
새로운 vSphere 8 CPU Topology Device Assignment 기능에 대해 약간의 오해가 있는 것 같습니다. 이 기사를 통해 이 기능을 사용하는 시기를 이해할 수 있기를 바랍니다. 이 기능은 가상 PCIe 디바이스를 vNUMA 토폴로지에 매핑하는 것을 정의합니다. 주요 목적은 게스트 OS 및 애플리케이션 최적화를 최적화하는 것입니다. 이 설정은 물리적 리소스 계층에서 vCPU 및 메모리 인접성의 NUMA 선호도 및 스케줄링에 영향을 주지 않습니다. 이는 VM 배치 정책(best effort)을 기반으로 합니다. 이제 설정과 가상 시스템에 미치는 영향을 살펴보겠습니다. 먼저 기본적인 것부터 살펴보도록 하죠. 이 기능은 가상 시스템의 VM Options 메뉴에 있습니다.
CPU Topology 클릭
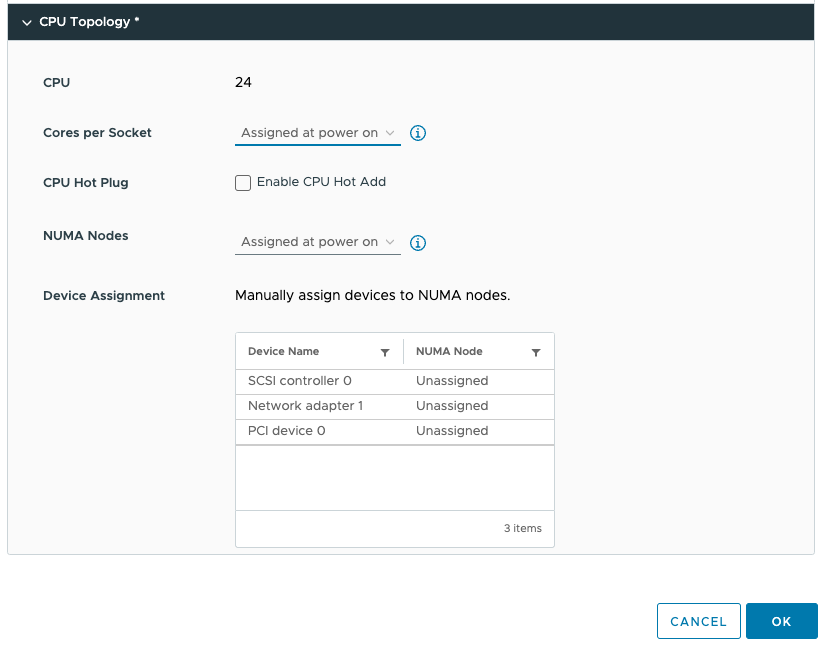
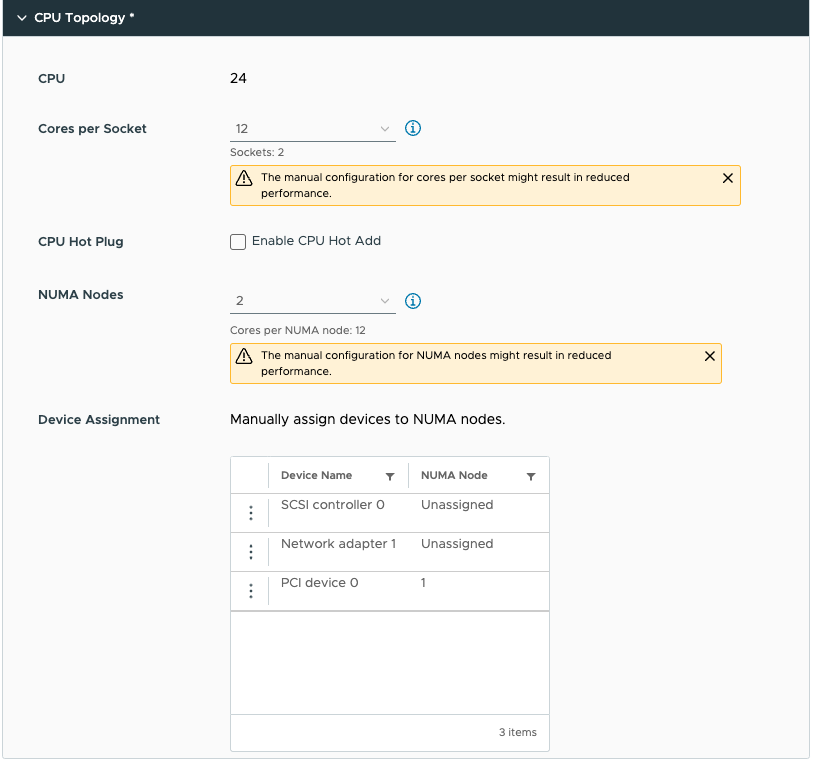
기본적으로 소켓당 코어 수 및 NUMA 노드 설정은 “Assigned at power on”되므로 PCI 디바이스를 NUMA 노드에 할당할 수 없습니다. PCI 디바이스를 NUMA 노드에 할당하려면 소켓당 코어 수 설정을 변경해야 합니다. 