2019.10.06에 NVIDIA Technical Blog에 올라온 글입니다.
AI 및 HPC 데이터 세트의 크기가 계속 증가함에 따라 특정 애플리케이션의 데이터를 로드하는 데 소요되는 시간이 전체 애플리케이션의 성능에 부담을 주기 시작합니다. 엔드투엔드 애플리케이션 성능을 고려할 때, 빠른 GPU는 느린 I/O로 인해 점점 더 많은 제약을 받고 있습니다.
처리를 위해 스토리지에서 GPU로 데이터를 로드하는 프로세스인 I/O는 역사적으로 CPU에 의해 제어되어 왔습니다. 연산이 느린 CPU에서 빠른 GPU로 이동함에 따라 I/O는 전체 애플리케이션 성능에 더 큰 병목 현상이 되고 있습니다.
GPUDirect RDMA(Remote Direct Memory Address)가 네트워크 인터페이스 카드(NIC)와 GPU 메모리 간에 데이터를 직접 이동할 때 대역폭과 지연 시간을 개선한 것처럼, GPUDirect 스토리지라는 새로운 기술을 사용하면 NVMe 또는 NVMe-oF(NVMe over Fabric)와 같은 로컬 또는 원격 스토리지와 GPU 메모리 간에 직접 데이터 경로를 만들 수 있습니다.
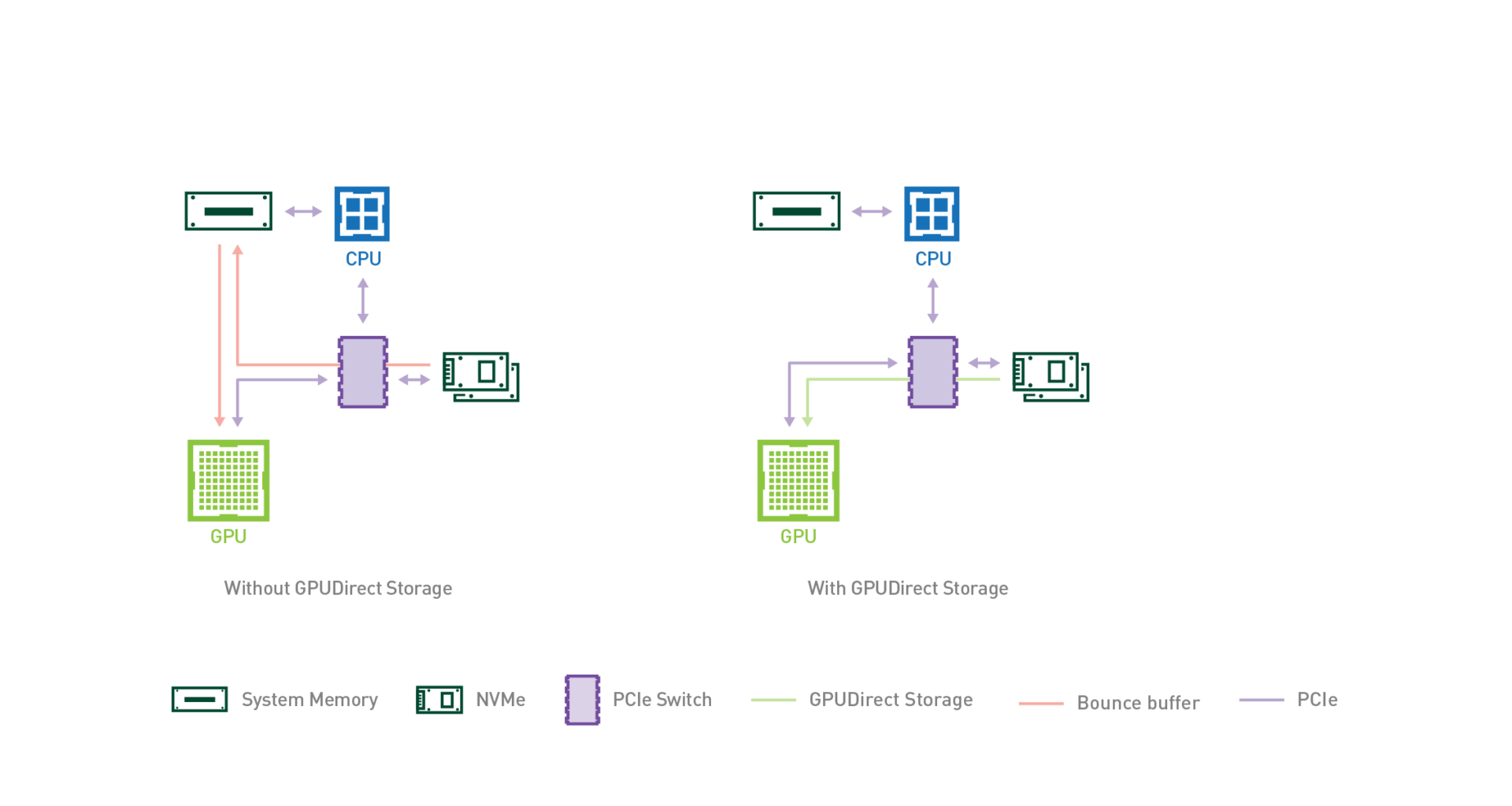
GPUDirect RDMA와 GPUDirect 스토리지는 모두 CPU 메모리의 바운스 버퍼를 통한 추가 복사본을 피하고, NIC 또는 스토리지 근처의 직접 메모리 액세스(DMA) 엔진이 CPU 또는 GPU에 부담을 주지 않고 직접 경로로 데이터를 GPU 메모리 안팎으로 이동할 수 있게 해줍니다(그림 1).

