공식 SPICE 웹사이트에서 다운로드할 수 있습니다.
대부분의 Linux 배포판에는 설치할 수 있는 spice-webdavd라는 패키지가 있습니다.
Virt-Viewer(원격 뷰어)에서 폴더를 공유하려면 File → Preferences로 이동하세요. 공유할 폴더를 선택한 후 체크박스를 활성화하세요.
참고: 폴더 공유는 현재 Linux 버전의 Virt-Viewer에서만 작동합니다.
주의: 실험적입니다! 현재 이 기능은 안정적으로 작동하지 않습니다.
비디오 스트리밍
빠르게 새로 고쳐지는 영역은 비디오 스트림으로 인코딩됩니다. 두 가지 옵션이 있습니다:
- all: 빠르게 새로 고쳐지는 영역이 비디오 스트림으로 인코딩됩니다.
- 필터: 추가 필터는 비디오 스트리밍을 사용해야 하는지 결정하는 데 사용됩니다(현재는 작은 창 표면만 건너뜁니다).
비디오 스트리밍을 활성화해야 하는지와 선택할 옵션이 제공될 수 없는지에 대한 일반적인 권장 사항입니다. 귀하의 마일리지는 구체적인 상황에 따라 달라질 수 있습니다.
문제 해결
공유 폴더가 표시되지 않습니다
WebDAV 서비스가 게스트에서 활성화되어 실행되고 있는지 확인하세요. Windows에서는 Spice webdav 프록시라고 합니다. Linux에서 이름은 spice-webdavd이지만 배포판에 따라 다를 수 있습니다.
서비스가 실행 중인 경우 게스트의 브라우저에서 http://localhost:9843을 열어 WebDAV 서버를 확인합니다.
SPICE 세션을 다시 시작하는 데 도움이 될 수 있습니다.
10.3. 마이그레이션
클러스터가 있는 경우 다음을 사용하여 VM을 다른 호스트로 마이그레이션할 수 있습니다.
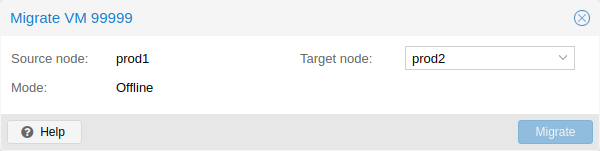
# qm migrate <vmid> <target>
일반적으로 이를 위한 두 가지 메커니즘이 있습니다.
- 온라인 마이그레이션(실시간 마이그레이션이라고도 함)
- 오프라인 마이그레이션
10.3.1. 온라인 마이그레이션
VM이 실행 중이고 로컬로 바인딩된 리소스(예: 전달되는 장치)가 구성되지 않은 경우 qm migration 명령 호출에서 –online 플래그를 사용하여 실시간 마이그레이션을 시작할 수 있습니다. VM이 실행 중일 때 웹 인터페이스는 기본적으로 실시간 마이그레이션으로 설정됩니다.
작동 원리
온라인 마이그레이션은 먼저 수신 플래그를 사용하여 대상 호스트에서 새로운 QEMU 프로세스를 시작합니다. 이 프로세스는 게스트 vCPU가 여전히 일시 중지된 상태에서 기본 초기화만 수행한 다음 소스 가상 머신의 게스트 메모리 및 장치 상태 데이터 스트림을 기다립니다. 디스크와 같은 다른 모든 리소스는 VM의 런타임 상태 마이그레이션이 시작되기 전에 공유되거나 이미 전송되었습니다. 따라서 메모리 내용과 장치 상태만 전송되도록 남아 있습니다.
이 연결이 설정되면 소스는 메모리 콘텐츠를 대상에 비동기적으로 보내기 시작합니다. 소스의 게스트 메모리가 변경되면 해당 섹션은 더티로 표시되고 게스트 메모리 데이터를 전송하기 위해 또 다른 패스가 생성됩니다. 이 루프는 실행 중인 소스 VM과 수신 대상 VM 간의 데이터 차이가 몇 밀리초 내에 전송될 만큼 작을 때까지 반복됩니다. 왜냐하면 사용자나 프로그램이 일시 중지를 인지하지 못한 채 소스 VM을 완전히 일시 중지할 수 있기 때문입니다. 데이터를 대상으로 전송한 다음 대상 VM의 CPU 일시 중지를 해제하여 1초 이내에 새 실행 VM으로 만들 수 있습니다.
요구사항
실시간 마이그레이션이 작동하려면 몇 가지 사항이 필요합니다.
- VM에 마이그레이션할 수 없는 로컬 리소스가 없습니다. 예를 들어 현재 실시간 마이그레이션을 차단하는 PCI 또는 USB 장치가 있습니다. 반면 로컬 디스크는 대상으로 전송하여 마이그레이션할 수 있습니다.
- 호스트는 동일한 Proxmox VE 클러스터에 있습니다.
- 호스트 간에 작동하는(그리고 안정적인) 네트워크 연결이 있습니다.
- 대상 호스트에는 Proxmox VE 패키지와 동일하거나 더 높은 버전이 있어야 합니다. 때로는 반대 방향으로 작동할 수도 있지만 이것이 보장될 수는 없습니다.
- 호스트에는 유사한 기능을 갖춘 동일한 공급업체의 CPU가 있습니다. 구성된 실제 모델 및 VM CPU 유형에 따라 다른 공급업체가 작동할 수 있지만 보장할 수는 없으므로 프로덕션에 이러한 설정을 배포하기 전에 테스트해 보시기 바랍니다.
10.3.2. 오프라인 마이그레이션
로컬 리소스가 있는 경우 모든 디스크가 두 호스트 모두에 정의된 스토리지에 있는 한 VM을 오프라인으로 계속 마이그레이션할 수 있습니다. 그런 다음 마이그레이션에서는 온라인 마이그레이션과 마찬가지로 네트워크를 통해 디스크를 대상 호스트에 복사합니다. 하드웨어 패스스루 구성은 대상 호스트의 장치 위치에 맞게 조정해야 할 수도 있습니다.
# qm set VMID -vmgenid 1 # qm set VMID -vmgenid 00000000-0000-0000-0000-000000000000
10.4. 복사본 및 클론
VM 설치는 일반적으로 운영 체제 공급업체의 설치 미디어(CD-ROM)를 사용하여 수행됩니다. OS에 따라 이는 시간이 많이 소요되는 작업이므로 피하고 싶을 수도 있습니다.
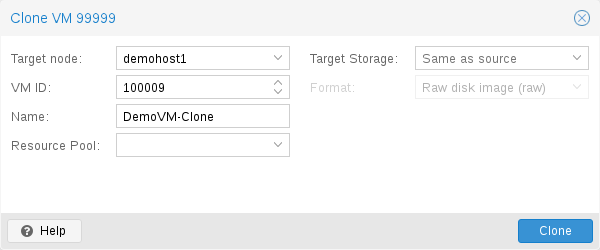
동일한 유형의 여러 VM을 배포하는 쉬운 방법은 기존 VM을 복사하는 것입니다. 이러한 복사본에는 클론이라는 용어를 사용하며 연결된 클론과 전체 클론을 구별합니다.
전체 클론
이러한 복사의 결과는 독립 VM입니다. 새 VM은 원본과 스토리지 리소스를 공유하지 않습니다.
대상 스토리지를 선택할 수 있으므로 이를 사용하여 VM을 완전히 다른 스토리지로 마이그레이션할 수 있습니다. 저장소 드라이버가 여러 형식을 지원하는 경우 디스크 이미지 형식을 변경할 수도 있습니다.