소켓당 코어 수를 잘못 구성하면 성능이 저하될 수 있으므로 즉시 작업 내용을 알아야 한다는 경고가 표시됩니다. 일반적으로 소켓당 코어 수를 서버의 물리적 레이아웃에 맞추는 것이 좋습니다. 저의 경우 ESXi 호스트 시스템은 이중 소켓 서버이며 각 CPU 패키지에는 20개의 코어가 포함되어 있습니다. 기본적으로 NUMA 스케줄러는 NUMA 클라이언트 크기 조정을 위해 vCPU를 코어에 매핑하므로 이 VM 구성은 단일 물리적 NUMA 노드에 적합할 수 없습니다. NUMA 스케줄러는 vCPU를 두 NUMA 클라이언트에 균등하게 분산하므로 NUMA 노드(소켓)당 12개의 vCPU가 배치됩니다. 따라서 소켓당 코어 수 구성은 소켓당 12개의 코어로 구성되어야 하며, 이는 해당 VM에 대해 두 개의 가상 소켓을 생성하도록 ESXi에 알립니다. 완전성을 위해 두 개의 NUMA 노드도 지정했습니다. 이 설정은 PER-VM 설정이며 소켓당 NUMA 노드가 아닙니다. ESXi에서는 소켓당 코어 수 설정을 기반으로 vNUMA 토폴로지를 생성하므로 이 설정을 기본 설정으로 쉽게 유지할 수 있습니다. 응용프로그램에 절대적으로 필요한 펑키 토폴로지를 생성하려는 경우가 아니라면요. 애플리케이션 개발자가 달리 요청하지 않는 한 가능한 기본 설정으로 유지하는 것이 좋습니다.
