
Proxmox VE 매뉴얼을 Google Translate로 기계번역하고, 살짝 교정했습니다.
https://pve.proxmox.com/pve-docs/pve-admin-guide.html
version 8.1.4, Wed Mar 6 18:21:39 CET 2024
우리 현대 사회는 네트워크를 통해 컴퓨터가 제공하는 정보에 크게 의존하고 있습니다. 모바일 장치는 사람들이 언제 어디서나 네트워크에 액세스할 수 있기 때문에 이러한 의존성을 증폭시켰습니다. 그러한 서비스를 제공하는 경우 해당 서비스를 대부분의 시간 동안 사용할 수 있는 것이 매우 중요합니다.
가용성을 주어진 간격 동안 서비스를 사용할 수 있는 총 시간인 (A)와 간격의 길이인 (B)의 비율로 수학적으로 정의할 수 있습니다. 일반적으로 특정 연도의 가동 시간 비율로 표시됩니다.
표 18. 가용성 – 연간 다운타임
| Availability % | Downtime per year |
|---|---|
| 99 | 3.65 days |
| 99.9 | 8.76 hours |
| 99.99 | 52.56 minutes |
| 99.999 | 5.26 minutes |
| 99.9999 | 31.5 seconds |
| 99.99999 | 3.15 seconds |
가용성을 높이는 방법에는 여러 가지가 있습니다. 가장 우아한 해결책은 소프트웨어를 다시 작성하여 동시에 여러 호스트에서 실행할 수 있도록 하는 것입니다. 소프트웨어 자체에는 오류를 감지하고 장애 조치를 수행할 수 있는 방법이 있어야 합니다. 읽기 전용 웹 페이지만 제공하려는 경우 이는 비교적 간단합니다. 그러나 이는 소프트웨어를 직접 수정할 수 없기 때문에 일반적으로 복잡하고 때로는 불가능합니다. 다음 솔루션은 소프트웨어를 수정하지 않고도 작동합니다.
- 안정적인 “서버” 구성요소 사용
참고 동일한 기능을 가진 컴퓨터 구성 요소라도 구성 요소 품질에 따라 신뢰도 수치가 달라질 수 있습니다. 대부분의 공급업체는 안정성이 더 높은 구성 요소를 “서버” 구성 요소로 판매하며 일반적으로 더 높은 가격에 판매합니다.
- 단일 장애 지점 제거(중복 구성 요소)
- 무정전 전원 공급 장치(UPS)를 사용하세요.
- 서버에 중복 전원 공급 장치 사용
- ECC-RAM을 사용하세요
- 중복 네트워크 하드웨어 사용
- 로컬 스토리지에 RAID 사용
- VM 데이터에 분산된 중복 스토리지 사용
- 가동 중지 시간 감소
- 신속하게 접근 가능한 관리자(24/7)
- 예비 부품 가용성(Proxmox VE 클러스터의 다른 노드)
- 자동 오류 감지 (ha-manager 제공)
- 자동 장애 조치(ha-manager 제공)
Proxmox VE와 같은 가상화 환경은 “하드웨어” 종속성을 제거하므로 고가용성에 훨씬 쉽게 도달할 수 있습니다. 또한 중복 스토리지 및 네트워크 장치의 설정 및 사용을 지원하므로 한 호스트에 장애가 발생하면 클러스터 내의 다른 호스트에서 해당 서비스를 간단히 시작할 수 있습니다.
더 좋은 점은 Proxmox VE가 ha-manager라는 소프트웨어 스택을 제공하여 이를 자동으로 수행할 수 있다는 것입니다. 자동으로 오류를 감지하고 자동 장애 조치를 수행할 수 있습니다.
Proxmox VE ha-manager는 “자동화된” 관리자처럼 작동합니다. 먼저 관리해야 할 리소스(VM, 컨테이너 등)를 구성합니다. 그런 다음 ha-manager는 올바른 기능을 관찰하고 오류가 발생할 경우 다른 노드로의 서비스 장애 조치를 처리합니다. ha-manager는 서비스 시작, 중지, 재배치 및 마이그레이션과 같은 일반 사용자 요청도 처리할 수 있습니다.
그러나 고가용성은 대가를 치르게 됩니다. 고품질 구성 요소는 더 비싸며 중복되게 만들면 비용이 최소한 두 배로 늘어납니다. 추가 예비 부품은 비용을 더욱 증가시킵니다. 따라서 이점을 주의 깊게 계산하고 추가 비용과 비교해야 합니다.
팁> 가용성을 99%에서 99.9%로 높이는 것은 비교적 간단합니다. 그러나 가용성을 99.9999%에서 99.99999%로 높이는 것은 매우 어렵고 비용이 많이 듭니다. ha-manager는 일반적인 오류 감지 및 장애 조치 시간이 약 2분이므로 99.999% 이하의 가용성을 얻을 수 있습니다.
15.1. 요구사항
HA를 시작하기 전에 다음 요구 사항을 충족해야 합니다.
- 3개 이상의 클러스터 노드(신뢰할 수 있는 쿼럼을 얻기 위해)
- VM 및 컨테이너를 위한 공유 스토리지
- 하드웨어 이중화(어디서나)
- 안정적인 “서버” 구성요소 사용
- 하드웨어 워치독 – 사용할 수 없는 경우 Linux 커널 소프트웨어 워치독(softdog)으로 대체됩니다.
- 선택적 하드웨어 펜싱 장치
15.2. 자원
ha-manager가 처리하는 기본 관리 단위를 리소스라고 부릅니다. 리소스(“서비스”라고도 함)는 리소스 유형과 유형별 ID로 구성된 서비스 ID(SID)로 고유하게 식별됩니다(예: vm:100). 해당 예는 ID가 100인 vm(가상 머신) 유형의 리소스입니다.
현재로서는 가상 머신과 컨테이너라는 두 가지 중요한 리소스 유형이 있습니다. 여기서 한 가지 기본 아이디어는 관련 소프트웨어를 VM이나 컨테이너에 묶을 수 있으므로 rgmanager에서처럼 다른 서비스에서 하나의 큰 서비스를 구성할 필요가 없다는 것입니다. 일반적으로 HA 관리 리소스는 다른 리소스에 종속되어서는 안 됩니다.
15.3. 관리업무
이 섹션에서는 일반적인 관리 작업에 대한 간략한 개요를 제공합니다. 첫 번째 단계는 리소스에 대해 HA를 활성화하는 것입니다. 이는 HA 리소스 구성에 리소스를 추가하여 수행됩니다. GUI를 사용하거나 간단히 명령줄 도구를 사용하여 이 작업을 수행할 수 있습니다. 예를 들면 다음과 같습니다.
