
기본적으로 vSphere는 vCPU 구성 및 vNUMA 토폴로지를 자동으로 관리합니다. vSphere는 해당 VM의 vCPU 수가 해당 호스트의 단일 CPU 소켓 내 물리적 코어 수를 초과할 때까지 VM을 NUMA 노드 내에 유지하려고 시도합니다. 예를 들어 연구소에는 이중 소켓 ESXi 호스트 구성이 있으며 각 호스트에는 소켓당 20개의 프로세서 코어가 있습니다. 따라서 vSphere는 vCPU 개수가 최대 20개인 UMA(Unified Memory Address)를 가진 vCPU 토폴로지를 사용하여 VM을 생성합니다. vCPU 21개를 할당하면 vCPU는 가상 NUMA 노드 2개가 포함된 vNUMA 토폴로지를 생성하고 추가 메모리 최적화를 위해 게스트 OS에 공개합니다.
vNUMA 토폴로지 크기는 vCPU 및 물리적 코어 수를 중심으로 구성되어 있습니다. 그러나 가상 시스템 구성이 vCPU 구성과 함께 NUMA 노드 내에 들어맞으면, 즉 CPU의 물리적 코어보다 vCPU가 적을 경우 어떻게 됩니까? 그러나 VM에는 NUMA 노드가 제공할 수 있는 것보다 더 많은 메모리가 필요합니다. 즉, VM 구성이 NUMA 노드의 로컬 메모리 구성을 초과합니다.
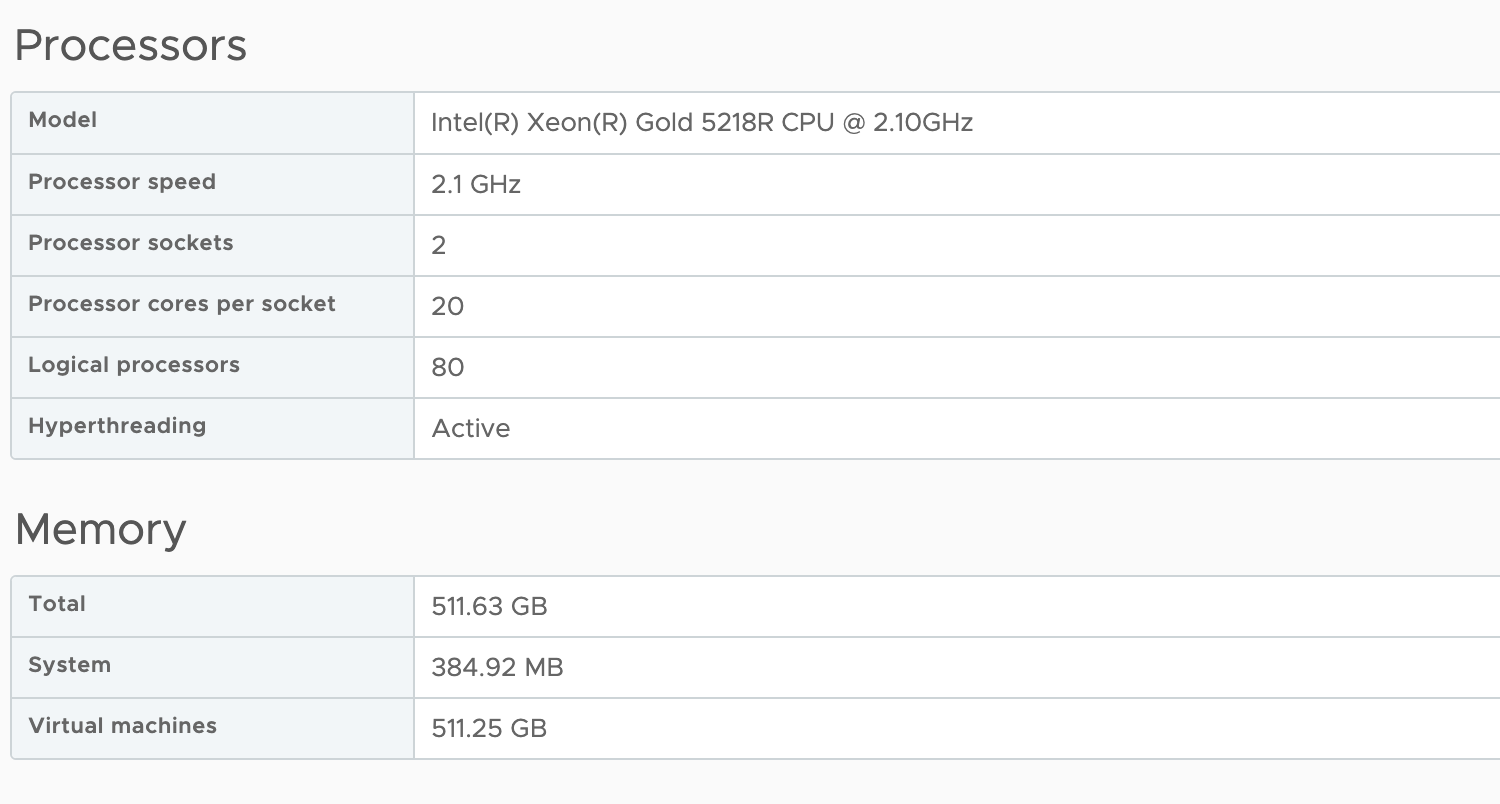
테스트를 위해 vCPU 12개와 384GB를 갖춘 VM을 만들었습니다. vCPU 구성은 단일 NUMA 노드(12<20)에 적합하지만 384GB의 메모리 구성이 각 NUMA 노드의 256GB를 초과합니다.