참고: 전체 클론은 모든 VM 이미지 데이터를 읽고 복사해야 합니다. 이는 일반적으로 연결된 클론을 생성하는 것보다 훨씬 느립니다.
일부 스토리지 유형에서는 기본적으로 현재 VM 데이터를 사용하는 특정 Snapshot을 복사할 수 있습니다. 이는 또한 최종 복사본에는 원본 VM의 추가 스냅샷이 포함되지 않음을 의미합니다.
Linked 클론
최신 스토리지 드라이버는 빠른 연결된 클론을 생성하는 방법을 지원합니다. 이러한 복제본은 초기 내용이 원본 데이터와 동일한 쓰기 가능한 복사본입니다. 연결된 클론 생성은 거의 즉시 이루어지며 처음에는 추가 공간을 소비하지 않습니다.
새 이미지가 여전히 원본을 참조하기 때문에 링크(linked)라고 합니다. 수정되지 않은 데이터 블록은 원본 이미지에서 읽혀지지만 수정된 데이터 블록은 새 위치에서 기록됩니다(나중에 읽습니다). 이 기술을 Copy-on-Write라고 합니다.
이를 위해서는 원본 볼륨이 읽기 전용이어야 합니다. Proxmox VE를 사용하면 모든 VM을 읽기 전용 템플릿으로 변환할 수 있습니다. 이러한 템플릿은 나중에 연결된 클론을 효율적으로 생성하는 데 사용될 수 있습니다.
참고: 연결된 클론이 존재하는 동안에는 원본 템플릿을 삭제할 수 없습니다.
연결된 클론의 Target storage는 스토리지 내부 기능이므로 변경할 수 없습니다.
Target node 옵션을 사용하면 다른 노드에 새 VM을 만들 수 있습니다. 유일한 제한 사항은 VM이 공유 스토리지에 있고 해당 스토리지를 대상 노드에서도 사용할 수 있다는 것입니다.
리소스 충돌을 방지하기 위해 모든 네트워크 인터페이스 MAC 주소는 무작위로 지정되며 VM BIOS(smbios1) 설정에 대한 새 UUID를 생성합니다.
10.5. 가상 머신 템플릿
VM을 템플릿으로 변환할 수 있습니다. 이러한 템플릿은 읽기 전용이며 이를 사용하여 연결된 클론을 생성할 수 있습니다.
참고: 디스크 이미지가 수정되면 템플릿을 시작할 수 없습니다. 템플릿을 변경하려면 연결된 클론을 생성하고 수정하십시오.
10.6. VM 생성 ID
Proxmox VE는 가상 머신에 대한 Virtual Machine Generation ID(vmgenid) [46]를 지원합니다. 이는 게스트 운영 체제에서 타임 시프트 이벤트를 발생시키는 이벤트(예: 백업 복원 또는 스냅샷 롤백)를 감지하는 데 사용될 수 있습니다.
새 VM을 생성하면 vmgenid가 자동으로 생성되어 해당 구성 파일에 저장됩니다.
vmgenid를 생성하고 기존 VM에 추가하려면 특수 값 ‘1’을 전달하여 Proxmox VE가 자동 생성하도록 하거나 UUID[47]를 값으로 사용하여 수동으로 설정할 수 있습니다. 예:
# qm set VMID -vmgenid 1 # qm set VMID -vmgenid 00000000-0000-0000-0000-000000000000
참고: 기존 VM에 vmgenid 장치를 처음 추가하면 VM이 이를 세대 변경으로 해석할 수 있으므로 스냅샷 롤백, 백업 복원 등에 대한 변경과 동일한 효과가 발생할 수 있습니다.
드문 경우지만 vmgenid 메커니즘을 원하지 않는 경우에는 VM 생성 시 해당 값으로 ‘0’을 전달하거나 다음을 사용하여 구성에서 속성을 소급하여 삭제할 수 있습니다.
# qm set VMID -delete vmgenid
vmgenid의 가장 눈에 띄는 사용 사례는 스냅샷 롤백, 백업 복원 또는 전체 VM 복제 작업에서 시간에 민감한 또는 복제 서비스(예: 데이터베이스 또는 도메인 컨트롤러 [48])의 문제를 방지하기 위해 이를 사용하는 최신 Microsoft Windows 운영 체제입니다.
10.7. 가상 머신 및 디스크 이미지 가져오기
외부 하이퍼바이저에서 VM 내보내기는 일반적으로 VM 설정(RAM, 코어 수)을 설명하는 구성 파일과 함께 하나 이상의 디스크 이미지 형식을 취합니다.
디스크 이미지는 디스크가 VMware 또는 VirtualBox에서 제공되는 경우 vmdk 형식일 수 있고, 디스크가 KVM 하이퍼바이저에서 제공되는 경우 qcow2 형식일 수 있습니다. VM 내보내기에 가장 많이 사용되는 구성 형식은 OVF 표준이지만 실제로는 많은 설정이 표준 자체에 구현되지 않고 하이퍼바이저가 비표준 확장으로 보충 정보를 내보내기 때문에 상호 운용이 제한됩니다.
형식 문제 외에도 에뮬레이트된 하드웨어가 한 하이퍼바이저에서 다른 하이퍼바이저로 너무 많이 변경되면 다른 하이퍼바이저에서 디스크 이미지를 가져오는 것이 실패할 수 있습니다. Windows VM은 OS가 하드웨어 변경에 대해 매우 까다롭기 때문에 특히 이에 대해 우려하고 있습니다. 이 문제는 내보내기 전에 인터넷에서 사용할 수 있는 MergeIDE.zip 유틸리티를 설치하고 가져온 Windows VM을 부팅하기 전에 IDE의 하드 디스크 유형을 선택하면 해결될 수 있습니다.
마지막으로 에뮬레이트된 시스템의 속도를 향상시키고 하이퍼바이저에 특정한 반가상화 드라이버에 대한 문제가 있습니다. GNU/Linux 및 기타 무료 Unix OS에는 기본적으로 필요한 모든 드라이버가 설치되어 있으며 VM을 가져온 후 바로 반가상화 드라이버로 전환할 수 있습니다. Windows VM의 경우 Windows 반가상화 드라이버를 직접 설치해야 합니다.
GNU/Linux 및 기타 무료 Unix는 일반적으로 번거로움 없이 가져올 수 있습니다. 위의 문제로 인해 모든 경우에 Windows VM의 성공적인 가져오기/내보내기를 보장할 수는 없습니다.
10.7.1. Windows OVF 가져오기의 단계별 예
Microsoft는 Windows 개발을 시작할 수 있도록 가상 머신 다운로드를 제공합니다. 이 중 하나를 사용하여 OVF 가져오기 기능을 시연해 보겠습니다.
가상 머신 zip 다운로드
사용자 계약에 대한 안내를 받은 후 VMware 플랫폼용 Windows 10 Enterprise(Evaluation – Build)를 선택하고 zip을 다운로드합니다.
zip에서 디스크 이미지를 추출합니다.
unzip 유틸리티 또는 원하는 아카이버를 사용하여 zip의 압축을 풀고 ssh/scp를 통해 ovf 및 vmdk 파일을 Proxmox VE 호스트에 복사합니다.
가상 머신 가져오기
그러면 OVF 매니페스트에서 읽은 코어, 메모리 및 VM 이름을 사용하여 새 가상 머신이 생성되고 디스크를 local-lvm 스토리지로 가져옵니다. 네트워크를 수동으로 구성해야 합니다.
# qm importovf 999 WinDev1709Eval.ovf local-lvm
VM을 시작할 준비가 되었습니다.