# ha-manager add vm:100
이제 HA 스택은 리소스를 시작하고 계속 실행하려고 시도합니다. “요청된” 리소스 상태를 구성할 수 있습니다. 예를 들어 HA 스택이 리소스를 중지하도록 할 수 있습니다.
# ha-manager set vm:100 --state stopped
나중에 다시 시작하세요.
# ha-manager set vm:100 --state started
일반 VM 및 컨테이너 관리 명령을 사용할 수도 있습니다. 명령을 HA 스택에 자동으로 전달하므로
# qm start 100
단순히 요청된 상태를 시작됨으로 설정합니다. 요청된 상태를 중지됨으로 설정하는 qm stop에도 동일하게 적용됩니다.
참고 HA 스택은 완전히 비동기식으로 작동하며 다른 클러스터 구성원과 통신해야 합니다. 따라서 해당 작업의 결과를 볼 때까지 몇 초가 걸립니다.
현재 HA 리소스 구성을 보려면 다음을 사용하세요.
# ha-manager config
vm:100
state stopped또한 다음을 사용하여 실제 HA 관리자 및 리소스 상태를 볼 수 있습니다.
# ha-manager status quorum OK master node1 (active, Wed Nov 23 11:07:23 2016) lrm elsa (active, Wed Nov 23 11:07:19 2016) service vm:100 (node1, started)
다른 노드로의 리소스 마이그레이션을 시작할 수도 있습니다.
# ha-manager migrate vm:100 node2
이는 온라인 마이그레이션을 사용하고 VM 실행을 유지하려고 시도합니다. 온라인 마이그레이션은 사용된 모든 메모리를 네트워크를 통해 전송해야 하므로 VM을 중지했다가 새 노드에서 다시 시작하는 것이 더 빠른 경우도 있습니다. 이는 relocate 명령을 사용하여 수행할 수 있습니다.
# ha-manager relocate vm:100 node2
마지막으로 다음 명령을 사용하여 HA 구성에서 리소스를 제거할 수 있습니다.
# ha-manager remove vm:100
참고: 이렇게 하면 리소스가 시작되거나 중지되지 않습니다.
하지만 모든 HA 관련 작업은 GUI에서 수행할 수 있으므로 명령줄을 사용할 필요가 전혀 없습니다.
15.4. 작동 방식
이 섹션에서는 Proxmox VE HA 관리자 내부에 대한 자세한 설명을 제공합니다. 관련된 모든 데몬과 이들이 함께 작동하는 방식을 설명합니다. HA를 제공하기 위해 각 노드에서 두 개의 데몬이 실행됩니다.
pve-ha-lrm
로컬 노드에서 실행되는 서비스를 제어하는 LRM(로컬 리소스 관리자). 현재 관리자 상태 파일에서 해당 서비스에 대해 요청된 상태를 읽고 해당 명령을 실행합니다.
pve-ha-crm
클러스터 전체에 대한 결정을 내리는 CRM(클러스터 리소스 관리자). LRM에 명령을 보내고 결과를 처리하며 문제가 발생하면 리소스를 다른 노드로 이동합니다. CRM은 노드 펜싱도 처리합니다.
메모: LRM 및 CRM의 잠금
잠금은 분산 구성 파일 시스템(pmxcfs)에서 제공됩니다. 이는 각 LRM이 한 번 활성화되고 작동하도록 보장하는 데 사용됩니다. LRM은 잠금을 보유하고 있을 때만 작업을 실행하므로 잠금을 획득할 수 있으면 실패한 노드를 차단된 노드로 표시할 수 있습니다. 그러면 현재 알려지지 않은 실패한 노드의 간섭 없이 실패한 HA 서비스를 안전하게 복구할 수 있습니다. 이 모든 것은 현재 관리자 마스터 잠금을 보유하고 있는 CRM에 의해 감독됩니다.
15.4.1. 서비스 상태
CRM은 서비스 상태 열거를 사용하여 현재 서비스 상태를 기록합니다. 이 상태는 GUI에 표시되며 ha-manager 명령줄 도구를 사용하여 쿼리할 수 있습니다.
# ha-manager status quorum OK master elsa (active, Mon Nov 21 07:23:29 2016) lrm elsa (active, Mon Nov 21 07:23:22 2016) service ct:100 (elsa, stopped) service ct:102 (elsa, started) service vm:501 (elsa, started)
가능한 상태 목록은 다음과 같습니다.
stopped
서비스가 중지되었습니다(LRM에서 확인). LRM은 중지된 서비스가 여전히 실행 중임을 감지하면 해당 서비스를 다시 중지합니다.
request_stop
서비스를 중지해야 합니다. CRM은 LRM의 확인을 기다립니다.
stopping
중지 요청이 보류 중입니다. 그러나 CRM은 지금까지 요청을 받지 못했습니다.
started
서비스가 활성 상태이므로 LRM이 아직 실행 중이 아닌 경우 최대한 빨리 시작해야 합니다. 서비스가 실패하고 실행 중이 아닌 것으로 감지되면 LRM이 서비스를 다시 시작합니다(시작 실패 정책 참조).
starting
시작 요청이 보류 중입니다. 그러나 CRM은 LRM으로부터 서비스가 실행 중이라는 확인을 받지 못했습니다.
fence
서비스 노드가 할당량 클러스터 파티션 내부에 있지 않으므로 노드 펜싱을 기다립니다(펜싱 참조). 노드가 성공적으로 차단되면 서비스는 복구 상태로 전환됩니다.
recovery
서비스 복구를 기다립니다. HA 관리자는 서비스가 실행될 수 있는 새 노드를 찾으려고 합니다. 이 검색은 온라인 및 할당 노드 목록뿐 아니라 서비스가 그룹 구성원인지 여부와 해당 그룹이 어떻게 제한되는지에 따라 달라집니다. 사용 가능한 새 노드가 발견되자마자 서비스는 그곳으로 이동되고 처음에는 중지된 상태가 됩니다. 새 노드를 실행하도록 구성된 경우 해당 노드가 실행됩니다.
freeze
서비스 상태를 만지지 마십시오. 노드를 재부팅하거나 LRM 데몬을 다시 시작할 때 이 상태를 사용합니다(패키지 업데이트 참조).
ignored
HA가 서비스를 전혀 관리하지 않는 것처럼 행동합니다. HA 구성에서 서비스를 제거하지 않고 일시적으로 서비스에 대한 전체 제어가 필요할 때 유용합니다.
migrate
서비스(라이브)를 다른 노드로 마이그레이션합니다.
error
LRM 오류로 인해 서비스가 비활성화되었습니다. 수동 개입이 필요합니다(오류 복구 참조).
queued
서비스가 새로 추가되었는데 CRM에서는 아직까지 본 적이 없습니다.
disabled
서비스가 중지되고 비활성화된 것으로 표시됩니다.