기본적으로 vSphere는 vCPU 토폴로지를 생성하고 통합 메모리 주소를 게스트 OS에 표시합니다. 스케줄링을 위해 두 NUMA 노드에서 물리적 메모리를 할당하기 위해 두 개의 개별 스케줄링 구조를 생성하지만 해당 정보는 게스트 OS에 노출되지 않습니다. 게스트 OS가 물리적 기원에 대해 아무것도 모른 채 메모리 범위의 시작부터 끝까지 메모리를 할당하기 시작하기 때문에 이 상황에서 일관성 없는 성능이 발생합니다. 테스트로 380GB를 할당하는 애플리케이션이 실행되고 있습니다. 모든 vCPU가 단일 NUMA 노드에서 실행되므로 메모리 스케줄러는 최대한 vCPU에 가깝게 메모리를 할당합니다. 따라서 메모리 스케줄러는 226GB(vm.8823431에 237081912KB)를 로컬로 할당하고 나머지는 원격 NUMA 노드(155GB)에서 할당할 수 있습니다.

로컬 NUMA 노드의 Intel 지연 시간은 Xeon v4의 경우 73ns, Skylake 세대의 경우 89ns 정도입니다. 동시에 원격 메모리는 v4의 경우 약 130ns, Skylake의 경우 139ns이며 AMD Epyc 로컬은 129ns, 원격 메모리는 205ns입니다. Intel의 경우 이는 73% v4, 56% Skylake의 성능에 영향을 미칩니다. AMD의 경우 원격 메모리를 가져와야 하므로 56%의 속도가 느려집니다. 즉, 이 경우 애플리케이션은 메모리의 31%를 가져오지만 지연 시간은 73%입니다.
이 설정의 또 다른 문제는 이 VM이 이제 상당히 불균형한 노이즈가 많은 인접 네트워크라는 것입니다. 시스템의 몬스터 VM에 대해 수행할 작업은 거의 없지만 이 VM에는 불균형한 메모리 공간이 있습니다. NUMA 노드 0의 메모리 대부분을 사용합니다. NUMA 노드의 다른 코어를 활용하고 로컬 메모리에 액세스할 수 있도록 설치 공간을 더 균형 있게 조정했으면 합니다. 이 시나리오에서 새 가상 시스템은 vCPU 관점에서 이 VM과 함께 스케줄링된 경우 다른 NUMA 노드에서 해당 메모리를 검색해야 합니다.
이 문제를 해결하기 위해 vSphere 7 이전 버전에서는 고급 설정 “numa.consolidate = FALSE”을 사용합니다. vSphere 8은 앞서 언급한 문제를 해결하는 UI에서 vCPU 토폴로지, 특히 vNUMA 토폴로지를 구성할 수 있는 옵션을 제공합니다. VM 구성의 VM 옵션에서 vSphere 8에는 CPU 토폴로지 옵션이 포함되어 있습니다.