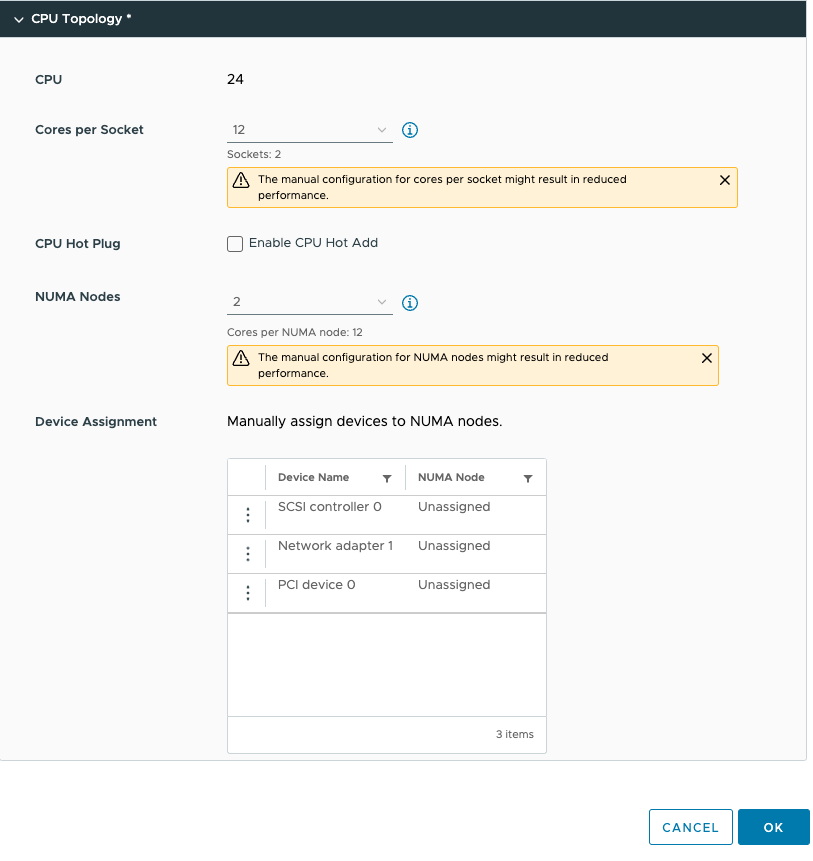
이를 통해 PCIe 장치를 구성할 수 있습니다. 눈치채셨겠지만 PCIe 장치를 추가했습니다. 이 장치는 Dynamic Direct Path I/O(패스스루) 모드의 NVIDIA A30 GPU입니다. 그러나 이 디바이스의 세부 정보를 살펴보기 전에 게스트 OS 내에서 가상 시스템의 구성을 살펴보겠습니다. Ubuntu 22.04 LTS를 설치하고 lstopo 명령을 사용했습니다. (설치 방법: sudo apt install hwloc)
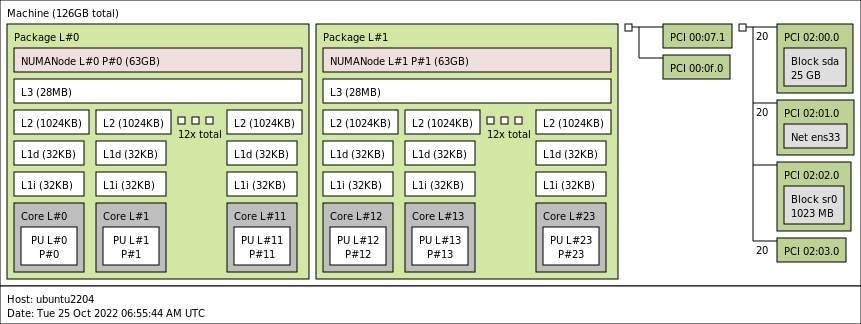
각각 12개의 vCPU(코어)와 별도의 PCI 구조를 가진 두 개의 NUMA 노드가 표시됩니다. 이것이 가상 마더보드의 구조입니다. 이를 물리적 시스템과 비교해 보면 각 PCI 디바이스가 NUMA 노드 내에 있는 PCI 컨트롤러에 연결되어 있습니다.
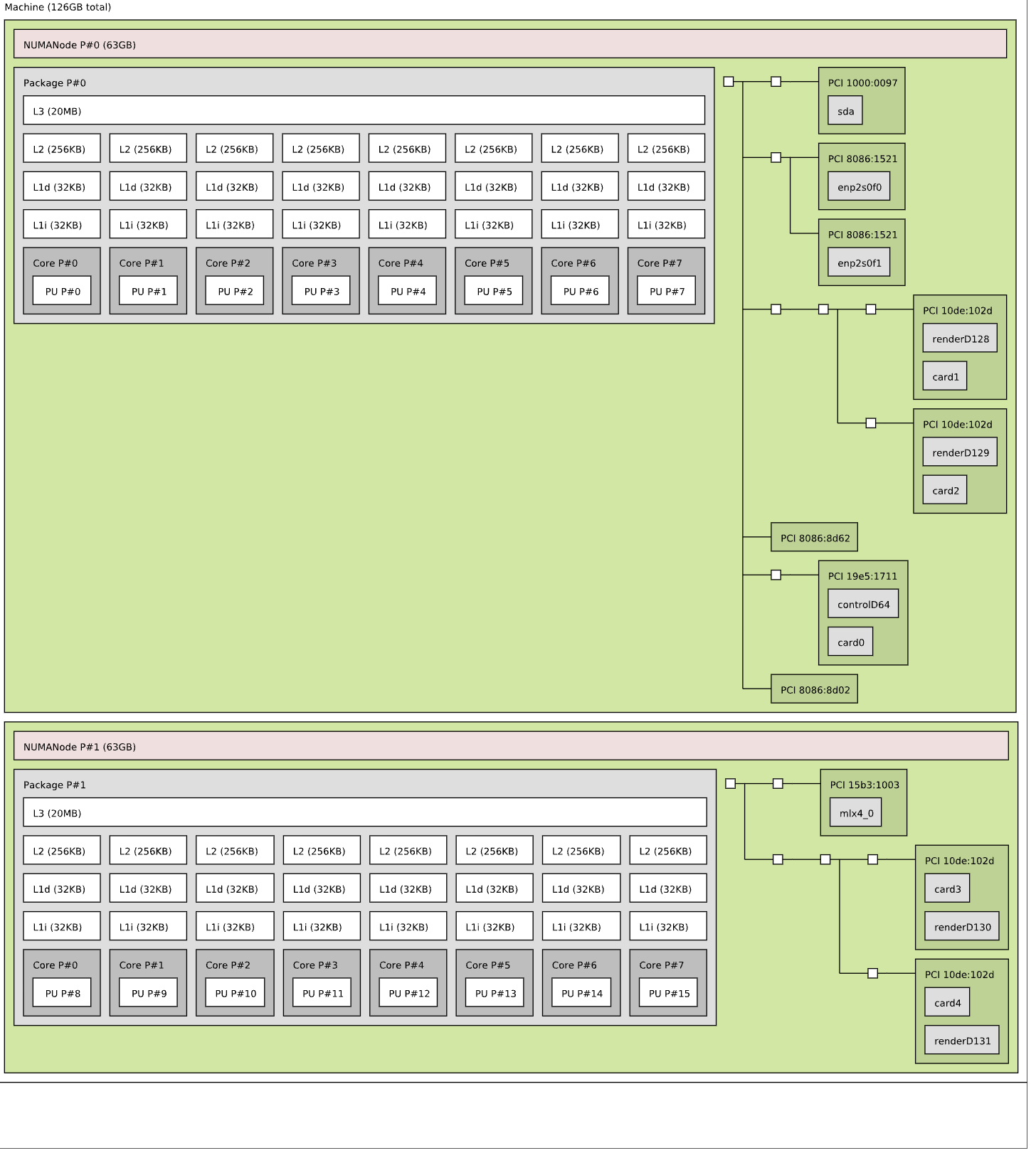