15.4.2. 로컬 리소스 관리자
로컬 리소스 관리자(pve-ha-lrm)는 부팅 시 데몬으로 시작되고 HA 클러스터가 할당되어 클러스터 전체 잠금이 작동할 때까지 기다립니다.
세 가지 상태일 수 있습니다.
wait for agent lock
LRM은 독점 잠금을 기다립니다. 서비스가 구성되지 않은 경우 유휴 상태로도 사용됩니다.
active
LRM은 배타적 잠금을 보유하고 서비스가 구성되어 있습니다.
lost agent lock
LRM이 잠금을 잃었습니다. 이는 오류가 발생하여 쿼럼이 손실되었음을 의미합니다.
LRM이 활성 상태가 된 후 /etc/pve/ha/manager_status에 있는 관리자 상태 파일을 읽고 자신이 소유한 서비스에 대해 실행해야 하는 명령을 결정합니다. 작업자가 시작되는 각 명령에 대해 이러한 작업자는 병렬로 실행되며 기본적으로 최대 4개로 제한됩니다. 이 기본 설정은 데이터 센터 구성 키 max_worker를 통해 변경할 수 있습니다. 완료되면 작업자 프로세스가 수집되고 그 결과가 CRM에 저장됩니다.
메모: 최대 동시 작업자 조정 팁
최대 4명의 동시 작업자라는 기본값은 특정 설정에 적합하지 않을 수 있습니다. 예를 들어 4개의 실시간 마이그레이션이 동시에 발생할 수 있으며 이로 인해 느린 네트워크 및/또는 대규모(메모리 측면) 서비스로 인해 네트워크 정체가 발생할 수 있습니다. 또한 최악의 경우 max_worker 값을 낮추더라도 정체가 최소인지 확인하세요. 반대로, 특히 강력하고 고급 설정이 있는 경우 이를 늘리는 것이 좋습니다.
CRM에서 요청한 각 명령은 UID로 고유하게 식별할 수 있습니다. 작업자가 완료되면 해당 결과가 처리되어 LRM 상태 파일 /etc/pve/nodes//lrm_status에 기록됩니다. 그곳에서 CRM은 이를 수집하고 명령 출력과 관련된 상태 시스템이 이에 대해 작동하도록 할 수 있습니다.
CRM과 LRM 간의 각 서비스에 대한 작업은 일반적으로 항상 동기화됩니다. 이는 CRM이 UID로 고유하게 표시된 상태를 요청하고 LRM이 이 작업을 한 번 실행한 후 동일한 UID로 식별할 수 있는 결과를 다시 기록한다는 의미입니다. 이는 LRM이 오래된 명령을 실행하지 않도록 하기 위해 필요합니다. 이 동작에 대한 유일한 예외는 중지 및 오류 명령입니다. 이 두 가지는 생성된 결과에 의존하지 않으며 중지된 상태의 경우 항상 실행되고 오류 상태의 경우 한 번 실행됩니다.
메모: 로그 읽기
HA 스택은 수행하는 모든 작업을 기록합니다. 이는 클러스터에서 어떤 일이 발생하는지, 왜 발생하는지 이해하는 데 도움이 됩니다. 여기서는 LRM과 CRM 두 데몬이 수행한 작업을 확인하는 것이 중요합니다. 서비스가 있는 노드에서 Journalctl -u pve-ha-lrm을 사용하고 현재 마스터인 노드의 pve-ha-crm에 대해 동일한 명령을 사용할 수 있습니다.
15.4.3. 클러스터 리소스 관리자
클러스터 리소스 관리자(pve-ha-crm)는 각 노드에서 시작되어 한 번에 하나의 노드에서만 보유할 수 있는 관리자 잠금을 기다립니다. 관리자 잠금을 성공적으로 획득한 노드는 CRM 마스터로 승격됩니다.
세 가지 상태일 수 있습니다.
wait for agent lock
CRM은 독점 잠금을 기다립니다. 서비스가 구성되지 않은 경우 유휴 상태로도 사용됩니다.
active
CRM은 독점 잠금을 보유하고 서비스가 구성되어 있습니다.
lost agent lock
CRM이 잠금을 잃었습니다. 이는 오류가 발생하여 쿼럼이 손실되었음을 의미합니다.
주요 작업은 고가용성으로 구성된 서비스를 관리하고 항상 요청된 상태를 적용하는 것입니다. 예를 들어, 요청된 상태가 시작된 서비스는 아직 실행 중이 아닌 경우 시작됩니다. 충돌이 발생하면 자동으로 다시 시작됩니다. 따라서 CRM은 LRM이 실행해야 하는 작업을 지시합니다.
노드가 클러스터 쿼럼을 벗어나면 해당 상태는 알 수 없음으로 변경됩니다. 현재 CRM이 실패한 노드의 잠금을 보호할 수 있으면 서비스가 도난당하고 다른 노드에서 다시 시작됩니다.
클러스터 구성원이 더 이상 클러스터 쿼럼에 없다고 판단하면 LRM은 새 쿼럼이 형성될 때까지 기다립니다. 쿼럼이 없는 한 노드는 워치독을 재설정할 수 없습니다. 그러면 워치독 시간이 초과된 후(60초 후에 발생) 재부팅이 트리거됩니다.
15.5. HA 시뮬레이터
HA 시뮬레이터를 사용하면 Proxmox VE HA 솔루션의 모든 기능을 테스트하고 배울 수 있습니다.
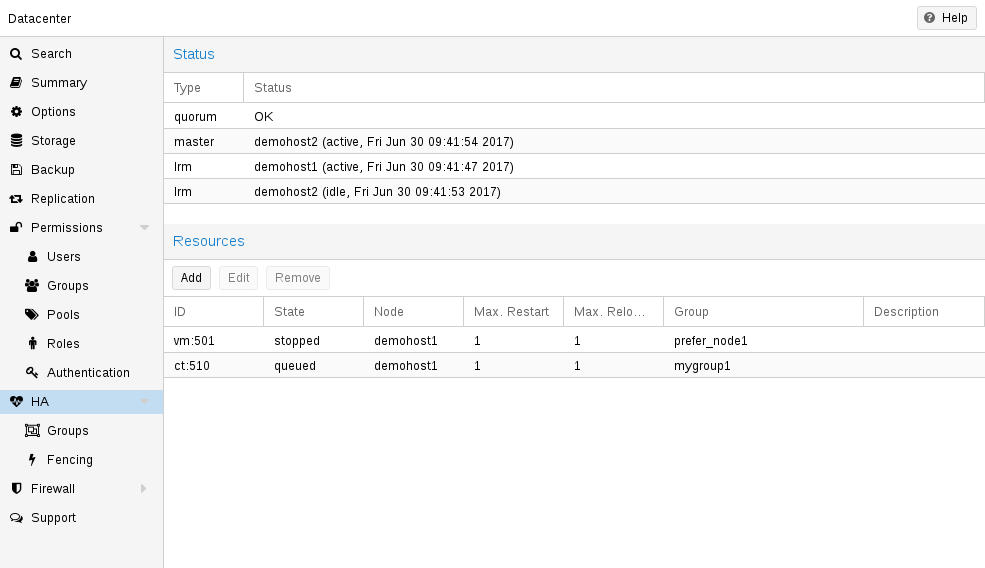
기본적으로 시뮬레이터를 사용하면 6개의 VM이 있는 실제 3노드 클러스터의 동작을 관찰하고 테스트할 수 있습니다. 추가 VM 또는 컨테이너를 추가하거나 제거할 수도 있습니다.