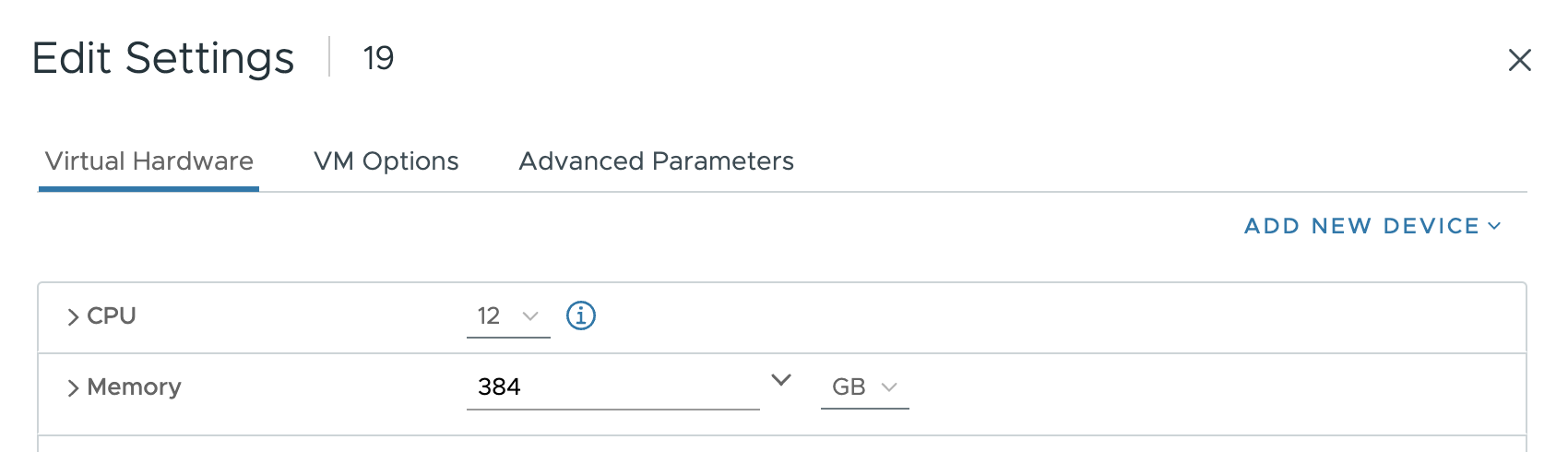
기본적으로 소켓당 코어 수 및 NUMA 노드 설정은 대부분의 워크로드에 권장되는 “Assigned at power on”됩니다. 이 경우에는 이 설정을 변경하려고 하며, 먼저 소켓당 코어 수 설정을 변경해야 NUMA 노드 설정을 조정할 수 있습니다. vCPU의 각 그룹이 동일한 양의 메모리 용량을 할당할 수 있도록 vCPU를 물리적 NUMA 노드에 균등하게 분산하는 것이 가장 좋습니다. 이 테스트에서는 VM 구성을 소켓당 6개 코어로 설정하여 2개의 vSocket을 생성합니다.
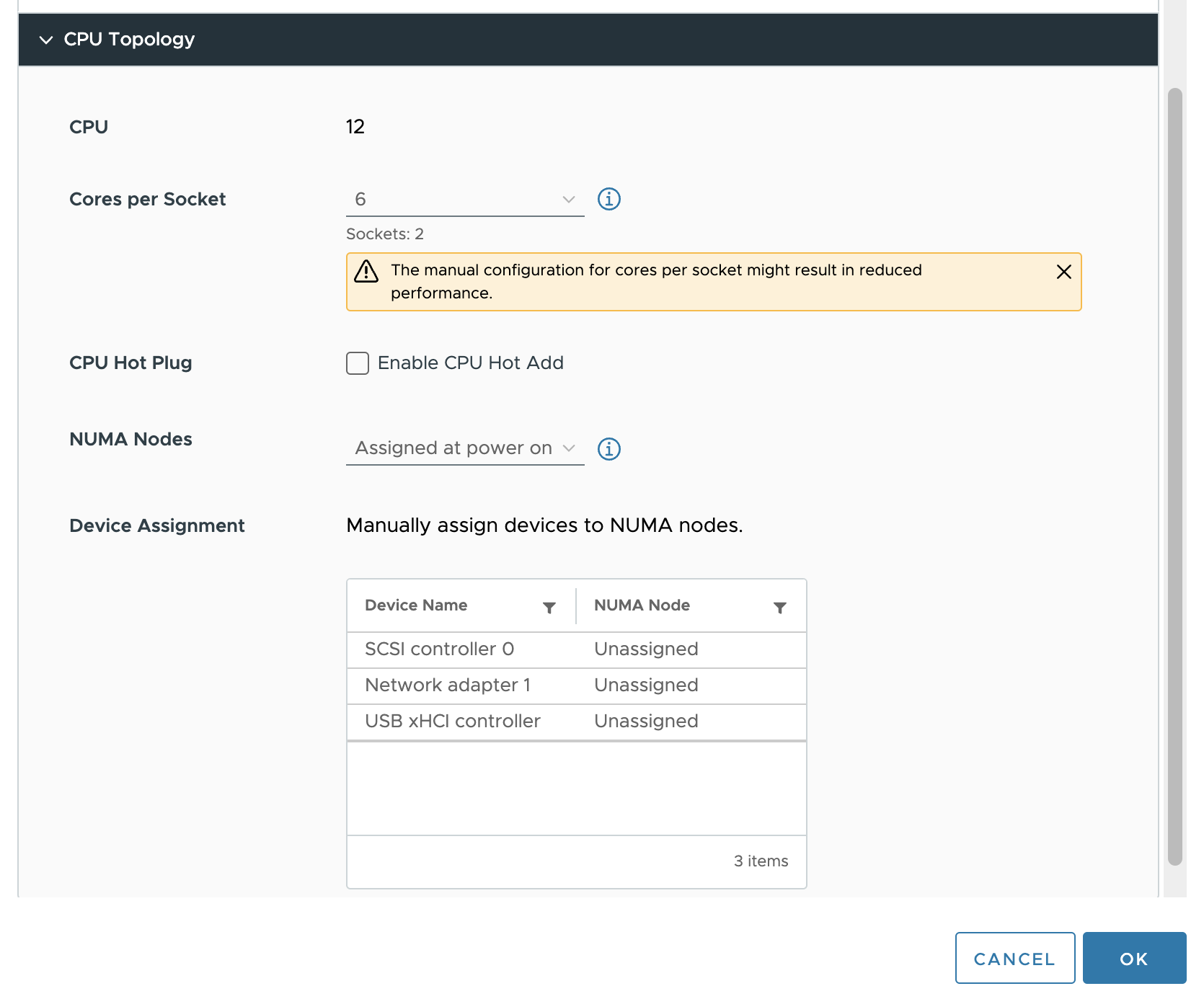