vSphere 8의 Device Assignment 기능을 사용하면 바로 이러한 작업을 수행할 수 있습니다. 게스트 OS와 애플리케이션이 이 정보를 필요로 하는 경우 더 많은 통찰력을 제공할 수 있습니다. 일반적으로 이러한 최적화는 필요하지 않지만 일부 특정 네트워크 로드 밸런싱 알고리즘 또는 시스템 학습 사용 사례의 경우 애플리케이션이 PCIe 디바이스의 NUMA PCI 인접성을 이해하도록 합니다.
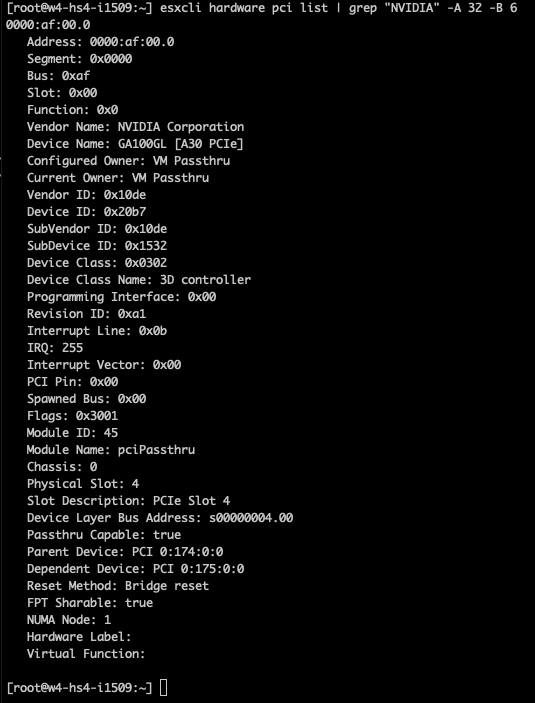
A30의 경우 PCIe-NUMA locality을 이해해야 합니다. 가장 쉬운 방법은 SSH 세션을 통해 ESXi 서버에 로그온하고 esxcli hardware pci list 명령을 통해 디바이스를 검색하는 것입니다. NVIDIA 장치를 검색할 때 “esxcli hardware pci list | grep “NVIDIA -A 32 -B 6” 명령을 사용하여 이 명령의 출력을 제한할 수 있습니다. 이 명령은 grep 명령이 NVIDIA 라인 뒤에 32줄(A), NVIDIA 라인 앞에 6줄(B)을 출력하도록 지시합니다. 출력에 따르면 A30 카드는 NUMA 노드 1(아래에서 세 번째 줄)에 있는 PCI 컨트롤러에서 관리됩니다.