그림 1. GPU 메모리와 NVMe 드라이브 간의 표준 경로는 CPU에서 중단되는 시스템 메모리의 바운스 버퍼를 사용합니다. 스토리지로부터의 직접 데이터 경로는 CPU를 완전히 건너뛰어 더 높은 대역폭을 확보합니다.
GPUDirect Storage의 경우 스토리지 위치는 중요하지 않습니다. 스토리지가 인클로저 내부, 랙 내부 또는 네트워크를 통해 연결되어 있을 수 있습니다. NVIDIA DGX-2의 CPU 시스템 메모리(SysMem)에서 GPU로의 대역폭이 50GB/s로 제한되어 있는 경우, 많은 로컬 드라이브와 여러 NIC의 SysMem 대역폭을 결합하여 DGX-2에서 거의 200GB/s의 대역폭 상한을 달성할 수 있습니다.
이 포스팅에서는 특정 서버에 로컬로 있거나 NVMe-oF를 통해 인클로저 외부에 있는 스토리지에서 직접 메모리 액세스(DMA)를 가능하게 하는 개념 증명인 GPUDirect 스토리지를 시연하는 이전 포스팅을 확장합니다.
- 스토리지에서 GPU로의 직접 메모리 액세스가 CPU I/O 병목현상을 완화하고 I/O 대역폭과 용량을 늘릴 수 있음을 입증합니다.
- 산호세에서 열린 GTC19에서 발표된 초기 성능 지표는 cuDF 라이브러리 내에 포함된 RAPIDS 프로젝트의 GPU 가속 CSV 리더를 기반으로 합니다.
- 더 빠르고 향상된 대역폭, 더 낮은 지연 시간, 스토리지와 GPU 간의 용량 증가를 활용할 수 있는 주요 애플리케이션에 대한 제안을 제공합니다.
향후 포스팅에서는 이 기능이 제품화에 가까워짐에 따라 이를 프로그래밍하는 방법에 대해 설명하겠습니다. 이 기능을 지원하기 위해 CUDA에 새로운 cuFile API 세트가 추가될 예정이며, RAPIDS의 cuDF 라이브러리에도 기본 통합될 예정입니다.
DMA는 어떻게 작동하나요?
PCI Express(PCIe) 인터페이스는 네트워킹 카드, RAID/NVMe 스토리지, GPU와 같은 고속 주변기기를 CPU에 연결합니다. Volta GPU용 시스템 인터페이스인 PCIe Gen3는 총 16GB/s의 최대 대역폭을 제공합니다. 헤더 및 기타 오버헤드의 프로토콜 비효율성을 고려하면 달성 가능한 최대 데이터 속도는 14GB/s 이상입니다.
DMA는 복사 엔진을 사용하여 대용량 데이터 블록을 로드 및 저장하는 대신 PCIe를 통해 비동기적으로 이동합니다. 이는 컴퓨팅 요소를 오프로드하여 다른 작업에 사용할 수 있도록 합니다. GPU와 NVMe 드라이버 및 스토리지 컨트롤러와 같은 스토리지 관련 장치에는 DMA 엔진이 있지만 일반적으로 CPU에는 없습니다.
어떤 경우에는 DMA 엔진을 특정 대상에 맞게 프로그래밍할 수 없습니다. 예를 들어, GPU DMA 엔진은 스토리지를 대상으로 할 수 없습니다. 스토리지 DMA 엔진은 GPUDirect 스토리지가 없는 파일 시스템을 통해 GPU 메모리를 타겟팅할 수 없습니다.