10.7.2. 가상 머신에 외부 디스크 이미지 추가
외부 하이퍼바이저에서 가져오거나 직접 생성한 기존 디스크 이미지를 VM에 추가할 수도 있습니다.
vmdebootstrap 도구를 사용하여 Debian/Ubuntu 디스크 이미지를 생성했다고 가정합니다.
vmdebootstrap --verbose \ --size 10GiB --serial-console \ --grub --no-extlinux \ --package openssh-server \ --package avahi-daemon \ --package qemu-guest-agent \ --hostname vm600 --enable-dhcp \ --customize=./copy_pub_ssh.sh \ --sparse --image vm600.raw
이제 새 대상 VM을 생성하여 이미지를 스토리지 pvedir로 가져와 VM의 SCSI 컨트롤러에 연결할 수 있습니다.
# qm create 600 --net0 virtio,bridge=vmbr0 --name vm600 --serial0 socket \ --boot order=scsi0 --scsihw virtio-scsi-pci --ostype l26 \ --scsi0 pvedir:0,import-from=/path/to/dir/vm600.raw
VM을 시작할 준비가 되었습니다.
10.8. Cloud-Init 지원
Cloud-Init는 가상 머신 인스턴스의 초기 초기화를 처리하는 사실상의 다중 배포 패키지입니다. Cloud-Init를 사용하면 하이퍼바이저 측에서 네트워크 장치 및 SSH 키를 구성할 수 있습니다. VM이 처음 시작되면 VM 내부의 Cloud-Init 소프트웨어가 해당 설정을 적용합니다.
많은 Linux 배포판은 대부분 OpenStack용으로 설계된 즉시 사용 가능한 Cloud-Init 이미지를 제공합니다. 이 이미지는 Proxmox VE에서도 작동합니다. 바로 사용할 수 있는 이미지를 얻는 것이 편리해 보일 수도 있지만 일반적으로 이미지를 직접 준비하는 것이 좋습니다. 장점은 무엇을 설치했는지 정확히 알 수 있다는 점이며, 이는 나중에 필요에 맞게 이미지를 쉽게 사용자 정의하는 데 도움이 됩니다.
이러한 Cloud-Init 이미지를 생성한 후에는 이를 VM 템플릿으로 변환하는 것이 좋습니다. VM 템플릿에서 연결된 클론을 빠르게 생성할 수 있으므로 이는 새 VM 인스턴스를 롤아웃하는 빠른 방법입니다. 새 VM을 시작하기 전에 네트워크(및 SSH 키)를 구성하기만 하면 됩니다.
Cloud-Init에서 프로비저닝한 VM에 로그인하려면 SSH 키 기반 인증을 사용하는 것이 좋습니다. 비밀번호를 설정할 수도 있지만 Proxmox VE는 해당 비밀번호의 암호화된 버전을 Cloud-Init 데이터 내에 저장해야 하기 때문에 SSH 키 기반 인증을 사용하는 것만큼 안전하지 않습니다.
Proxmox VE는 ISO 이미지를 생성하여 Cloud-Init 데이터를 VM에 전달합니다. 이를 위해 모든 Cloud-Init VM에는 할당된 CD-ROM 드라이브가 있어야 합니다. 일반적으로 직렬 콘솔을 추가하여 디스플레이로 사용해야 합니다. 많은 Cloud-Init 이미지가 이에 의존하며 이는 OpenStack의 요구 사항입니다. 그러나 다른 이미지에는 이 구성에 문제가 있을 수 있습니다. 직렬 콘솔을 사용해도 작동하지 않으면 기본 디스플레이 구성으로 다시 전환하세요.
10.8.1. Cloud-Init 템플릿 준비
첫 번째 단계는 VM을 준비하는 것입니다. 기본적으로 모든 VM을 사용할 수 있습니다. 준비하려는 VM 내부에 Cloud-Init 패키지를 설치하기만 하면 됩니다. Debian/Ubuntu 기반 시스템에서는 다음과 같이 간단합니다.
apt-get install cloud-init
경고: 이 명령은 Proxmox VE 호스트에서 실행되지 않고 VM 내부에서만 실행됩니다.
이미 많은 배포판에서 바로 사용할 수 있는 Cloud-Init 이미지(.qcow2 파일로 제공)를 제공하므로, 간단히 해당 이미지를 다운로드하고 가져올 수도 있습니다. 다음 예에서는 https://cloud-images.ubuntu.com에서 Ubuntu가 제공하는 클라우드 이미지를 사용합니다.
# download the image wget https://cloud-images.ubuntu.com/bionic/current/bionic-server-cloudimg-amd64.img # create a new VM with VirtIO SCSI controller qm create 9000 --memory 2048 --net0 virtio,bridge=vmbr0 --scsihw virtio-scsi-pci # import the downloaded disk to the local-lvm storage, attaching it as a SCSI drive qm set 9000 --scsi0 local-lvm:0,import-from=/path/to/bionic-server-cloudimg-amd64.img
참고: Ubuntu Cloud-Init 이미지에는 SCSI 드라이브용 virtio-scsi-pci 컨트롤러 유형이 필요합니다.
Cloud-Init CD-ROM 드라이브 추가
다음 단계는 Cloud-Init 데이터를 VM에 전달하는 데 사용되는 CD-ROM 드라이브를 구성하는 것입니다.
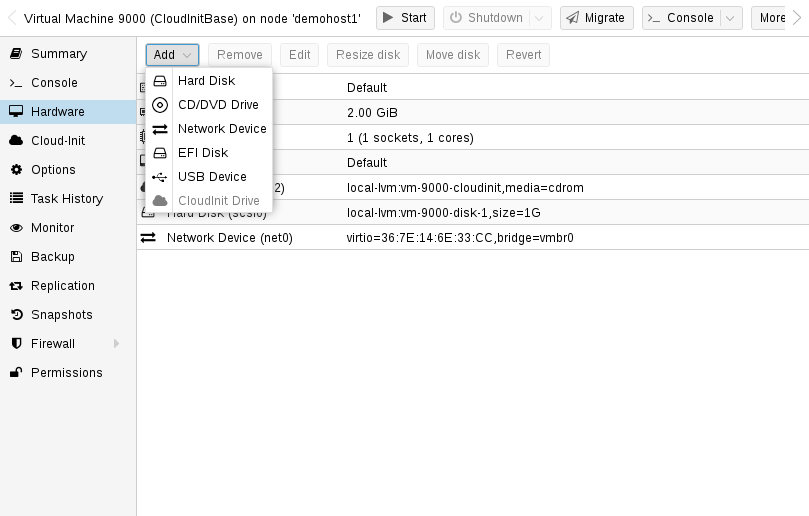
qm set 9000 --ide2 local-lvm:cloudinit
Cloud-Init 이미지에서 직접 부팅하려면 부팅 매개변수를 order=scsi0으로 설정하여 BIOS가 이 디스크에서만 부팅되도록 제한하세요. VM BIOS는 부팅 가능한 CD-ROM 테스트를 건너뛰기 때문에 부팅 속도가 빨라집니다.
qm set 9000 --boot order=scsi0
많은 Cloud-Init 이미지의 경우 직렬 콘솔을 구성하고 이를 디스플레이로 사용하는 것이 필요합니다. 그러나 특정 이미지에 대해 구성이 작동하지 않으면 대신 기본 디스플레이로 다시 전환하십시오.
qm set 9000 --serial0 socket --vga serial0
마지막 단계에서는 VM을 템플릿으로 변환하는 것이 도움이 됩니다. 그런 다음 이 템플릿을 사용하여 연결된 클론을 빠르게 생성할 수 있습니다. VM 템플릿을 통한 배포는 전체 복제(복사본)를 생성하는 것보다 훨씬 빠릅니다.
qm template 9000
10.8.2. Cloud-Init 템플릿 배포
다음을 복제하여 이러한 템플릿을 쉽게 배포할 수 있습니다.