실제 클러스터를 설정하거나 구성할 필요가 없으며 HA 시뮬레이터는 즉시 실행됩니다.
apt로 설치:
apt install pve-ha-simulator
다른 Proxmox VE 패키지 없이 Debian 기반 시스템에 패키지를 설치할 수도 있습니다. 이를 위해서는 패키지를 다운로드하고 설치를 위해 실행하려는 시스템에 복사해야 합니다. 로컬 파일 시스템에서 apt를 사용하여 패키지를 설치하면 필요한 종속성도 해결됩니다.
원격 시스템에서 시뮬레이터를 시작하려면 현재 시스템에 대한 X11 리디렉션이 있어야 합니다.
Linux 시스템을 사용하는 경우 다음을 사용할 수 있습니다.
ssh root@<IPofPVE> -Y
Windows에서는 mobaxterm과 함께 작동합니다.
시뮬레이터가 설치된 기존 Proxmox VE에 연결하거나 로컬 데비안 기반 시스템에 수동으로 설치한 후 다음과 같이 시험해 볼 수 있습니다.
먼저 시뮬레이터가 현재 상태를 저장하고 기본 구성을 작성하는 작업 디렉터리를 만들어야 합니다.
mkdir working
그런 다음 생성된 디렉터리를 pve-ha-simulator에 매개 변수로 전달하기만 하면 됩니다.
pve-ha-simulator working/
그런 다음 시뮬레이션된 HA 서비스를 시작, 중지, 마이그레이션하거나 노드 오류 시 어떤 일이 발생하는지 확인할 수도 있습니다.
15.6. 구성
HA 스택은 Proxmox VE API에 잘 통합되어 있습니다. 예를 들어 HA는 ha-manager 명령줄 인터페이스 또는 Proxmox VE 웹 인터페이스를 통해 구성할 수 있습니다. 두 인터페이스 모두 HA를 관리하는 쉬운 방법을 제공합니다. 자동화 도구는 API를 직접 사용할 수 있습니다.
모든 HA 구성 파일은 /etc/pve/ha/ 내에 있으므로 클러스터 노드에 자동으로 배포되며 모든 노드는 동일한 HA 구성을 공유합니다.
15.6.1. 자원
리소스 구성 파일 /etc/pve/ha/resources.cfg에는 ha-manager가 관리하는 리소스 목록이 저장됩니다. 해당 목록 내의 리소스 구성은 다음과 같습니다.
<type>: <name>
<property> <value>
...리소스 유형으로 시작하고 그 뒤에 콜론으로 구분된 리소스별 이름이 옵니다. 이는 함께 리소스를 고유하게 식별하기 위해 모든 ha-manager 명령에서 사용되는 HA 리소스 ID를 형성합니다(예: vm:100 또는 ct:101). 다음 줄에는 추가 속성이 포함되어 있습니다.
comment:
Description.
group:
The HA group identifier.
max_relocate: (0 – N) (default = 1)
Maximal number of service relocate tries when a service failes to start.
max_restart: (0 – N) (default = 1)
Maximal number of tries to restart the service on a node after its start failed.
state: (default = started)
Requested resource state. The CRM reads this state and acts accordingly. Please note that enabled is just an alias for started.
started
The CRM tries to start the resource. Service state is set to started after successful start. On node failures, or when start fails, it tries to recover the resource. If everything fails, service state it set to error.
stopped
The CRM tries to keep the resource in stopped state, but it still tries to relocate the resources on node failures.
disabled
The CRM tries to put the resource in stopped state, but does not try to relocate the resources on node failures. The main purpose of this state is error recovery, because it is the only way to move a resource out of the error state.
ignored
The resource gets removed from the manager status and so the CRM and the LRM do not touch the resource anymore. All {pve} API calls affecting this resource will be executed, directly bypassing the HA stack. CRM commands will be thrown away while there source is in this state. The resource will not get relocated on node failures.다음은 하나의 VM과 하나의 컨테이너를 사용하는 실제 사례입니다. 보시다시피 해당 파일의 구문은 매우 간단하므로 즐겨 사용하는 편집기를 사용하여 해당 파일을 읽거나 편집하는 것도 가능합니다.