그러나 DMA 엔진은 CPU의 드라이버에 의해 프로그래밍되어야 합니다. CPU가 GPU의 DMA를 프로그래밍하면 CPU에서 GPU로 보내는 명령이 GPU에 대한 다른 명령과 간섭을 일으킬 수 있습니다. NVMe 드라이브 또는 스토리지 근처의 다른 곳에 있는 DMA 엔진을 GPU의 DMA 엔진 대신 사용하여 데이터를 이동할 수 있다면 CPU와 GPU 사이의 경로에서 간섭이 발생하지 않습니다.
GPU의 DMA 엔진과 비교하여 로컬 NVMe 드라이브에서 DMA 엔진을 사용하면 I/O 대역폭이 13.3GB/s로 증가하여 CPU에서 GPU로의 메모리 전송 속도인 12.0GB/s에 비해 약 10%의 성능 향상을 얻을 수 있습니다(표 1).
I/O 병목현상 및 관련 애플리케이션 해결
연구자들이 데이터 분석, AI 및 기타 GPU 가속 애플리케이션을 점점 더 큰 데이터 세트에 적용하고, 그 중 일부는 CPU 메모리나 로컬 스토리지에 완전히 들어가지 않는 경우가 많아지면서 스토리지와 GPU 메모리 사이의 데이터 경로에서 I/O 병목 현상을 완화하는 것이 점점 더 중요해지고 있습니다.
데이터 분석 애플리케이션은 스토리지에서 스트리밍되는 경향이 있는 대량의 데이터를 기반으로 작동합니다. 대부분의 경우, 바이트당 플롭으로 표현되는 연산과 통신의 비율이 매우 낮기 때문에 IO에 종속됩니다.
예를 들어, 딥러닝이 신경망을 성공적으로 학습시키기 위해서는 하루에 각각 10MB 정도의 많은 파일 세트에 액세스하고 여러 번 읽어야 합니다. 이 경우 GPU로의 데이터 전송을 최적화하면 AI 모델 학습에 소요되는 총 시간에 상당한 영향을 미칠 수 있습니다.
데이터 수집 최적화 외에도 딥러닝 학습에는 모델 학습 과정의 여러 단계에서 학습된 네트워크 가중치를 디스크에 저장하는 체크포인트 프로세스가 포함되는 경우가 많습니다. 정의상 체크포인트는 중요한 I/O 경로에 속합니다. 관련 오버헤드를 줄이면 체크포인팅 기간을 단축하고 모델 복구 속도를 높일 수 있습니다.
데이터 분석과 딥 러닝 외에도 네트워크 상호 작용을 연구하는 그래프 분석은 I/O 요구가 높습니다. 그래프를 탐색하여 영향력 있는 노드나 여기서 저기로 가는 최단 경로를 찾을 때, 계산은 전체 해결 시간 중 극히 일부에 불과합니다. 현재 노드에서 다음 노드로 이동할 위치를 파악하려면 페타바이트 크기의 데이터 레이크에서 생성된 파일 하나에서 수백 개의 파일 범위의 I/O 쿼리가 필요할 수 있습니다.
로컬 캐싱은 직접 실행 가능한 데이터를 추적하는 데 도움이 되지만, 그래프 탐색은 보편적으로 지연 시간과 대역폭에 민감합니다. NVIDIA가 RAPIDS cuGraph 라이브러리를 통해 그래프 분석의 GPU 가속화를 확장함에 따라, 파일 I/O 오버헤드를 제거하는 것은 초고속 솔루션을 지속적으로 제공하는 데 매우 중요합니다.
GPU로 확장된 스토리지 및 대역폭 옵션
데이터 분석과 AI의 공통점은 인사이트를 도출하는 데 사용되는 데이터 세트가 방대한 경우가 많다는 것입니다. 16개의 V100 GPU로 구성된 NVIDIA DGX-2에는 30TB의 NVMe SSD 메모리(3.84TB 8개)와 1.5TB의 시스템 메모리가 기본 구성으로 포함되어 있습니다.
드라이브에서 DMA 작업을 활성화하면 대역폭 증가, 지연 시간 감소, 잠재적으로 무제한의 스토리지 용량으로 빠른 메모리 액세스가 가능합니다.