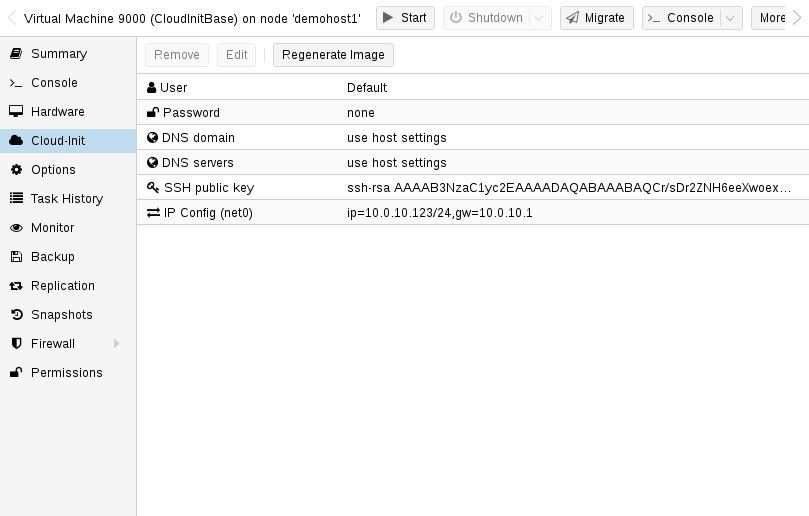
qm clone 9000 123 --name ubuntu2
그런 다음 인증에 사용되는 SSH 공개 키를 구성하고 IP 설정을 구성합니다.
qm set 123 --sshkey ~/.ssh/id_rsa.pub qm set 123 --ipconfig0 ip=10.0.10.123/24,gw=10.0.10.1
단일 명령만 사용하여 모든 Cloud-Init 옵션을 구성할 수도 있습니다. 위의 예를 분할하여 줄 길이를 줄이는 명령을 분리했습니다. 또한 특정 환경에 맞게 IP 설정을 채택하십시오.
10.8.3. 사용자 정의 Cloud-Init 구성
Cloud-Init 통합을 통해 자동으로 생성된 구성 대신 사용자 정의 구성 파일을 사용할 수도 있습니다. 이는 명령줄에서 cicustom 옵션을 통해 수행됩니다.
qm set 9000 --cicustom "user=<volume>,network=<volume>,meta=<volume>"
qm set 9000 --cicustom "user=local:snippets/userconfig.yaml"
Cloud-Init에는 세 가지 종류의 구성이 있습니다. 첫 번째는 위의 예에서 볼 수 있듯이 사용자 구성입니다. 두 번째는 네트워크 구성이고 세 번째는 메타 구성입니다. 필요에 따라 모두 함께 지정하거나 혼합하여 일치시킬 수 있습니다. 자동으로 생성된 구성은 사용자 정의 구성 파일이 지정되지 않은 구성에 사용됩니다.
생성된 구성을 덤프하여 사용자 정의 구성의 기반으로 사용할 수 있습니다.
qm cloudinit dump 9000 user
network와 meta에 동일한 명령이 존재합니다.
10.8.4. Cloud-Init 관련 옵션
이 부분은 번역하지 않았습니다.
영문 매뉴얼을 참조하시기 바랍니다.
https://pve.proxmox.com/pve-docs/pve-admin-guide.html#qm_cloud_init
10.9 PCI(e) 패스스루
PCI(e) 패스스루는 호스트에서 PCI 장치를 통해 가상 머신 제어를 제공하는 메커니즘입니다. 이는 가상화된 하드웨어를 사용하는 것보다 더 낮은 대기 시간, 더 높은 성능 또는 더 많은 기능(예: 오프로딩)과 같은 몇 가지 이점을 가질 수 있습니다.
그러나 장치를 통해 가상 머신으로 전달하면 호스트나 다른 VM에서 해당 장치를 더 이상 사용할 수 없습니다.
PCI 패스스루는 i440fx 및 q35 시스템에서 사용할 수 있지만 PCIe 패스스루는 q35 시스템에서만 사용할 수 있습니다. 이는 PCI 장치로 전달되는 PCIe 가능 장치가 PCI 속도로만 실행된다는 의미는 아닙니다. 장치를 PCIe로 전달하면 게스트에게 해당 장치가 “매우 빠른 레거시 PCI 장치”가 아닌 PCIe 장치임을 알리는 플래그가 설정됩니다. 일부 게스트 애플리케이션은 이로부터 이점을 얻습니다.
10.9.1. 일반적인 요구 사항
패스스루는 실제 하드웨어에서 수행되므로 몇 가지 요구 사항을 충족해야 합니다. 이러한 요구 사항에 대한 간략한 개요는 아래에 나와 있습니다. 특정 장치에 대한 자세한 내용은 PCI 패스스루 예를 참조하세요.
하드웨어
하드웨어는 IOMMU(I/O 메모리 관리 장치) 인터럽트 재매핑을 지원해야 하며 여기에는 CPU와 마더보드가 포함됩니다.
일반적으로 VT-d를 사용하는 Intel 시스템과 AMD-Vi를 사용하는 AMD 시스템이 이를 지원합니다. 하지만 하드웨어 구현이 불량하고 드라이버가 없거나 품질이 낮기 때문에 모든 것이 즉시 작동한다는 보장은 없습니다.
또한 서버급 하드웨어는 소비자급 하드웨어보다 더 나은 지원을 제공하는 경우가 많지만, 그럼에도 불구하고 많은 최신 시스템이 이를 지원할 수 있습니다.
특정 설정에 대해 Linux에서 이 기능을 지원하는지 확인하려면 하드웨어 공급업체에 문의하세요.
PCI 카드 주소 확인
가장 쉬운 방법은 GUI를 사용하여 VM의 하드웨어 탭에 “호스트 PCI” 유형의 장치를 추가하는 것입니다. 또는 명령줄을 사용할 수도 있습니다.
다음을 사용하여 카드를 찾을 수 있습니다.
lspci
구성
하드웨어가 패스스루를 지원하는지 확인한 후에는 PCI(e) 패스스루를 활성화하기 위한 몇 가지 구성을 수행해야 합니다.
IOMMU
먼저 BIOS/UEFI에서 IOMMU 지원을 활성화해야 합니다. 일반적으로 해당 설정을 IOMMU 또는 VT-d라고 부르지만, 정확한 옵션 이름은 마더보드 설명서에서 찾아야 합니다.
Intel CPU의 경우 다음을 추가하여 커널 명령줄 커널에서 IOMMU를 활성화해야 합니다.
intel_iommu=on
AMD CPU의 경우 자동으로 활성화되어야 합니다.
IOMMU 패스스루 모드
하드웨어가 IOMMU 통과 모드를 지원하는 경우 이 모드를 활성화하면 성능이 향상될 수 있습니다. 이는 VM이 일반적으로 하이퍼바이저에서 수행되는 (기본) DMA 변환을 우회하고 대신 DMA 요청을 하드웨어 IOMMU에 직접 전달하기 때문입니다. 이러한 옵션을 활성화하려면 다음을 추가하세요.
iommu=pt
커널 명령줄에.