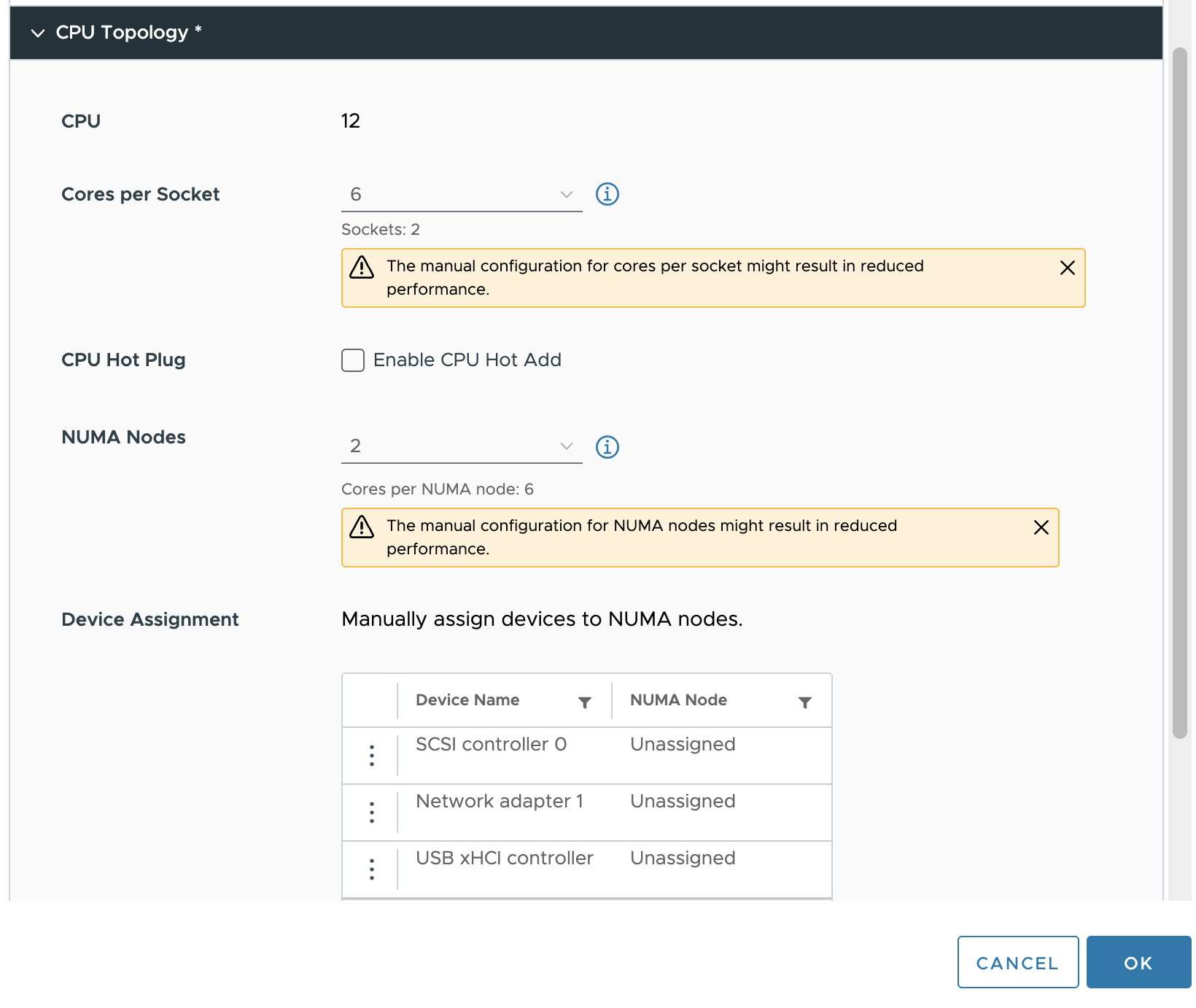
다음 단계는 가상 NUMA 노드를 구성하는 것입니다. 이를 기본 물리적 구성에 맞춰 조정하면 가상 시스템에 대해 최상의 예측 가능하고 일관된 성능 동작을 얻을 수 있습니다. 이 경우 VM은 두 개의 NUMA 노드로 구성됩니다.
가상 시스템의 전원이 켜진 후 ESXi 호스트에 대한 SSH 세션을 열고 다음 명령을 실행했습니다.
"vmdumper -l | cut -d \/ -f 2-5 | while read path; do egrep -oi “DICT.<em>(displayname.</em>|numa.<em>|cores.</em>|vcpu.