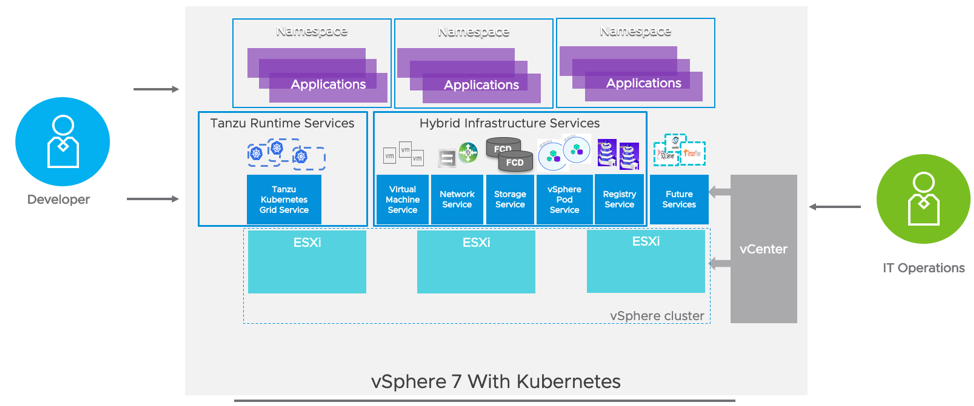
운영 팀은 vSphere 7 with Kubernetes를 함께 사용하여 인프라 및 애플리케이션 서비스를 모두 핵심 플랫폼의 일부로 제공할 수 있다. 네트워크 서비스는 vSphere용 Tanzu Kubernetes Grid Service를 통해 구축된 vSphere와 Tanzu Kubernetes 클러스터에 내장된 Kubernetes 클러스터 모두에 소프트웨어 정의 네트워킹의 자동화를 제공한다.
이 시리즈의 1부에서는 슈퍼바이저 클러스터 네트워킹을 살펴본 후 2부를 최대한 활용하기 위한 사전 요건으로 이 블로그와 데모를 추천했다. 이 글의 끝부분에서 비디오를 시청하는 등 vSphere Network 서비스를 통해 Tanzu Kubernetes 클러스터의 자동화된 네트워킹에 대해 알아보려고 한다.
vSphere 7 with Kubernetes Services
1부에서, 슈퍼바이저 클러스터에서 활성화된 서비스에 대해 토론했다. Tanzu Kubernetes Grid Service for vSphere는 자체 Tanzu Kubernetes 클러스터를 프로비저닝하고자 하는 DevOps 팀을 위해 라이프사이클 관리를 제공할 것이다. vSphere Network 서비스는 NSX를 사용하여 클러스터 노드에 네트워크 인프라를 조정하고 클러스터 자체 내에서 네트워크 오버레이로 Calico를 구현한다. vSphere 7 with Kubernetes에 포함된 기술 개요를 보려면 이 비디오를 확인하기 바란다.
쿠버네티스 맞춤형 리소스
쿠버네티스는 단순한 컨테이너의 Orchestrator가 아니라 쿠버네티스 API를 통해 관리할 수 있는 사용자 지정 자원의 정의를 가능하게 하는 확장형 플랫폼이다. 맞춤형 리소스는 특정 종류의 개체에 대한 구성을 저장하는 API의 끝점이다. 이것은 기본 설치에 없는 개체에 대한 API의 확장이다. API를 통해 무엇보다도 객체를 생성, 업데이트, 삭제 및 가져올 수 있다. 그들 스스로, 이 자원들은 당신이 정보를 저장하고 검색하게 하는 것 이외에는 아무 것도 하지 않는다. 해당 데이터로 작업을 수행하려면 맞춤형 리소스의 변경 사항을 감시하고 작업을 수행하는 컨트롤러를 정의한다. 예: vSphere 가상 시스템 서비스는 맞춤형 리소스 및 컨트롤러 집합으로 구성됨 가상 시스템 리소스가 감독자 클러스터에 생성되면, 가상 시스템 컨트롤러는 vCenter API를 호출하여 해당 맞춤형 리소스를 실제 VM으로 조정하는 역할을 담당한다.