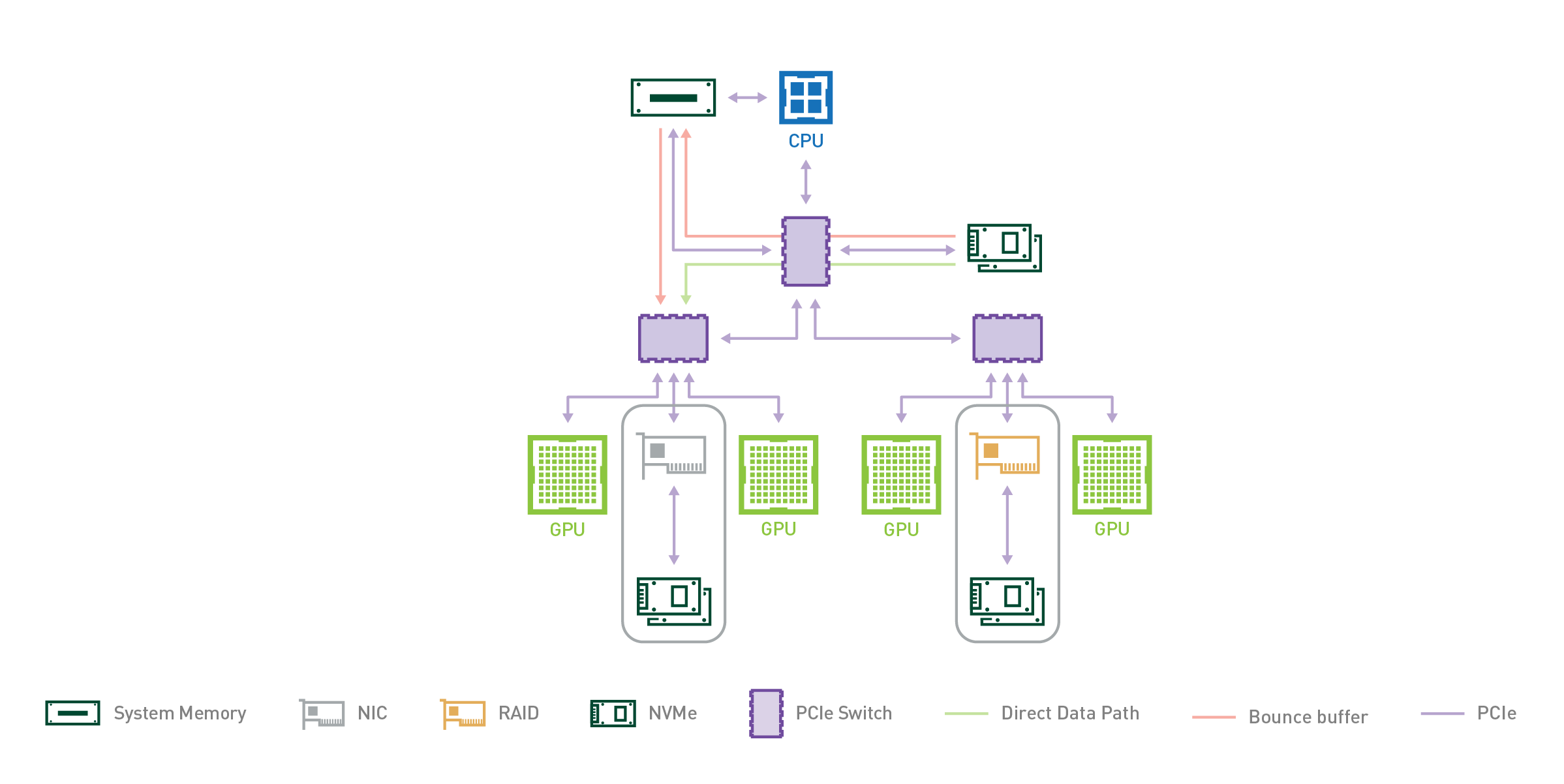
그림 2. 인클로저 외부에서 더 많은 대역폭과 더 많은 스토리지. PCI 스위치에 장착된 NIC를 통해 NVMe-oF 원격 스토리지 확장이 가능하며 RAID 카드를 통해 주변 스토리지를 사용할 수 있습니다. 표시된 RAID 카드는 프로토타입일 뿐이며 현재 또는 향후 출시될 DGX-2 제품을 나타내지 않습니다.
DGX-2 인클로저에는 두 개의 CPU가 포함되어 있으며, 각 CPU에는 그림 2에 표시된 PCIe 서브트리 인스턴스 두 개가 있습니다. 두 레벨의 PCIe 스위치가 지원하는 스토리지 또는 SysMem에서 GPU로의 다중 PCIe 경로는 DGX-2를 GPUDirect 스토리지 프로토타이핑을 위한 좋은 테스트 수단으로 만들어 줍니다.
| Origin to GPU | Bandwidth per PCIe Tree, GB/s | PCIe paths per DGX-2 | Total Bandwidth per DGX-2, GB/s per direction |
| Inside Enclosure – SysMem | 12.0-12.5 | 4 | 48.0-50.0 |
| Inside Enclosure – NVMe | 13.3 | 4 | 53.3 |
| Outside Enclosure – NIC | 10.5 | 8 | 84.0 |
| Outside Enclosure – RAID | 14.0 | 8 | 112.0 |
| Max: SysMem+NVMe+RAID | 215 | ||
| GPUs | >14.4 | 16 | >230 |
표 1. GPU에 대한 DGX-2 대역폭 옵션. 인클로저 내부의 4개의 PCIe 서브트리와 8개의 NIC 또는 RAID 카드.