구성 예(/etc/pve/ha/resources.cfg)
vm: 501
state started
max_relocate 2
ct: 102
# Note: use default settings for everything위 구성은 ha-manager 명령줄 도구를 사용하여 생성되었습니다
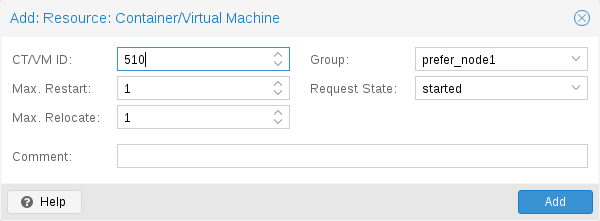
# ha-manager add vm:501 --state started --max_relocate 2 # ha-manager add ct:102
15.6.2. 그룹
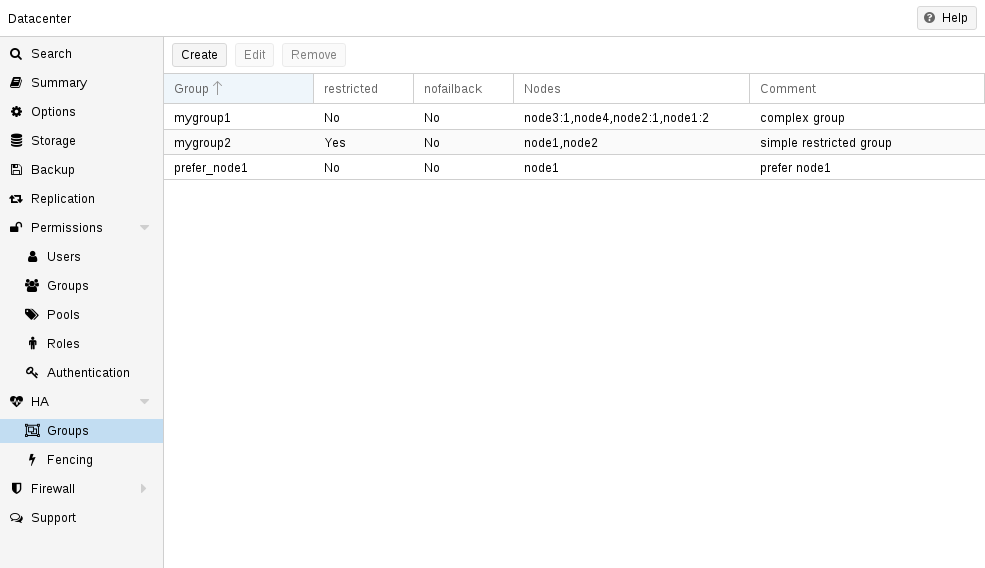
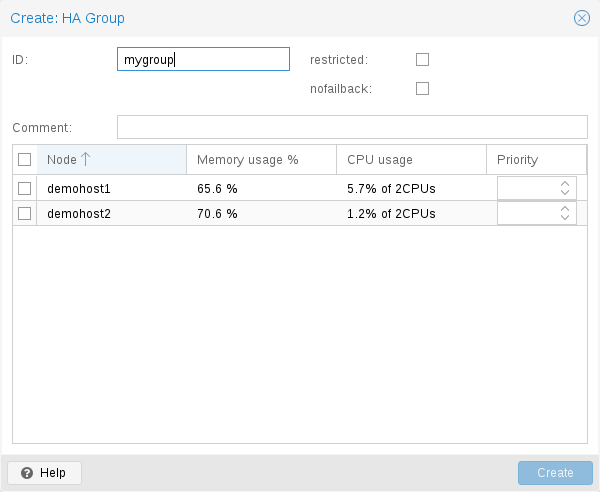
HA 그룹 구성 파일 /etc/pve/ha/groups.cfg는 클러스터 노드 그룹을 정의하는 데 사용됩니다. 리소스는 해당 그룹의 구성원에서만 실행되도록 제한될 수 있습니다. 그룹 구성은 다음과 같습니다.
group: <group>
nodes <node_list>
<property> <value>
...
comment:
설명.
nodes: [:]{,[:]}*
각 노드에 우선순위를 부여할 수 있는 클러스터 노드 구성원 목록입니다. 그룹에 바인딩된 리소스는 우선 순위가 가장 높은 사용 가능한 노드에서 실행됩니다. 우선순위가 가장 높은 클래스에 더 많은 노드가 있는 경우 서비스는 해당 노드에 배포됩니다. 우선순위는 상대적인 의미만 갖습니다.
nofailback: (default = 0)
CRM은 우선 순위가 가장 높은 노드에서 서비스를 실행하려고 합니다. 우선 순위가 더 높은 노드가 온라인 상태가 되면 CRM은 서비스를 해당 노드로 마이그레이션합니다. nofailback을 활성화하면 해당 동작이 방지됩니다.
restricted: (default = 0)
제한된 그룹에 바인딩된 리소스는 해당 그룹에서 정의한 노드에서만 실행될 수 있습니다. 그룹 노드 구성원이 온라인 상태가 아닌 경우 리소스는 중지된 상태가 됩니다. 제한되지 않은 그룹의 리소스는 모든 그룹 구성원이 오프라인인 경우 모든 클러스터 노드에서 실행될 수 있지만 그룹 구성원이 온라인이 되는 즉시 다시 마이그레이션됩니다. 구성원이 한 명뿐인 무제한 그룹을 사용하여 선호 노드 동작을 구현할 수 있습니다.
일반적인 요구 사항은 리소스가 특정 노드에서 실행되어야 한다는 것입니다. 일반적으로 리소스는 다른 노드에서 실행될 수 있으므로 단일 구성원으로 제한되지 않은 그룹을 정의할 수 있습니다.
# ha-manager groupadd prefer_node1 --nodes node1
더 큰 클러스터의 경우 더 자세한 장애 조치 동작을 정의하는 것이 좋습니다. 예를 들어, 가능하다면 node1에서 일련의 서비스를 실행하려고 할 수 있습니다. node1을 사용할 수 없는 경우 node2와 node3에서 균등하게 분할하여 실행하려고 합니다. 해당 노드에도 오류가 발생하면 서비스는 node4에서 실행되어야 합니다. 이를 달성하려면 노드 목록을 다음과 같이 설정할 수 있습니다.
# ha-manager groupadd mygroup1 -nodes "node1:2,node2:1,node3:1,node4"
또 다른 사용 사례는 리소스가 특정 노드에서만 사용할 수 있는 다른 리소스(예: node1 및 node2)를 사용하는 경우입니다. HA 관리자가 다른 노드를 사용하지 않는지 확인해야 하므로 해당 노드로 제한된 그룹을 만들어야 합니다.
# ha-manager groupadd mygroup2 -nodes "node1,node2" -restricted
위의 명령은 다음 그룹 구성 파일을 생성했습니다.
구성 예(/etc/pve/ha/groups.cfg)
group: prefer_node1
nodes node1
group: mygroup1
nodes node2:1,node4,node1:2,node3:1
group: mygroup2
nodes node2,node1
restricted 115.7. 펜싱
노드 장애 시 펜싱은 오류가 있는 노드가 오프라인이 되도록 보장합니다. 이는 다른 노드에서 복구될 때 리소스가 두 번 실행되지 않도록 하기 위해 필요합니다. 이는 매우 중요한 작업입니다. 이 작업이 없으면 다른 노드의 리소스를 복구할 수 없기 때문입니다.
노드가 차단되지 않은 경우, 공유 리소스에 계속 액세스할 수 있는 알 수 없는 상태가 됩니다. 이건 정말 위험해요! 스토리지 네트워크를 제외한 모든 네트워크가 고장났다고 상상해 보십시오. 이제 공용 네트워크에서 연결할 수 없지만 VM은 계속 실행되어 공유 스토리지에 씁니다.
그런 다음 다른 노드에서 이 VM을 시작하면 두 노드 모두에서 쓰기 때문에 위험한 경쟁 조건이 발생합니다. 이러한 조건은 모든 VM 데이터를 파괴할 수 있으며 전체 VM을 사용할 수 없게 될 수 있습니다. 스토리지가 여러 마운트로부터 보호되는 경우에도 복구가 실패할 수 있습니다.
15.7.1. Proxmox VE 펜싱 사용 방법
노드를 차단하는 방법에는 여러 가지가 있습니다. 예를 들어, 노드의 전원을 차단하거나 통신을 완전히 비활성화하는 장치를 차단하는 방법이 있습니다. 이는 비용이 많이 들고 추가로 중요한 구성 요소를 시스템에 가져오는 경우가 많습니다. 장애가 발생하면 서비스를 복구할 수 없기 때문입니다.