커널 모듈
다음 모듈이 로드되었는지 확인해야 합니다. 이는 ‘/etc/modules’에 추가하면 됩니다. 6.2보다 최신 커널(Proxmox VE 8 이상)에서는 vfio_virqfd 모듈이 vfio 모듈의 일부이므로 Proxmox VE 8 이상에서는 vfio_virqfd를 로드할 필요가 없습니다.
vfio vfio_iommu_type1 vfio_pci vfio_virqfd #not needed if on kernel 6.2 or newer
관련된 모듈을 변경한 후에는 initramfs를 새로 고쳐야 합니다. Proxmox VE에서는 다음을 실행하여 이를 수행할 수 있습니다.
# update-initramfs -u -k all
모듈이 로드되고 있는지 확인하려면 다음의 출력을 확인하세요.
# lsmod | grep vfio
위의 4개 모듈을 포함해야 합니다.
구성 완료
마지막으로 재부팅하여 변경 사항을 적용하고 실제로 활성화되었는지 확인합니다.
# dmesg | grep -e DMAR -e IOMMU -e AMD-Vi
IOMMU, Directed I/O 또는 Interrupt Remapping이 활성화되어 있다고 표시되어야 하며, 하드웨어 및 커널에 따라 정확한 메시지가 다를 수 있습니다.
IOMMU가 의도한 대로 작동하는지 확인하거나 문제를 해결하는 방법에 대한 참고 사항은 위키의 IOMMU 매개 변수 확인 섹션을 참조하세요.
통과하려는 장치가 별도의 IOMMU 그룹에 있는 것도 중요합니다. 이는 Proxmox VE API 호출을 통해 확인할 수 있습니다.
# pvesh get /nodes/{nodename}/hardware/pci --pci-class-blacklist ""장치가 기능(예: HDMI 오디오 장치가 있는 GPU)이나 루트 포트 또는 PCI(e) 브리지와 함께 IOMMU 그룹에 속해 있어도 괜찮습니다.
메모: PCI(e) 슬롯
일부 플랫폼은 물리적 PCI(e) 슬롯을 다르게 처리합니다. 따라서 원하는 IOMMU 그룹 분리가 이루어지지 않는 경우 카드를 다른 PCI(e) 슬롯에 넣는 것이 도움이 될 수 있습니다.
메모: 안전하지 않은 인터럽트
일부 플랫폼의 경우 안전하지 않은 인터럽트를 허용해야 할 수도 있습니다. 이를 위해 /etc/modprobe.d/의 ‘.conf’ 파일로 끝나는 파일에 다음 줄을 추가합니다.
options vfio_iommu_type1 allow_unsafe_interrupts=1
이 옵션은 시스템을 불안정하게 만들 수 있다는 점에 유의하세요.
GPU 패스스루 참고사항
Proxmox VE 웹 인터페이스에서는 NoVNC 또는 SPICE를 통해 GPU의 프레임 버퍼를 표시할 수 없습니다.
전체 GPU 또는 vGPU를 통과하고 그래픽 출력이 필요한 경우 모니터를 카드에 물리적으로 연결하거나 게스트 내부에서 원격 데스크톱 소프트웨어(예: VNC 또는 RDP)를 구성해야 합니다.
예를 들어 OpenCL 또는 CUDA를 사용하는 프로그램의 경우 GPU를 하드웨어 가속기로 사용하려는 경우에는 이것이 필요하지 않습니다.
10.9.2. 호스트 장치 패스스루
가장 많이 사용되는 PCI(e) 패스스루 변형은 전체 PCI(e) 카드(예: GPU 또는 네트워크 카드)를 통과하는 것입니다.
호스트 구성
Proxmox VE는 호스트에서 PCI(e) 장치를 사용할 수 없도록 자동으로 시도합니다. 그러나 이것이 작동하지 않는 경우 수행할 수 있는 두 가지 작업이 있습니다.
다음을 추가하여 장치 ID를 vfio-pci 모듈의 옵션에 전달합니다.
options vfio-pci ids=1234:5678,4321:8765
/etc/modprobe.d/의 .conf 파일에 복사합니다. 여기서 1234:5678 및 4321:8765는 다음을 통해 얻은 공급업체 및 장치 ID입니다.
# lspci -nn
호스트의 드라이버를 완전히 블랙리스트에 추가하여 통과를 위해 자유롭게 바인딩할 수 있는지 확인합니다.
blacklist DRIVERNAME
/etc/modprobe.d/의 .conf 파일에 있습니다.
드라이버 이름을 찾으려면 다음을 실행하십시오.
# lspci -k
예를 들어:
# lspci -k | grep -A 3 "VGA"
다음과 비슷한 결과가 출력됩니다.
01:00.0 VGA compatible controller: NVIDIA Corporation GP108 [GeForce GT 1030] (rev a1)
Subsystem: Micro-Star International Co., Ltd. [MSI] GP108 [GeForce GT 1030]
Kernel driver in use: <some-module>
Kernel modules: <some-module>이제 드라이버를 .conf 파일에 작성하여 드라이버를 블랙리스트에 올릴 수 있습니다.
echo "blacklist <some-module>" >> /etc/modprobe.d/blacklist.conf
두 방법 모두 initramfs를 다시 업데이트하고 그 후에 재부팅해야 합니다.
이것이 작동하지 않으면 vfio-pci를 로드하기 전에 GPU 모듈을 로드하도록 소프트 종속성을 설정해야 할 수도 있습니다. 이는 softdep 플래그를 사용하여 수행할 수 있습니다. 자세한 내용은 modprobe.d의 맨페이지를 참조하세요.
예를 들어 이라는 드라이버를 사용하는 경우:
# echo "softdep <some-module> pre: vfio-pci" >> /etc/modprobe.d/<some-module>.conf
구성 확인
변경 사항이 성공적으로 완료되었는지 확인하려면 다음을 사용하세요.
# lspci -nnk
장치 항목을 확인하십시오. 라고 하면
Kernel driver in use: vfio-pci
또는 in use 라인이 완전히 누락된 경우 장치를 패스스루에 사용할 준비가 된 것입니다.
VM 구성
GPU를 통과할 때 머신 유형으로 q35, SeaBIOS 대신 OVMF(VM용 UEFI), PCI 대신 PCIe를 사용할 때 최고의 호환성에 도달합니다. GPU 패스스루에 OVMF를 사용하려면 GPU에 UEFI 지원 ROM이 있어야 하며, 그렇지 않으면 SeaBIOS를 대신 사용해야 합니다. ROM이 UEFI를 지원하는지 확인하려면 PCI 패스스루 예제 위키를 참조하세요.
또한 OVMF를 사용하면 vga 조정을 비활성화하여 부팅 중에 실행해야 하는 레거시 코드의 양을 줄일 수 있습니다. vga 중재를 비활성화하려면:
echo "options vfio-pci ids=<vendor-id>,<device-id> disable_vga=1" > /etc/modprobe.d/vfio.conf
및 를 다음에서 얻은 것으로 바꿉니다.
# lspci -nn
VM의 하드웨어 섹션에 있는 웹 인터페이스에 PCI 장치를 추가할 수 있습니다. 또는 명령줄을 사용할 수도 있습니다. 예를 들어 다음을 실행하여 VM 구성에서 hostpciX 옵션을 설정합니다.
# qm set VMID -hostpci0 00:02.0
또는 VM 구성 파일에 다음 줄을 추가하면 됩니다.
hostpci0: 00:02.0
장치에 여러 기능(예: ’00:02.0′ 및 ’00:02.1′)이 있는 경우 단축 구문 ’00:02’을 사용하여 해당 기능을 모두 함께 전달할 수 있습니다. 이는 웹 인터페이스에서 ‘모든 기능’ 확인란을 선택하는 것과 동일합니다.