<em>|memsize.</em>|affinity.<em>)= .</em>|numa:.<em>|numaHost:.</em>” “/$path/vmware.log”; echo -e; done"
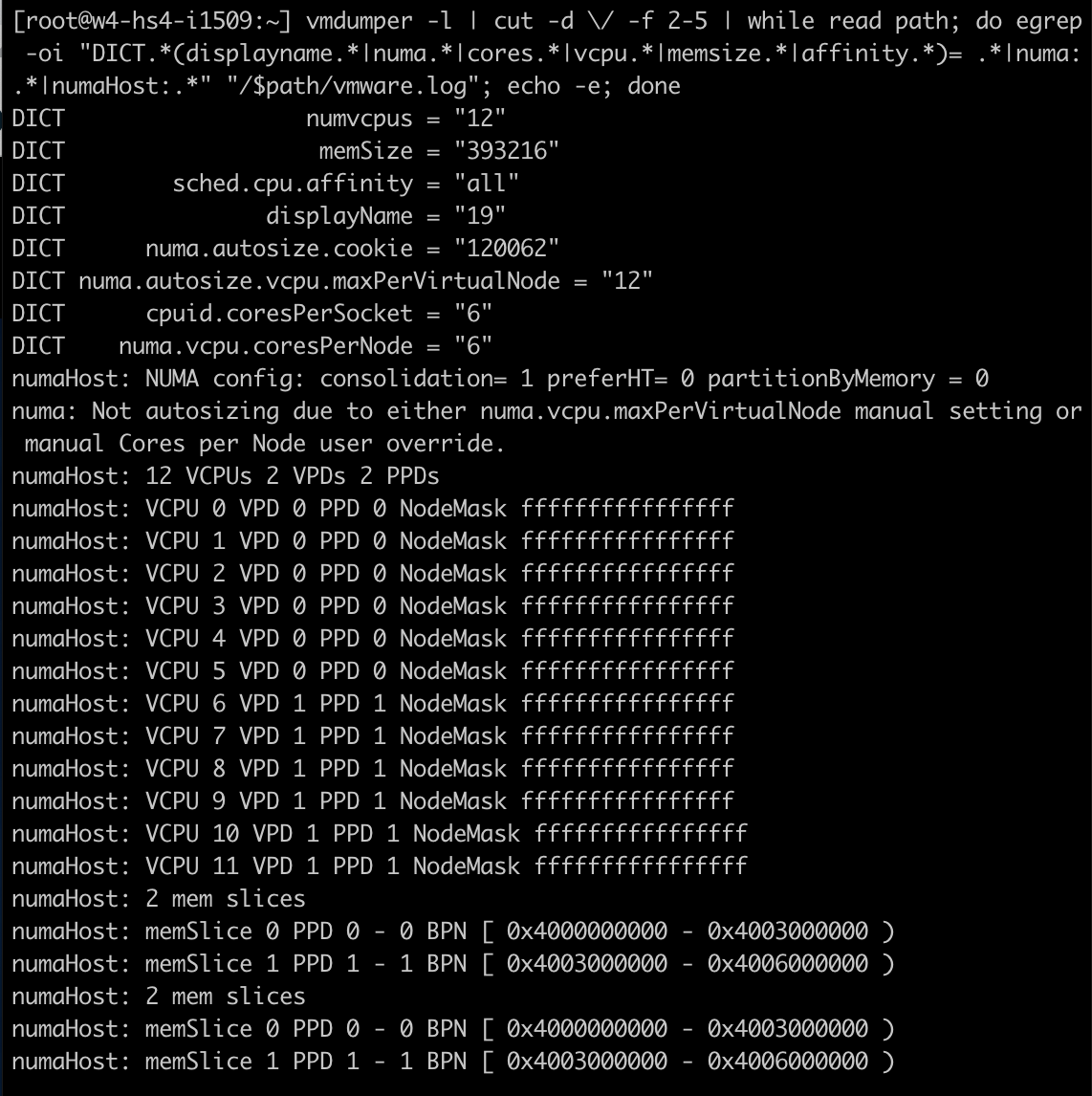
이를 통해 다음과 같은 출력이 제공되었습니다. 다음 줄에 주목하십시오.
cpuid.coresPerSocket = “6” numa.vcpu.coresPerNode = “6” numaHost 12 VCPUs 2 VPDs 2 PPDs
VM이 12개의 vCPU, 소켓당 6개의 코어, NUMA 노드당 6개의 vCPU로 구성되어 있음을 보여줍니다. ESXi 스케줄링 수준에서 NUMA 스케줄러는 두 개의 스케줄링 구조를 생성합니다. VPD(virtual proximity domain)는 CPU 토폴로지를 게스트 OS에 노출하는 데 사용되는 구성입니다. 이 VM에 대해 두 개의 VPD가 생성된 것을 볼 수 있습니다. VPD 0에는 VCPU 0에서 VCPU 5, VPD 1에는 VCPU 6에서 VCPU 11이 포함됩니다. PPD는 물리적 근접 도메인이며 NUMA 스케줄러가 PPD를 물리적 NUMA 노드에 할당하는 데 사용합니다.
모든 작업이 제대로 수행되었는지 확인하기 위해 윈도우즈의 작업 관리자를 살펴보고 NUMA 보기를 사용하도록 설정했습니다. 이제 NUMA 노드가 두 개 표시됩니다.