따라서 우리는 추가 외부 하드웨어가 필요하지 않은 보다 간단한 펜싱 방법을 통합하고 싶었습니다. 이는 감시 타이머를 사용하여 수행할 수 있습니다.
가능한 펜싱 방법
- 외부 전원 스위치
- 스위치에서 전체 네트워크 트래픽을 비활성화하여 노드를 격리합니다.
- 워치독 타이머를 사용한 자체 펜싱
워치독 타이머는 마이크로컨트롤러가 시작된 이래로 중요하고 신뢰할 수 있는 시스템에 널리 사용되어 왔습니다. 이는 컴퓨터 오작동을 감지하고 복구하는 데 사용되는 단순하고 독립적인 집적 회로인 경우가 많습니다.
정상 작동 중에 ha-manager는 감시 타이머가 경과되지 않도록 정기적으로 재설정합니다. 하드웨어 결함이나 프로그램 오류로 인해 컴퓨터가 워치독을 재설정하지 못하는 경우 타이머가 경과하고 전체 서버 재설정(재부팅)이 트리거됩니다.
최신 서버 마더보드에는 이러한 하드웨어 감시 장치가 포함되어 있는 경우가 많지만 이를 구성해야 합니다. 워치독을 사용할 수 없거나 구성하지 않은 경우 Linux 커널 소프트독으로 대체됩니다. 여전히 안정적이지만 서버 하드웨어에 독립적이지 않으므로 하드웨어 감시자보다 신뢰성이 낮습니다.
15.7.2. 하드웨어 워치독 구성
기본적으로 모든 하드웨어 감시 모듈은 보안상의 이유로 차단됩니다. 올바르게 초기화되지 않으면 장전된 총과 같습니다. 하드웨어 워치독을 활성화하려면 /etc/default/pve-ha-manager에 로드할 모듈을 지정해야 합니다. 예:
# select watchdog module (default is softdog) WATCHDOG_MODULE=iTCO_wdt
이 구성은 시작 시 지정된 모듈을 로드하는 watchdog-mux 서비스에서 읽습니다.
15.7.3. 분리된 서비스 복구
노드가 실패하고 해당 노드의 펜싱이 성공한 후 CRM은 실패한 노드에서 아직 온라인 상태인 노드로 서비스를 이동하려고 시도합니다.
해당 서비스가 복구되는 노드 선택은 리소스 그룹 설정, 현재 활성 노드 목록 및 해당 활성 서비스 수의 영향을 받습니다.
CRM은 먼저 사용자가 선택한 노드(그룹 설정에서)와 사용 가능한 노드 간의 교차점에서 세트를 구축합니다. 그런 다음 우선 순위가 가장 높은 노드의 하위 집합을 선택하고 마지막으로 활성 서비스 수가 가장 낮은 노드를 선택합니다. 이렇게 하면 노드가 오버로드될 가능성이 최소화됩니다.
주의: 노드 오류가 발생하면 CRM은 나머지 노드에 서비스를 배포합니다. 이로 인해 해당 노드의 서비스 수가 증가하고 특히 소규모 클러스터에서 높은 로드가 발생할 수 있습니다. 이러한 최악의 시나리오를 처리할 수 있도록 클러스터를 설계하십시오.
15.8. 시작 실패 정책
시작 실패 정책은 서비스가 노드에서 한 번 이상 시작되지 못한 경우 적용됩니다. 동일한 노드에서 다시 시작을 트리거해야 하는 빈도와 서비스를 재배치해야 하는 빈도를 구성하여 다른 노드에서 시작을 시도하는 데 사용할 수 있습니다. 이 정책의 목적은 특정 노드에서 공유 리소스를 일시적으로 사용할 수 없는 상황을 방지하는 것입니다. 예를 들어, 네트워크 문제로 인해 할당량 노드에서 공유 저장소를 더 이상 사용할 수 없지만 다른 노드에서는 여전히 사용할 수 있는 경우에도 재배치 정책을 통해 서비스가 시작되도록 허용합니다.
각 리소스에 대해 구체적으로 구성할 수 있는 두 가지 서비스 시작 복구 정책 설정이 있습니다.
max_restart
실제 노드에서 실패한 서비스를 다시 시작하려는 최대 시도 횟수입니다. 기본값은 1로 설정되어 있습니다.
max_relocate
서비스를 다른 노드로 재배치하려는 최대 시도 횟수입니다. 재배치는 실제 노드에서 max_restart 값을 초과한 후에만 발생합니다. 기본값은 1로 설정되어 있습니다.
참고: 재배치 횟수 상태는 서비스가 적어도 한 번 성공적으로 시작된 경우에만 0으로 재설정됩니다. 즉, 오류를 수정하지 않고 서비스를 다시 시작하면 다시 시작 정책만 반복됩니다.
15.9. 오류 복구
모든 시도 후에도 서비스 상태를 복구할 수 없으면 오류 상태가 됩니다. 이 상태에서는 서비스가 더 이상 HA 스택의 영향을 받지 않습니다. 유일한 방법은 서비스를 비활성화하는 것입니다.
# ha-manager set vm:100 --state disabled
이 작업은 웹 인터페이스에서도 수행할 수 있습니다.
오류 상태에서 복구하려면 다음을 수행해야 합니다.
- 리소스를 안전하고 일관된 상태로 되돌립니다. (예: 서비스를 중지할 수 없는 경우 해당 프로세스를 종료합니다.)
- 오류 플래그를 제거하려면 리소스를 비활성화하세요.
- 이 실패로 이어진 오류를 수정하세요.
- 모든 오류를 수정한 후 서비스를 다시 시작하도록 요청할 수 있습니다.
15.10. 패키지 업데이트
ha-manager를 업데이트할 때 여러 가지 이유로 한 번에 모두 수행하지 말고 한 노드를 차례로 수행해야 합니다. 첫째, 소프트웨어를 철저히 테스트하는 동안 특정 설정에 영향을 미치는 버그를 완전히 배제할 수는 없습니다. 한 노드를 차례로 업데이트하고 업데이트를 마친 후 각 노드의 기능을 확인하는 것은 최종 문제를 복구하는 데 도움이 되지만, 한꺼번에 업데이트하면 클러스터가 손상될 수 있으므로 일반적으로 좋은 방법은 아닙니다.
또한 Proxmox VE HA 스택은 요청 확인 프로토콜을 사용하여 클러스터와 로컬 리소스 관리자 간의 작업을 수행합니다. 다시 시작하기 위해 LRM은 CRM에 모든 서비스를 중지하도록 요청합니다. 이렇게 하면 LRM이 다시 시작되는 짧은 시간 동안 클러스터에 의해 접촉되는 것을 방지할 수 있습니다. 그 후 LRM은 다시 시작하는 동안 워치독을 안전하게 닫을 수 있습니다. 이러한 다시 시작은 일반적으로 패키지 업데이트 중에 발생하며 이미 설명한 대로 LRM의 요청을 승인하려면 활성 마스터 CRM이 필요합니다. 그렇지 않은 경우 업데이트 프로세스가 너무 오래 걸릴 수 있으며 최악의 경우 워치독에 의해 재설정이 트리거될 수 있습니다.