- 표 1의 왼쪽 열에는 GPU로의 데이터 전송의 다양한 출처가 나열되어 있습니다.
- 두 번째 열에는 해당 소스에서 측정된 대역폭이 나열되어 있습니다.
- 세 번째 열은 이러한 경로의 수를 나타냅니다.
- 네 번째 열은 중간 두 열의 곱으로 해당 소스에서 사용 가능한 총 대역폭을 나타냅니다.
4개의 PCIe 트리 각각에 대해 CPU의 시스템 메모리(SysMem)에서 12~12.5GB/s의 경로가 하나씩 있고, 각 PCIe 트리에 연결된 드라이브의 4분의 1에서 13.3GB/s의 경로가 하나씩 있습니다.
DGX-2에는 GPU 한 쌍당 하나의 PCIe 슬롯이 있습니다. 이 슬롯은 10.5GB/s로 측정된 NIC 또는 이 게시물에 사용된 프로토타입의 경우 14GB/s로 측정된 RAID 카드가 차지할 수 있습니다.
NVMe-oF(오버 패브릭)는 예를 들어 인피니밴드 네트워크를 통해 원격 스토리지에 도달하기 위해 NIC를 사용하는 일반적인 프로토콜입니다. 모든 소스에 걸쳐 추가된 PCIe 대역폭의 오른쪽 열은 8개의 PCIe 슬롯(그림 2의 PCIe 서브트리당 2개)에 RAID 카드를 사용하는 경우 215GB/s로 합산할 수 있습니다. 대신 해당 슬롯에 NIC를 사용하면 합계는 더 낮아집니다.
GPUDirect 스토리지의 주요 이점 중 하나는 인클로저 내부 또는 외부, 시스템 메모리 또는 NVMe 드라이브에 상주하는 빠른 데이터 액세스가 다양한 소스에 걸쳐 추가적으로 제공된다는 것입니다. 내부 NVMe 및 시스템 메모리를 사용한다고 해서 NVMe-oF 또는 RAID 스토리지의 사용이 배제되는 것은 아닙니다.
마지막으로, 이러한 대역폭은 양방향이므로 분산 스토리지에서 데이터를 가져오거나 로컬 디스크에 캐싱할 수 있는 복잡한 작업을 수행할 수 있습니다. CPU 시스템 메모리에서 공유되는 데이터 구조를 통해 CPU와 협업하여 총 대역폭이 GPU 피크 IO의 90% 이상에 달할 수도 있습니다. 이 세 가지 소스 각각에 대한 읽기와 쓰기가 동시에 발생할 수 있습니다.
그림 3은 다양한 소스를 색상으로 구분하고 추가 조합을 누적 막대로 표시합니다. 열 레이블에는 소스 인스턴스 수가 괄호 안에 표시되어 있습니다(예: 16개의 NVMe 드라이브 또는 NVMe-oF를 수행하는 8개의 NIC). 각 옵션에서 사용 가능한 대략적인 용량은 열 레이블의 마지막에 표시됩니다.

그림 3. 다양한 소스의 대역폭 제한으로 인한 추가적 영향
GPU 가속 CSV 리더 사례 연구
NVIDIA가 지원하는 RAPIDS 오픈 소스 소프트웨어는 엔드투엔드 GPU 가속 데이터 과학에 중점을 두고 있습니다. 하나의 라이브러리인 cuDF는 팬더와 유사한 경험을 제공하며, GPU에서 데이터 세트를 로드, 필터링, 조인, 정렬 및 탐색할 수 있도록 지원합니다.
NVIDIA 엔지니어들은 GPUDirect Storage to GPU를 활용하여 네이티브 cuDF CSV 리더보다 8.8배의 처리량 속도와 cuDF 라이브러리가 사용하도록 업데이트된 현재 최선의 구현보다 1.5배의 속도 향상을 제공할 수 있었습니다(그림 4).

그림 4는 하단의 녹색으로 표시된 원래(0.7) cuDF csv_reader 구현이 SysMem에서 GPU로의 오류, 스토리지에서 SysMem으로의 오류, CPU 바운스 버퍼를 통한 고정되지 않은 데이터 이동이 발생하여 GPU 동시성에 따라 확장되지 않았음을 보여줍니다. 현재 RAPIDS와 함께 제공되는 수정된 바운스 버퍼 구현은 가용성이 가장 좋은 메모리 관리를 사용하며 명시적인 데이터 이동은 노란색으로 표시됩니다. 워밍업된 페이지 캐시에서 데이터를 읽는 것은 빨간색 점선으로 표시되어 있으며, 파란색으로 표시된 GPUDirect 스토리지는 NVMe 드라이브 속도에 의해서만 제한되지만 이 모든 것을 능가합니다. 이 측정은 8개의 GPU와 8개의 NVMe 드라이브로만 수행되었습니다.