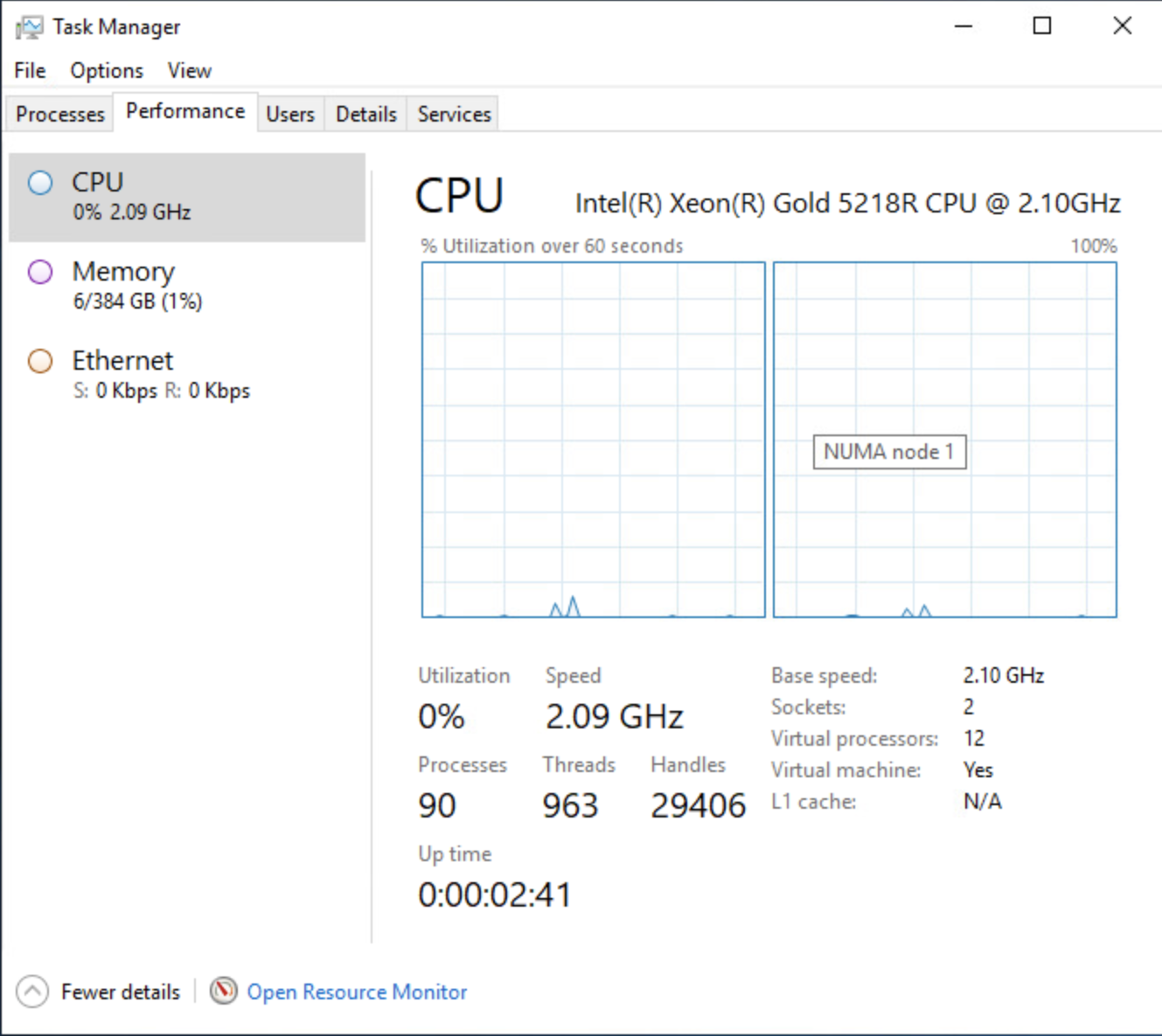
가상 시스템에서 메모리 테스트를 다시 실행하면 ESXi 수준에서 다른 동작이 표시됩니다. 메모리 소비는 훨씬 더 균형이 잡혀 있습니다. NUMA 노드 0의 VM NUMA 클라이언트는 192GB(201326592KB)를 사용하는 반면 NUMA 노드 1의 VM의 NUMA 클라이언트는 189GB(198604800KB)를 사용합니다.

vSphere 8 vCPU 토폴로지는 특별한 경우인 VM 구성을 관리하는 데 도움이 되는 매우 좋은 방법입니다. 고급 설정을 설정해야 하는 대신 VM 구성에 관여하지 않은 팀원이라면 누구나 쉽게 이해할 수 있는 간단한 UI가 큰 발전입니다. 하지만 기본 설정이 대부분의 가상 시스템에 가장 적합하다는 것을 다시 한 번 강조하고 싶습니다. 가상 시스템 real estate에 대한 표준 구성에서는 이 설정을 사용하지 마십시오. 기본값으로 설정된 상태로 유지하고 20년 동안의 NUMA 엔지니어링을 즐기십시오. 우리는 대부분 당신을 지지합니다. 그리고 몇몇 특이치들을 위해, 우리는 이제 훌륭한 UI를 가지고 있습니다.
출처 : https://frankdenneman.nl/2022/11/03/vsphere-8-cpu-topology-for-large-memory-footprint-vms-exceeding-numa-boundaries/