15.11. 노드 유지 관리
하드웨어를 교체하거나 단순히 새 커널 이미지를 설치하는 등 노드에서 유지 관리를 수행해야 하는 경우도 있습니다. 이는 HA 스택이 사용되는 동안에도 적용됩니다.
HA 스택은 주로 두 가지 유형의 유지 관리를 지원할 수 있습니다.
일반적인 종료 또는 재부팅의 경우 동작을 구성할 수 있습니다. 종료 정책을 참조하세요.
종료 또는 재부팅이 필요하지 않거나 한 번의 재부팅 후에 자동으로 꺼지지 않아야 하는 유지 관리의 경우 수동 유지 관리 모드를 활성화할 수 있습니다.
15.11.1. 유지 관리 모드
수동 유지 관리 모드를 사용하면 노드를 HA 작업에 사용할 수 없는 것으로 표시하고 HA에서 관리하는 모든 서비스에 다른 노드로 마이그레이션하라는 메시지를 표시할 수 있습니다.
이러한 마이그레이션의 대상 노드는 현재 사용 가능한 다른 노드에서 선택되며 HA 그룹 구성 및 구성된 CRS(클러스터 리소스 스케줄러) 모드에 따라 결정됩니다. 각 마이그레이션 중에 원래 노드는 HA 관리자 상태로 기록되므로 유지 관리 모드가 비활성화되고 노드가 다시 온라인 상태가 되면 서비스가 자동으로 다시 이전될 수 있습니다.
현재 ha-manager CLI 도구를 사용하여 유지 관리 모드를 활성화하거나 비활성화할 수 있습니다.
노드에 대한 유지 관리 모드 활성화
# ha-manager crm-command node-maintenance enable NODENAME
이는 CRM 명령을 대기열에 추가하고, 관리자가 이 명령을 처리할 때 관리자 상태에 유지 관리 모드에 대한 요청을 기록합니다. 이를 통해 유지 관리 모드에 들어가거나 해당 모드에서 벗어나려는 노드뿐만 아니라 모든 노드에서 명령을 제출할 수 있습니다.
해당 노드의 LRM이 명령을 선택하면 자체적으로 사용할 수 없는 것으로 표시되지만 여전히 모든 마이그레이션 명령을 처리합니다. 즉, LRM 자체 보호 감시 장치는 모든 활성 서비스가 이동되고 실행 중인 모든 작업자가 완료될 때까지 활성 상태를 유지합니다.
LRM 상태는 LRM이 요청된 상태를 선택하자마자 유지 관리 모드를 읽습니다. 모든 서비스가 이동되었을 때뿐만 아니라 이 사용자 경험은 향후 개선될 예정입니다. 지금은 노드에 남아 있는 활성 HA 서비스를 확인하거나 다음과 같은 로그 줄을 관찰하여 노드가 유지 관리로의 전환을 완료한 시기를 알 수 있습니다. 방법.
참고: 수동 유지 관리 모드는 노드 재부팅 시 자동으로 삭제되지 않으며, ha-manager CLI를 사용하여 수동으로 비활성화하거나 관리자 상태를 수동으로 삭제하는 경우에만 삭제됩니다.
노드의 유지 관리 모드 비활성화
# ha-manager crm-command node-maintenance disable NODENAME
수동 유지 관리 모드를 비활성화하는 과정은 활성화하는 과정과 비슷합니다. 위에 표시된 ha-manager CLI 명령을 사용하면 처리된 후 해당 LRM 노드를 다시 사용 가능한 것으로 표시하는 CRM 명령이 대기열에 추가됩니다.
유지 관리 모드를 비활성화하면 유지 관리 모드가 활성화되었을 때 노드에 있던 모든 서비스가 다시 이동됩니다.
15.11.2. 종료 정책
아래에는 노드 종료에 대한 다양한 HA 정책에 대한 설명이 나와 있습니다. 현재는 이전 버전과의 호환성으로 인해 조건부가 기본값입니다. 일부 사용자는 Migrate가 예상대로 더 많이 작동한다는 것을 알 수 있습니다.
종료 정책은 웹 UI(Datacenter → Options → HA Settings)에서 구성하거나 datacenter.cfg에서 직접 구성할 수 있습니다.
ha: shutdown_policy=<value>
Migrate
LRM(로컬 리소스 관리자)이 종료 요청을 받고 이 정책이 활성화되면 현재 HA 관리자에서 사용할 수 없는 것으로 표시됩니다. 그러면 현재 이 노드에 있는 모든 HA 서비스의 마이그레이션이 트리거됩니다. LRM은 실행 중인 모든 서비스가 사라질 때까지 종료 프로세스를 지연시키려고 합니다. 그러나 이는 실행 중인 서비스가 다른 노드로 마이그레이션될 수 있다고 예상합니다. 즉, 하드웨어 패스스루 등을 사용하여 서비스를 로컬로 바인딩해서는 안 됩니다. 그룹 구성원이 아닌 노드는 그룹 구성원이 없는 경우 실행 가능한 대상으로 간주되므로 일부 노드만 선택한 상태에서 HA 그룹을 사용하는 경우에도 이 정책을 사용할 수 있습니다. 그러나 그룹을 제한됨으로 표시하면 HA 관리자에게 선택한 노드 집합 외부에서 서비스를 실행할 수 없음을 알립니다. 해당 노드를 모두 사용할 수 없는 경우 수동으로 개입할 때까지 종료가 중단됩니다. 종료된 노드가 다시 온라인 상태가 되면 이전에 대체된 서비스가 중간에 수동으로 마이그레이션되지 않은 경우 다시 이동됩니다.
참고: 워치독은 종료 시 마이그레이션 프로세스 중에 계속 활성 상태입니다. 노드가 쿼럼을 잃으면 차단되고 서비스가 복구됩니다.
현재 유지 관리 중인 노드에서 (이전에 중지된) 서비스를 시작하는 경우 해당 서비스를 다른 사용 가능한 노드에서 이동하고 시작할 수 있도록 노드를 펜싱해야 합니다.
Failover
이 모드를 사용하면 모든 서비스가 중지되지만 현재 노드가 곧 온라인 상태가 아닐 경우 서비스도 복구됩니다. 한 번에 너무 많은 노드의 전원이 꺼지면 VM 실시간 마이그레이션이 불가능할 수 있지만 가능한 한 빨리 HA 서비스가 복구되고 다시 시작되도록 하기 위해 클러스터 규모에서 유지 관리를 수행할 때 유용할 수 있습니다.