또한, 직접 데이터 경로는 80GB의 데이터에서 엔드투엔드 지연 시간을 3.8배 단축했습니다. 그림 5에 표시된 16개의 GPU를 대상으로 한 또 다른 cuDF CSV 리더 연구에서 읽기 대역폭은 파란색의 오류 없는 직접 데이터 경로가 빨간색의 바운스 버퍼를 여전히 사용하는 개선된 직접 cuDF 동작이나 노란색의 원래 동작보다 더 원활하고 예측 가능하며 지연 시간이 더 짧았습니다.

그림 5는 CPU 바운스 버퍼가 폴팅(노란색)이 있는 기존 cuDF 버전에서 사용되었을 때 GPU에 따른 지연 시간이 고르지 않고 불안정했다는 것을 보여줍니다. 이후 cuDF는 직접 전송(빨간색)을 통해 폴팅을 제거하도록 최적화되어 성능과 안정성이 향상되었습니다. GPUDirect Storage(파란색)는 추가 GPU로 처리를 확장할 때 원활하고 예측 가능한 지연 시간을 제공합니다.
대역폭 및 CPU 부하 연구
그림 6은 다양한 전송 방법으로 달성할 수 있는 상대적 대역폭을 강조합니다. 데이터는 버퍼링된 I/O를 사용하여 스토리지에서 CPU 메모리로 전송하고 파일 시스템의 페이지 캐시(노란색 선)를 사용하여 유지할 수 있습니다.
페이지 캐시를 사용하면 CPU 메모리 내에 추가 복사본이 생기는 등 약간의 오버헤드가 발생하지만, 전송 크기가 DMA 프로그래밍을 상각할 수 있을 만큼 커질 때까지 스토리지에서 데이터를 DMA하고 바운스 버퍼(빨간색 선)를 사용하는 것과 비교하면 이점이 있습니다. GPUDirect 스토리지(파란색 선)를 사용하는 스토리지와 GPU 간의 대역폭은 CPU와 GPU 간의 대역폭보다 훨씬 높기 때문에 어떤 전송 크기에서도 이점이 있습니다.
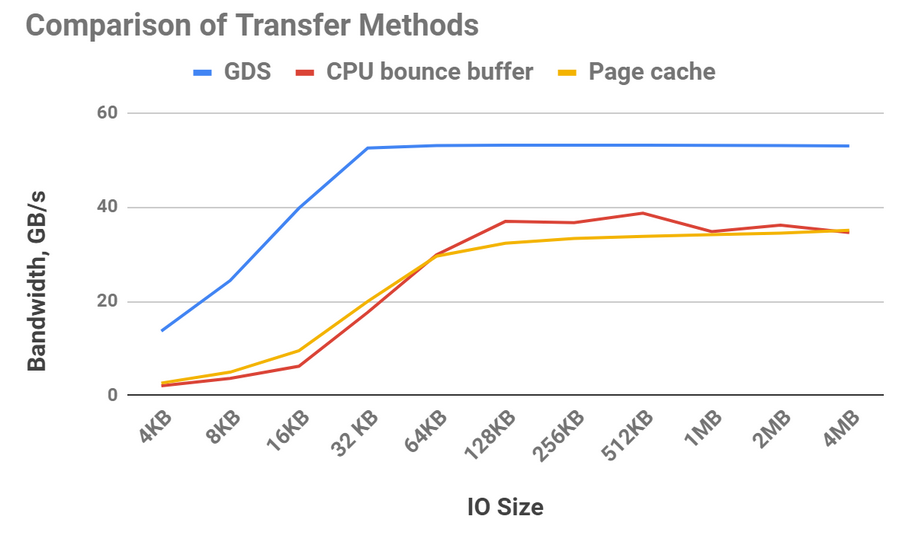
그림 6. 바운스 버퍼(CPU_GPU)를 사용하거나 버퍼링된 IO로 파일 시스템의 페이지 캐시를 활성화하는 것보다 GPUDirect 스토리지(GDS)의 대역폭이 훨씬 더 우수합니다. 16개의 NVMe 드라이브와 16개의 GPU가 사용되었습니다.