이제 디바이스 할당을 적절하게 조정하고 NUMA 노드 1에 할당할 수 있습니다. 이 기능을 사용하면 NUMA 노드 0에도 할당할 수 있습니다. 당신은 여기서 혼자예요. 당신은 바보 같은 짓을 할 수 있어요. 하지만 할 수 있다고 해서 그렇게 해야 하는 것은 아니다. 서버 마더보드의 대부분의 PCIe 슬롯은 CPU 소켓에 직접 연결되므로 NIC 또는 GPU와 CPU 사이에 직접적인 물리적 연결이 존재하므로 ESXi 스케줄러 내에서는 이를 논리적으로 변경할 수 없습니다. 가상 세계를 가능한 한 물리적 세계에 가깝게 매핑하여 모든 것을 가능한 한 명확하고 투명하게 유지하는 것이 유일합니다. PCI 디바이스 0(A30)을 NUMA 노드 1에 매핑했습니다.
가상 시스템에서 lstopo를 실행하면 다음과 같은 결과가 나타납니다.
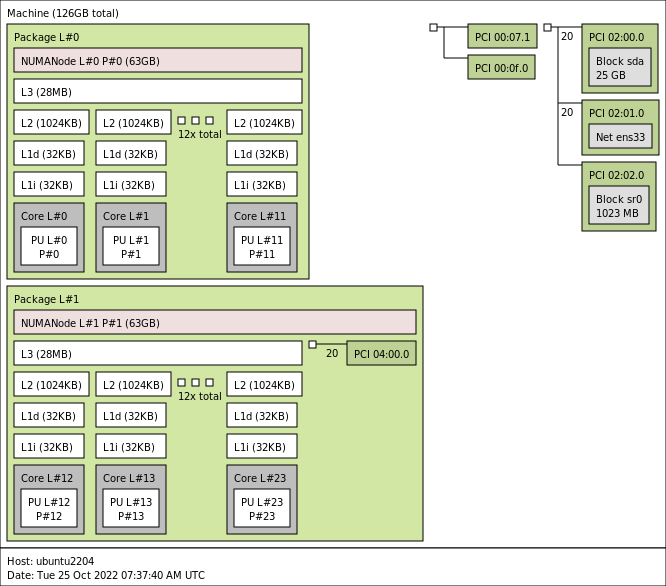
이제 GPU는 NUMA 노드 1의 일부입니다. 패키지 1 내부의 작은 녹색 상자에 지정된 주소 04:00:00에 PCI 디바이스를 가져와서 해당 esxcli 출력의 “Device Layer Bus Address” 줄에 표시된 GPU의 “esxcli hardware pci list”에 지정된 주소와 동일한 주소를 확인합니다. 가상 GPU 디바이스는 이제 NUMA 노드 1의 일부이므로 게스트 OS 메모리 최적화를 통해 NUMA 노드 1 내에 메모리를 할당하여 데이터 세트를 저장하여 디바이스에 최대한 가깝게 할 수 있습니다. NUMA 스케줄러와 ESXi 계층 내의 CPU 및 메모리 스케줄러는 이러한 지침을 최대한 따르려고 합니다. 확실히 하려면 가장 낮은 계층에 NUMA 선호도와 CPU 선호도를 할당할 수 있지만, 가장 낮은 스케줄링 알고리즘에 영향을 미치기 전에 이 계층에서 먼저 테스트하는 것이 좋습니다.
출처 : https://frankdenneman.nl/2022/10/25/vsphere-8-cpu-topology-device-assignment/