Freeze
이 모드는 모든 서비스가 중지되고 동결되어 현재 노드가 다시 온라인 상태가 될 때까지 복구되지 않도록 합니다.
Conditional
조건부 종료 정책은 종료 또는 재부팅이 요청되었는지 자동으로 감지하고 이에 따라 동작을 변경합니다.
Shutdown
종료(전원 끄기)는 일반적으로 노드가 일정 시간 동안 작동 중지 상태를 유지하도록 계획된 경우 수행됩니다. 이 경우 LRM은 모든 관리 서비스를 중지합니다. 이는 나중에 다른 노드가 해당 서비스를 인수한다는 의미입니다.
참고: 최신 하드웨어에는 대용량 메모리(RAM)가 있습니다. 따라서 모든 리소스를 중지한 다음 다시 시작하여 모든 RAM의 온라인 마이그레이션을 방지합니다. 온라인 마이그레이션을 사용하려면 노드를 종료하기 전에 수동으로 호출해야 합니다.
Reboot
노드 재부팅은 reboot 명령으로 시작됩니다. 이는 일반적으로 새 커널을 설치한 후에 수행됩니다. 노드가 즉시 다시 시작되므로 이는 “shotdown”와 다릅니다.
LRM은 CRM에 다시 시작하고 싶다고 알리고 CRM이 모든 리소스를 고정 상태로 전환할 때까지 기다립니다(패키지 업데이트에도 동일한 메커니즘이 사용됨). 이렇게 하면 해당 리소스가 다른 노드로 이동되는 것을 방지할 수 있습니다. 대신 CRM은 동일한 노드에서 재부팅 후 리소스를 시작합니다.
수동 자원 이동
마지막으로, 노드를 종료하거나 다시 시작하기 전에 수동으로 리소스를 다른 노드로 이동할 수도 있습니다. 장점은 모든 권한을 갖고 있으며 온라인 마이그레이션을 사용할지 여부를 결정할 수 있다는 것입니다.
참고: pve-ha-crm, pve-ha-lrm 또는 watchdog-mux와 같은 서비스를 종료하지 마십시오. Watchdog을 관리하고 사용하므로 즉시 노드를 재부팅하거나 재설정할 수도 있습니다.
15.12. 클러스터 리소스 스케줄링
CRS(클러스터 리소스 스케줄러) 모드는 HA가 서비스 복구 및 종료 정책에 의해 트리거되는 마이그레이션을 위해 노드를 선택하는 방법을 제어합니다. 기본 모드는 기본 모드이며 웹 UI(데이터 센터 → 옵션)에서 변경하거나 datacenter.cfg에서 직접 변경할 수 있습니다.
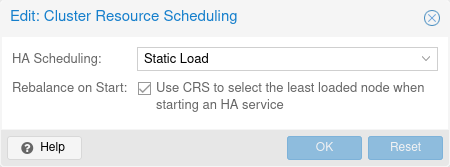
crs: ha=static
변경 사항은 다음 관리자 라운드(몇 초 후)부터 적용됩니다.
복구 또는 마이그레이션해야 하는 각 서비스에 대해 스케줄러는 서비스 그룹에서 우선 순위가 가장 높은 노드 중에서 가장 적합한 노드를 반복적으로 선택합니다.
참고: 향후 (정적 및 동적) 로드 밸런싱을 위한 모드를 추가할 계획이 있습니다.
15.12.1. 기본 스케줄러
각 노드의 활성 HA 서비스 수는 복구 노드를 선택하는 데 사용됩니다. 비HA 관리 서비스는 현재 계산되지 않습니다.
15.12.2. 정적 부하 스케줄러
중요: 정적 모드는 아직 기술 미리보기입니다.
각 노드에 있는 HA 서비스의 정적 사용량 정보를 사용하여 복구 노드를 선택합니다. HA가 관리하지 않는 서비스의 사용은 현재 고려되지 않습니다.
이 선택의 경우 각 노드는 관련 게스트 구성의 CPU 및 메모리 사용량을 사용하여 서비스가 이미 실행 중인 것처럼 간주됩니다. 그런 다음 이러한 각 대안에 대해 모든 노드의 CPU 및 메모리 사용량이 고려되며, 메모리는 실제로 제한된 리소스이기 때문에 훨씬 더 많은 가중치를 갖습니다. CPU와 메모리 모두에 대해 노드 간 최고 사용량(이상적으로 오버 커밋된 노드가 없어야 하므로 가중치가 더 높음)과 모든 노드의 평균 사용량(커밋률이 더 높은 노드가 이미 있는 경우 여전히 구별할 수 있음)이 고려됩니다.
중요: 서비스가 많을수록 가능한 조합도 많아지므로 현재 수천 개의 HA 관리형 서비스가 있는 경우에는 사용하지 않는 것이 좋습니다.
15.12.3. CRS 스케줄링 포인트
CRS 알고리즘은 매 라운드의 모든 서비스에 적용되지 않습니다. 이는 지속적인 마이그레이션이 많이 발생하기 때문입니다. 워크로드에 따라 이는 지속적인 균형 조정으로 피할 수 있는 것보다 클러스터에 더 많은 부담을 줄 수 있습니다. 이것이 Proxmox VE HA 관리자가 현재 노드에 서비스를 유지하는 것을 선호하는 이유입니다.
CRS는 현재 다음 일정 지점에서 사용됩니다.
서비스 복구(항상 활성) 활성 HA 서비스가 있는 노드에 장애가 발생하면 모든 서비스를 다른 노드로 복구해야 합니다. 여기서는 CRS 알고리즘을 사용하여 나머지 노드에 대한 복구 균형을 맞춥니다.
HA 그룹 구성 변경(항상 활성) 노드가 그룹에서 제거되거나 우선 순위가 낮아지면 HA 스택은 CRS 알고리즘을 사용하여 해당 그룹의 HA 서비스에 대한 새 대상 노드를 찾고 적응된 우선 순위 제약 조건과 일치합니다.
HA 서비스 중지 → 전환 시작(옵트인) 중지된 서비스를 시작하도록 요청하는 것은 CRS 알고리즘에 따라 가장 적합한 노드를 확인할 수 있는 좋은 기회입니다. 특히 해당 디스크 볼륨이 공유 스토리지에 있는 경우 중지된 서비스를 이동하는 것이 시작된 서비스를 이동하는 것보다 저렴하기 때문입니다. 데이터 센터 구성에서 ha-rebalance-on-start CRS 옵션을 설정하여 이를 활성화할 수 있습니다. 웹 UI의 Datacenter → Options → Cluster Resource Scheduling에서 해당 옵션을 변경할 수도 있습니다.