더 높은 대역폭을 확보하는 것도 중요하지만, 일부 애플리케이션은 CPU 부하에 민감합니다. 이 세 가지 접근 방식의 대역폭을 CPU 사용률로 나누면 그림 7과 같이 훨씬 더 극적인 결과를 얻을 수 있습니다.

그림 7. 대역폭을 CPU 코어의 부분 사용률로 나눈 값. GPUDirect 스토리지는 더 큰 전송 크기에서 CPU에 훨씬 적은 부담을 줍니다.
TPC-H 사례 연구
TPC-H는 의사 결정 지원 벤치마크입니다. 이 벤치마크에는 많은 쿼리가 있으며, 대량의 데이터를 스트리밍하고 해당 데이터의 GPU에서 일부 처리를 수행하는 쿼리 4(Q4)에 중점을 두었습니다.
데이터의 크기는 스케일 팩터(SF)에 의해 결정됩니다. 스케일 팩터 1K는 거의 1TB(82.4GB의 바이너리 데이터)에 달하는 데이터 세트 크기를 의미하며, 10K는 CPU 메모리에 완전히 들어갈 수 없는 10배를 의미합니다. GPUDirect 스토리지를 사용하지 않는 경우 CPU 메모리의 공간을 할당하고, 디스크에서 채우고, 나중에 해제해야 하는데, 이 모든 작업은 데이터가 소비될 때마다 필요할 때 GPU 메모리로 직접 전송할 수 있다면 무의미한 시간이 소요됩니다.
그림 8은 GPUDirect 스토리지를 사용할 때와 사용하지 않을 때 성능이 크게 향상되는 것을 보여줍니다: SF 1K의 경우 6.7배, SF 10K의 경우 32.8배입니다.
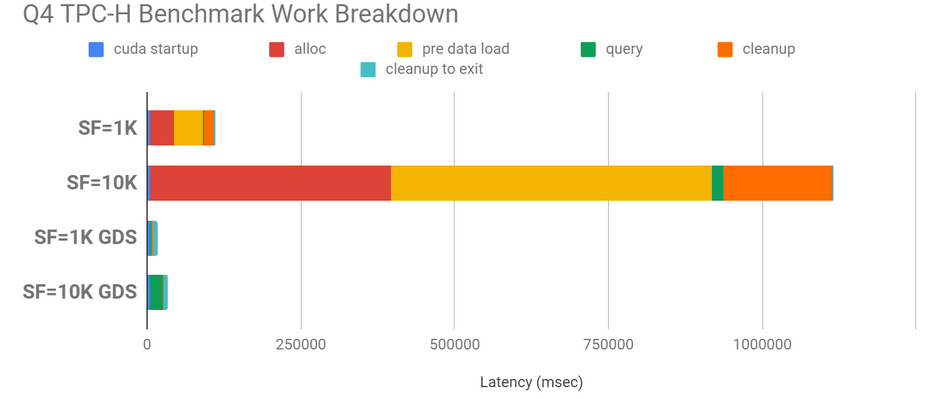
그림 8에서는 1K(~1TB) 및 10K(~10TB)의 스케일 팩터(SF)가 사용되었으며 속도는 각각 4.9배 및 19.6배 향상되었습니다. CPU 메모리의 반복 할당, 메모리에 데이터 로드, CPU 측 메모리 해제는 GPUDirect 스토리지 사례에서 피할 수 있는 큰 병목 현상입니다.
데이터 조작 사례 연구
스토리지에서 GPU로의 직접 경로는 GPU의 프레임 버퍼에 완전히 맞지 않는 데이터 세트에도 적용 가능합니다.
한 실험에서 NVIDIA는 DGX-2의 1TB 입력 데이터 세트와 512GB의 총 GPU 메모리를 사용하여 메모리 초과 구독이 발생하더라도 데이터 I/O가 16개 GPU보다 빠르다는 것을 GPUDirect 스토리지로 입증했습니다. 호스트 메모리.
데이터를 직접 읽고 쓰면 속도가 2배 향상되지만, 더 작은 배치를 사용하는 청크 및 기타 최적화를 통해 속도가 더욱 향상됩니다. 전체적으로 GPUDirect Storage는 데이터 조작 속도를 4.3배 향상시켰습니다.
GPUDirect Storage의 가치
GPUDirect Storage가 제공하는 주요 기능은 이 파일 시스템을 통해 스토리지에서 GPU 메모리로 DMA를 가능하게 한다는 것입니다. 이는 여러 가지 방법으로 가치를 제공합니다.
- 스토리지와 GPU 간 직접 데이터 전송으로 대역폭이 2배~8배 더 높아졌습니다.
- 오류가 없고 바운스 버퍼를 거치지 않는 명시적 데이터 전송은 지연 시간도 낮습니다. 엔드투엔드 지연 시간이 3.8배 더 낮은 예를 시연했습니다.