장치 및 게스트 OS에 따라 필요할 수 있는 몇 가지 옵션이 있습니다.
- x-vga=on|off는 PCI(e) 장치를 VM의 기본 GPU로 표시합니다. 이 기능을 활성화하면 vga 구성 옵션이 무시됩니다.
- pcie=on|off는 Proxmox VE에 PCIe 또는 PCI 포트를 사용하도록 지시합니다. 일부 게스트/장치 조합에는 PCI가 아닌 PCIe가 필요합니다. PCIe는 q35 머신 유형에만 사용할 수 있습니다.
- rombar=on|off는 게스트에게 펌웨어 ROM을 표시합니다. 기본값은 켜져 있습니다. 일부 PCI(e) 장치에서는 이 기능을 비활성화해야 합니다.
- romfile=는 장치가 사용할 ROM 파일의 선택적 경로입니다. 이는 /usr/share/kvm/ 아래의 상대 경로입니다.
예
GPU가 기본으로 설정된 PCIe 패스스루의 예:
# qm set VMID -hostpci0 02:00,pcie=on,x-vga=on
PCI ID 재정의
게스트에게 표시되는 PCI 공급업체 ID, 장치 ID 및 하위 시스템 ID를 재정의할 수 있습니다. 이는 장치가 게스트의 드라이버가 인식하지 못하는 ID를 가진 변형이지만 어쨌든 해당 드라이버를 강제로 로드하려는 경우에 유용합니다(예: 장치가 지원되는 변형과 동일한 칩셋을 공유한다는 것을 알고 있는 경우).
사용 가능한 옵션은 vendor-id, device-id, sub-vendor-id, sub-device-id입니다. 이들 중 일부 또는 전부를 설정하여 장치의 기본 ID를 재정의할 수 있습니다.
예를 들어:
# qm set VMID -hostpci0 02:00,device-id=0x10f6,sub-vendor-id=0x0000
10.9.3. SR-IOV
PCI(e) 장치를 통과하는 또 다른 변형은 가능한 경우 장치의 하드웨어 가상화 기능을 사용하는 것입니다.
메모: SR-IOV 활성화
SR-IOV를 사용하려면 플랫폼 지원이 특히 중요합니다. 먼저 BIOS/UEFI에서 이 기능을 활성화하거나 이 기능이 작동하려면 특정 PCI(e) 포트를 사용해야 할 수도 있습니다. 확실하지 않은 경우 플랫폼 설명서를 참조하거나 해당 공급업체에 문의하세요.
SR-IOV(Single-Root Input/Output Virtualization)를 사용하면 단일 장치가 시스템에 여러 VF(가상 기능)를 제공할 수 있습니다. 이러한 각 VF는 전체 하드웨어 기능을 갖추고 소프트웨어 가상화 장치보다 성능이 향상되고 대기 시간이 짧은 다른 VM에서 사용할 수 있습니다.
현재 가장 일반적인 사용 사례는 물리적 포트당 여러 VF를 제공할 수 있는 SR-IOV를 지원하는 NIC(네트워크 인터페이스 카드)입니다. 이를 통해 체크섬 오프로딩 등과 같은 기능을 VM 내부에서 사용할 수 있어 (호스트) CPU 오버헤드가 줄어듭니다.
호스트 구성
일반적으로 장치에서 가상 기능을 활성화하는 방법에는 두 가지가 있습니다.
- 때로는 드라이버 모듈에 대한 옵션이 있습니다. 일부 Intel 드라이버의 경우
max_vfs=4
/etc/modprobe.d/ 아래에 .conf로 끝나는 파일을 넣을 수 있습니다. (그 후에는 initramfs를 업데이트하는 것을 잊지 마세요)
정확한 매개변수와 옵션은 드라이버 모듈 설명서를 참조하십시오.
두 번째로 보다 일반적인 접근 방식은 sysfs를 사용하는 것입니다. 장치와 드라이버가 이를 지원하는 경우 즉시 VF 수를 변경할 수 있습니다. 예를 들어 장치 0000:01:00.0에 4개의 VF를 설정하려면 다음을 실행합니다.
# echo 4 > /sys/bus/pci/devices/0000:01:00.0/sriov_numvfs
이 변경 사항을 지속적으로 적용하려면 ‘sysfsutils’ Debian 패키지를 사용할 수 있습니다. 설치 후 /etc/sysfs.conf 또는 /etc/sysfs.d/의 `FILE.conf’를 통해 구성하십시오.
VM 구성
VF를 생성한 후 lspci를 사용하여 출력할 때 별도의 PCI(e) 장치로 표시되어야 합니다. ID를 가져와 일반 PCI(e) 장치처럼 통과시킵니다.
10.9.4. 중재된 장치(vGPU, GVT-g)
중재된 장치는 가상화된 하드웨어에 대해 물리적 하드웨어의 기능과 성능을 재사용하는 또 다른 방법입니다. 이는 GRID 기술에 사용되는 Intel의 GVT-g 및 NVIDIA의 vGPU와 같은 가상화된 GPU 설정에서 가장 일반적으로 발견됩니다.
이를 통해 물리적 카드는 SR-IOV와 유사한 가상 카드를 생성할 수 있습니다. 차이점은 조정된 장치가 호스트에서 PCI(e) 장치로 표시되지 않으며 가상 머신에서만 사용하기에 적합하다는 것입니다.
호스트 구성
일반적으로 카드 드라이버가 해당 기능을 지원해야 합니다. 그렇지 않으면 작동하지 않습니다. 따라서 호환되는 드라이버와 구성 방법은 공급업체에 문의하세요.
GVT-g용 Intel 드라이버는 커널에 통합되어 있으며 5세대, 6세대, 7세대 Intel Core 프로세서는 물론 E3 v4, E3 v5 및 E3 v6 Xeon 프로세서와도 작동해야 합니다.
Intel 그래픽에 대해 활성화하려면 kvmgt 모듈을 로드하고(예: /etc/modules를 통해) 커널 명령줄에서 활성화하고 다음 매개변수를 추가해야 합니다.
i915.enable_gvt=1
그런 다음 initramfs를 업데이트하고 호스트를 재부팅하는 것을 잊지 마세요.
VM 구성
조정된 장치를 사용하려면 간단히 hostpciX VM 구성 옵션에서 mdev 속성을 지정하면 됩니다.
sysfs를 통해 지원되는 장치를 얻을 수 있습니다. 예를 들어, 0000:00:02.0 장치에 대해 지원되는 유형을 나열하려면 다음을 실행하면 됩니다.
# ls /sys/bus/pci/devices/0000:00:02.0/mdev_supported_types
각 항목은 다음과 같은 중요한 파일을 포함하는 디렉터리입니다.
- available_instances에는 이 유형의 여전히 사용 가능한 인스턴스의 양이 포함되어 있으며, VM에서 mdev를 사용할 때마다 이 양이 줄어듭니다.
- 설명에는 유형의 기능에 대한 간단한 설명이 포함되어 있습니다.
- create는 이러한 장치를 생성하기 위한 엔드포인트이며, mdev와 함께 hostpciX 옵션이 구성된 경우 Proxmox VE는 이 작업을 자동으로 수행합니다.