- 명시적 및 직접 전송으로 오류를 방지하면 GPU 동시성이 증가함에 따라 대기 시간을 안정적이고 일정하게 유지할 수 있습니다.
- 스토리지 근처에서 DMA 엔진을 사용하면 CPU 로드에 덜 영향을 미치며 GPU 로드를 방해하지 않습니다. 부분적인 CPU 사용률에 대한 대역폭의 비율은 더 큰 크기의 GPUDirect 스토리지에서 훨씬 더 높습니다. 우리는 다른 DMA 엔진이 데이터를 GPU 메모리로 푸시하거나 풀할 때 GPU 사용률이 거의 0에 가깝게 유지된다는 사실을 이 게시물에 그래픽으로 표시하지는 않았지만 관찰했습니다.
- GPU는 가장 높은 대역폭의 컴퓨팅 엔진일 뿐만 아니라 가장 높은 IO 대역폭을 갖춘 컴퓨팅 요소이기도 합니다. 215GB/s 대 CPU의 50GB/s.
- 이러한 모든 이점은 데이터가 저장되는 위치에 관계없이 달성 가능하므로 CPU 메모리의 페이지 캐시보다 더 빠르게 페타바이트 규모의 원격 스토리지에 빠르게 액세스할 수 있습니다.
- CPU 메모리, 로컬 스토리지 및 원격 스토리지에서 GPU 메모리로 들어가는 대역폭을 추가로 결합하여 GPU 안팎의 대역폭을 거의 포화시킬 수 있습니다. 이는 점점 더 중요해지고 있으며 대규모 분산 데이터 세트의 데이터는 로컬 저장소에 캐시되고 작업 테이블은 CPU 시스템 메모리에 캐시되어 CPU와 협력하여 사용될 수 있습니다.
CPU 대신 GPU를 사용하여 계산 속도를 높이는 이점 외에도 GPUDirect 스토리지는 전체 데이터 처리 파이프라인이 GPU 실행으로 전환될 때 힘을 배가시키는 역할을 합니다. 데이터 세트 크기가 더 이상 시스템 메모리에 맞지 않고 GPU에 대한 데이터 I/O가 증가하여 처리 시간의 병목 현상을 정의하므로 이는 특히 중요합니다.
AI와 데이터 과학이 가능성의 예술을 계속해서 재정의함에 따라 직접 경로를 활성화하면 완전히 완화되지는 않더라도 이러한 병목 현상을 줄일 수 있습니다.
더 자세히 알고 싶으십니까?
업데이트 소식을 계속 받아보려면 GPUDirect 스토리지 관심 목록에 등록하십시오(액세스하려면 NVIDIA 등록 개발자 프로그램의 회원이어야 합니다).
최신 개발에 대한 자세한 내용은 Magnum IO 시리즈를 참조하세요.
감사의 말
우리는 Kiran Modukuri, Akilesh Kailash, Saptarshi Sen 및 Sandeep Joshi를 포함하여 이 콘텐츠의 기초를 제공한 이 작업의 아키텍처, 설계, 평가 및 조정에 대한 GPUDirect 스토리지 팀의 뛰어난 공헌에 깊은 감사를 드립니다. TPC-H에 도움을 준 Nikolay Sakharnykh와 Rui Lan에게 특별한 감사를 드립니다.
GPUDirect 스토리지의 프로토타입 제작 및 초기 데이터 수집에 도움을 주신 다음 동료 여행자에게 감사드립니다.
- 로컬 스토리지에는 Micron 9200 MTFDHAL3T8TCT 3.84TB 및 Samsung MZ1LW960HMJP 960GB NVMe 드라이브를 사용했습니다.
- RAID 0, RAID 5를 수행하고 제어를 현지화하기 위해 인클로저 내부 또는 외부 스토리지에 사용되는 스토리지 컨트롤러가 있을 수 있습니다. 우리는 MicroChip의 SmartROC 3200PE RAID 컨트롤러, HPE Smart Array P408i-a SR Gen10 12G SAS 모듈식 컨트롤러 및 HPE Smart Array P408i-p SR Gen10 12G SAS PCIe 플러그인 컨트롤러를 사용했습니다.
- 패브릭을 통해 스토리지를 활성화할 수 있습니다. 우리는 4개의 Mellanox ConnectX5와 함께 Mellanox MCX455A-ECAT ConnectX4 NIC 및 E8 스토리지 솔루션을 사용했습니다.
우리는 또한 Mark Silberstein의 SPIN 프로젝트와 관련된 작업도 인정합니다.
출처 : https://developer.nvidia.com/blog/gpudirect-storage/