Intel GVT-g vGPU(Intel Skylake 6700k)를 사용한 구성 예:
# qm set VMID -hostpci0 00:02.0,mdev=i915-GVTg_V5_4
이 설정을 사용하면 Proxmox VE는 VM 시작 시 자동으로 이러한 장치를 생성하고 VM이 중지되면 다시 정리합니다.
10.9.5. 클러스터에서 사용
클러스터 수준에서 장치를 매핑하여 HA와 함께 적절하게 사용할 수 있으며 하드웨어 변경 사항이 감지되고 루트가 아닌 사용자가 이를 구성할 수 있습니다. 자세한 내용은 리소스 매핑을 참조하세요.
10.10. 훅스크립트(Hookscripts)
구성 속성 Hookscript를 사용하여 VM에 후크 스크립트를 추가할 수 있습니다.
# qm set 100 --hookscript local:snippets/hookscript.pl
게스트 수명의 다양한 단계에서 호출됩니다. 예제와 문서를 보려면 /usr/share/pve-docs/examples/guest-example-hookscript.pl 아래의 예제 스크립트를 참조하세요.
10.11 하이버네이션
GUI 옵션 Hibernate 모드 또는 다음을 사용하여 VM을 디스크로 일시 중단할 수 있습니다.
# qm suspend ID --todisk
즉, 메모리의 현재 내용이 디스크에 저장되고 VM이 중지됩니다. 다음 시작 시 메모리 콘텐츠가 로드되고 VM은 중단된 부분부터 계속할 수 있습니다.
상태 저장소 선택
메모리에 대한 대상 저장소가 제공되지 않으면 다음 중 첫 번째 항목이 자동으로 선택됩니다.
- VM 구성의 스토리지 vmstatestorage입니다.
- 모든 VM 디스크의 첫 번째 공유 스토리지입니다.
- 모든 VM 디스크의 첫 번째 비공유 스토리지입니다.
- 대체 스토리지는 로컬입니다.
10.12. 리소스 매핑
로컬 리소스(예: pci 장치의 주소)를 사용하거나 참조할 때 원시 주소나 ID를 사용하는 것은 때때로 문제가 됩니다. 예:
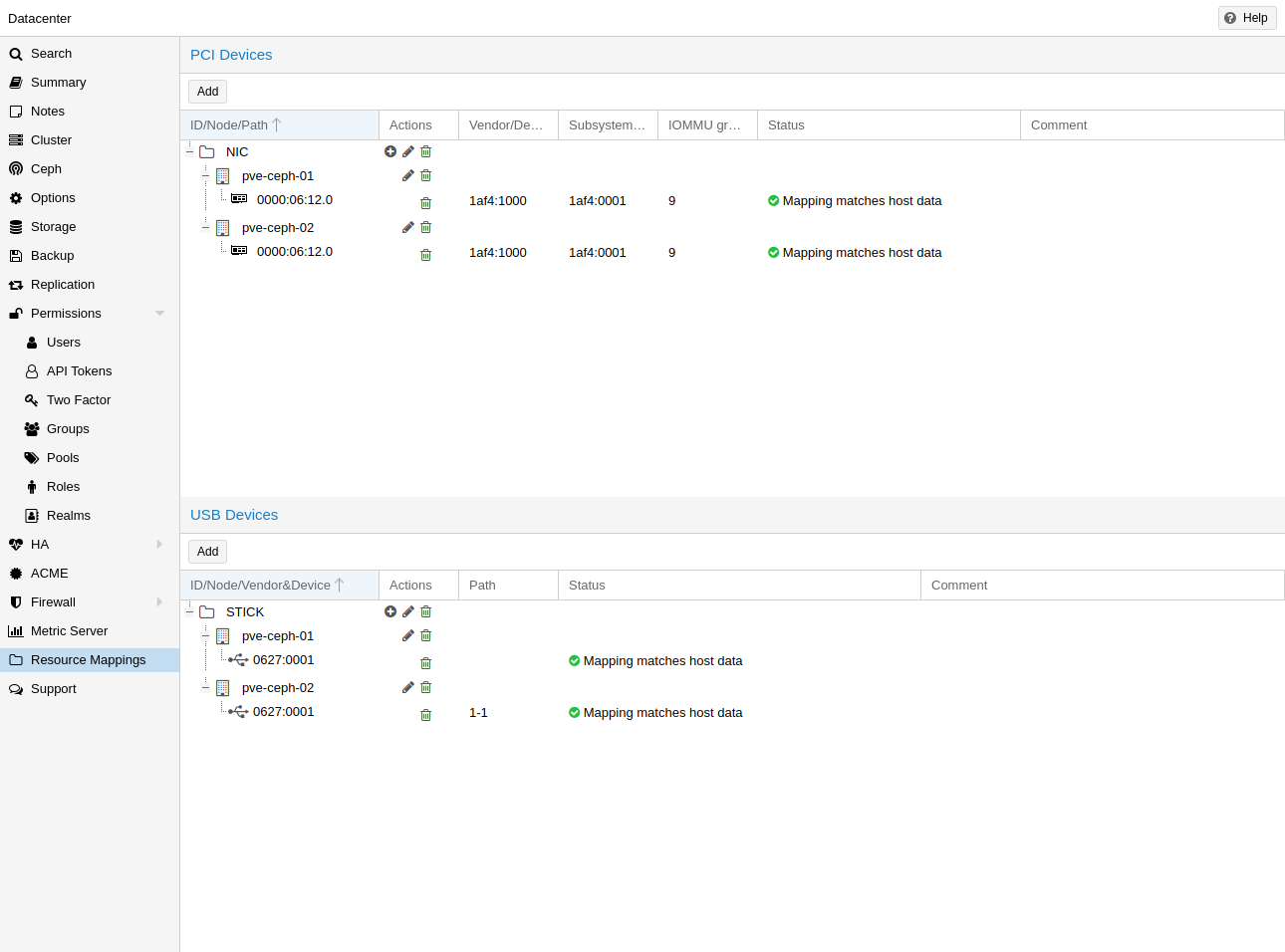
- HA를 사용할 때 동일한 ID나 경로를 가진 다른 장치가 대상 노드에 존재할 수 있으며, 이러한 게스트를 HA 그룹에 할당할 때 주의하지 않으면 잘못된 장치가 사용되어 구성이 중단될 수 있습니다.
- 하드웨어를 변경하면 ID와 경로가 변경될 수 있으므로 할당된 모든 장치를 확인하고 경로나 ID가 여전히 올바른지 확인해야 합니다.
이를 더 잘 처리하기 위해 리소스가 서로 다른 호스트의 서로 다른 장치에 해당할 수 있는 클러스터 고유의 사용자 선택 식별자를 갖도록 클러스터 전체 리소스 매핑을 정의할 수 있습니다. 이를 통해 HA는 잘못된 장치로 게스트를 시작하지 않으며 하드웨어 변경 사항을 감지할 수 있습니다.
이러한 매핑 생성은 Resource Mappings 범주의 관련 탭에 있는 Datacenter 아래 Proxmox VE 웹 GUI를 사용하거나 다음을 사용하는 cli에서 수행할 수 있습니다.
# pvesh create /cluster/mapping/<type> <options>
여기서 은 하드웨어 유형(현재 pci 또는 usb)이고 는 장치 매핑 및 기타 구성 매개변수입니다.
옵션에는 해당 하드웨어의 모든 식별 속성이 포함된 맵 속성이 포함되어야 합니다. 그래야 하드웨어가 변경되지 않았으며 올바른 장치가 통과되었는지 확인할 수 있습니다.
예를 들어 노드 node1에 장치 ID 0001과 공급업체 ID 0002가 있고 node2에 0000:02:00.0이 있는 경로 0000:01:00.0을 사용하여 PCI 장치를 장치1로 추가하려면 다음을 사용하여 추가할 수 있습니다.
# pvesh create /cluster/mapping/pci --id device1 \ --map node=node1,path=0000:01:00.0,id=0002:0001 \ --map node=node2,path=0000:02:00.0,id=0002:0001
해당 장치에 매핑이 있어야 하는 각 노드에 대해 맵 매개변수를 반복해야 합니다(현재는 매핑당 노드당 하나의 USB 장치만 매핑할 수 있습니다).
GUI를 사용하면 올바른 속성이 자동으로 선택되어 API로 전송되므로 이 작업이 훨씬 쉬워집니다.
PCI 장치가 노드에 대한 여러 맵 속성을 사용하여 노드당 여러 장치를 제공하는 것도 가능합니다. 이러한 장치가 게스트에게 할당된 경우 게스트가 시작될 때 첫 번째 무료 장치가 사용됩니다. 주어진 경로의 순서는 시도되는 순서이기도 하므로 임의의 할당 정책을 구현할 수 있습니다.
어떤 경우에는 정확한 가상 기능이 전달되는지가 중요하지 않기 때문에 이는 SR-IOV가 있는 장치에 유용합니다.
GUI 또는 다음을 사용하여 게스트에게 이러한 장치를 할당할 수 있습니다.
# qm set ID -hostpci0 <name>
PCI 장치의 경우 또는
# qm set <vmid> -usb0 <name>
USB 장치용.
여기서 는 게스트 ID이고 은 생성된 매핑에 대해 선택한 이름입니다. mdev와 같은 장치 통과를 위한 모든 일반적인 옵션이 허용됩니다.
매핑을 생성하려면 /mapping//에 대한 Mapping.Modify가 필요합니다. 여기서 은 장치 유형이고 은 매핑의 이름입니다.
이러한 매핑을 사용하려면 /mapping//에 대한 Mapping.Use가 필요합니다(구성을 편집하기 위한 일반 게스트 권한 외에도).
10.13. qm으로 가상머신 관리
qm은 Proxmox VE에서 QEMU/KVM 가상 머신을 관리하는 도구입니다. 가상 머신을 생성 및 제거하고 실행(시작/중지/일시 중지/재개)을 제어할 수 있습니다. 그 외에도 qm을 사용하여 관련 구성 파일에 매개변수를 설정할 수 있습니다. 가상 디스크를 생성하고 삭제할 수도 있습니다.
10.13.1. CLI 사용 예
로컬 스토리지에 업로드된 iso 파일을 사용하여 local-lvm 스토리지에 4GB IDE 디스크가 있는 VM을 생성합니다.
# qm create 300 -ide0 local-lvm:4 -net0 e1000 -cdrom local:iso/proxmox-mailgateway_2.1.iso
새 VM 시작
# qm start 300
종료 요청을 보낸 다음 VM이 중지될 때까지 기다립니다.
# qm shutdown 300 && qm wait 300
위와 동일하지만 40초만 기다리세요.
# qm shutdown 300 && qm wait 300 -timeout 40
VM을 삭제하면 항상 액세스 제어 목록에서 제거되고 VM의 방화벽 구성도 항상 제거됩니다. 복제 작업, 백업 작업 및 HA 리소스 구성에서 VM을 추가로 제거하려면 –purge를 활성화해야 합니다.
# qm destroy 300 --purge
디스크 이미지를 다른 저장소로 이동합니다.
# qm move-disk 300 scsi0 other-storage
디스크 이미지를 다른 VM에 다시 할당합니다. 이렇게 하면 소스 VM에서 디스크 scsi1이 제거되고 이를 대상 VM에 scsi3으로 연결됩니다. 백그라운드에서 이름이 새 소유자와 일치하도록 디스크 이미지의 이름이 변경됩니다.
# qm move-disk 300 scsi1 --target-vmid 400 --target-disk scsi3
10.14. 구성
VM 구성 파일은 Proxmox 클러스터 파일 시스템 내에 저장되며 /etc/pve/qemu-server/.conf에서 액세스할 수 있습니다. /etc/pve/에 저장된 다른 파일과 마찬가지로 이 파일도 다른 모든 클러스터 노드에 자동으로 복제됩니다.
참고: 100보다 작은 VMID는 내부용으로 예약되어 있으며 VMID는 클러스터 전체에서 고유해야 합니다.
VM 구성 예
boot: order=virtio0;net0 cores: 1 sockets: 1 memory: 512 name: webmail ostype: l26 net0: e1000=EE:D2:28:5F:B6:3E,bridge=vmbr0 virtio0: local:vm-100-disk-1,size=32G
이러한 구성 파일은 간단한 텍스트 파일이며 일반 텍스트 편집기(vi, nano, …)를 사용하여 편집할 수 있습니다. 이는 때때로 작은 수정을 수행하는 데 유용하지만 이러한 변경 사항을 적용하려면 VM을 다시 시작해야 한다는 점을 명심하십시오.
이러한 이유로 일반적으로 qm 명령을 사용하여 해당 파일을 생성 및 수정하거나 GUI를 사용하여 모든 작업을 수행하는 것이 더 좋습니다. 우리의 툴킷은 실행 중인 VM에 대부분의 변경 사항을 즉시 적용할 수 있을 만큼 똑똑합니다. 이 기능을 “핫 플러그”라고 하며 이 경우 VM을 다시 시작할 필요가 없습니다.
10.14.1. 파일 형식
VM 구성 파일은 콜론으로 구분된 간단한 키/값 형식을 사용합니다. 각 줄의 형식은 다음과 같습니다.
# this is a comment OPTION: value
해당 파일의 빈 줄은 무시되고 # 문자로 시작하는 줄은 주석으로 처리되어 무시됩니다.
10.14.2. 스냅샷
스냅샷을 생성할 때 qm은 스냅샷 시간의 구성을 동일한 구성 파일 내의 별도 스냅샷 섹션에 저장합니다. 예를 들어 “testsnapshot”이라는 스냅샷을 생성한 후 구성 파일은 다음과 같습니다.
스냅샷을 사용한 VM 구성
memory: 512 swap: 512 parent: testsnaphot ... [testsnaphot] memory: 512 swap: 512 snaptime: 1457170803 ...
상위 및 스냅타임과 같은 몇 가지 스냅샷 관련 속성이 있습니다. parent 속성은 스냅샷 간의 상위/하위 관계를 저장하는 데 사용됩니다. snaptime은 스냅샷 생성 타임스탬프(Unix epoch)입니다.
선택적으로 vmstate 옵션을 사용하여 실행 중인 VM의 메모리를 저장할 수 있습니다. VM 상태에 대한 대상 스토리지를 선택하는 방법에 대한 자세한 내용은 최대 절전 모드 장의 상태 스토리지 선택을 참조하세요.
10.14.3. 옵션
이 부분은 번역하지 않았습니다.
영문 매뉴얼을 참조하시기 바랍니다.
https://pve.proxmox.com/pve-docs/pve-admin-guide.html#qm_configuration
10.15. 잠금
온라인 마이그레이션, 스냅샷 및 백업(vzdump)은 영향을 받는 VM에서 호환되지 않는 동시 작업을 방지하기 위해 잠금을 설정합니다. 때로는 이러한 잠금을 수동으로 제거해야 하는 경우도 있습니다(예: 정전 후).
# qm unlock <vmid>
주의: 잠금을 설정한 작업이 더 이상 실행되지 않는다고 확신하는 경우에만 그렇게 하십시오.