Tanzu Kubernetes 클러스터와 관련 네트워킹의 활성화는 많은 맞춤형 리소스와 해당 컨트롤러의 생성 및 조정을 기반으로 하기 때문에 이러한 설명을 살펴보았다. 앞서 TK 클러스터 구축에 대한 전반적인 프로세스와 사용되는 일부 맞춤형 리소스를 설명하는 영상을 제작해봤다.
탄주 쿠버네티스 클러스터

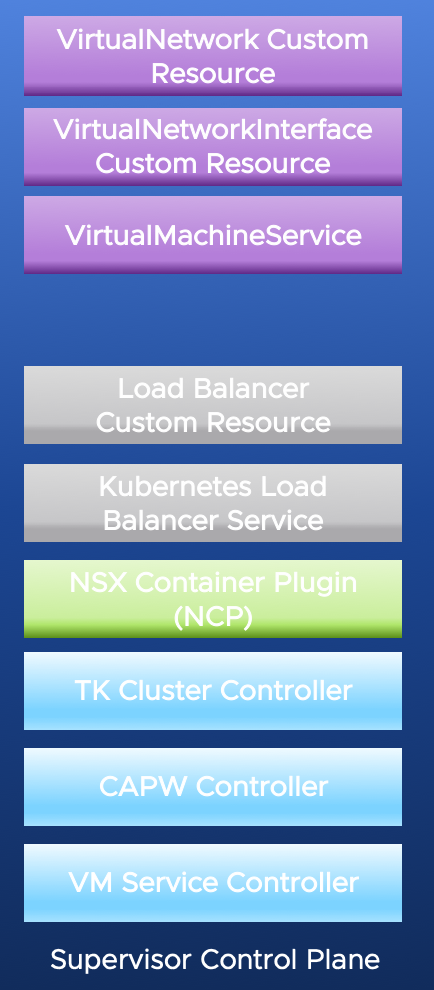
TK 클러스터는 클러스터 API를 구현하는 일련의 맞춤형 리소스에 의해 조정된다. Cluster API는 쿠버네티스 API를 이용해 쿠버네티스 클러스터의 라이프사이클을 관리하는 쿠베르네테스 라이프사이클 SIG의 오픈소스 프로젝트다. 이 API는 Cluster API 문서들이 관리 클러스터라고 부르는 것에서 실행되고 있다. 우리 환경의 관리 클러스터는 슈퍼바이저 클러스터다. Cluster API 구현에는 많은 맞춤형 리소스가 포함된다. 실제로 구현에 더 많은 기능이 포함되어 있는 경우, 아래의 3개의 컨트롤러와 NSX Container Plugin을 참조하여 기능을 요약하고 있다.
Tanzu Kubernetes Cluster Controller는 Tanzukubernetscluster라는 맞춤형 리소스를 감시하고 있으며, Cluster API에서 기대하는 맞춤형 리소스 세트를 생성하는 단계를 밟는다. 이 자원은 간단한 yaml 사양을 적용하여 쿠버네티스 클러스터를 얻는 가장 쉬운 방법을 구현한다.
CAPW Controller는 Cluster API for Workload Control Plane(WCP) 컨트롤러의 약어다. WCP는 VMware 엔지니어가 Supervisor Cluster를 통해 사용할 수 있는 기능을 참조하는 방법이다. CAPW 컨트롤러는 클러스터 API의 인프라별 구현이다.
VM Service Controller가 CAPW에서 생성한 맞춤형 개체를 감시하고 있으며 이러한 규격을 사용하여 TK 클러스터를 구성하는 VM을 생성하고 구성한다.
NSX Container Plugin(NCP)은 컨트롤러로, 슈퍼바이저 클러스터 제어면에서 Kubernetes 포드로 실행된다. Kubernetes API를 통해 etcd에 추가된 네트워크 리소스를 감시하고 NSX에서 해당 개체의 생성을 조정한다.
이러한 각 컨트롤러는 슈퍼바이저 클러스터의 제어면에서 포드로 실행된다는 점에 유의한다.
Tanzu Kubernetes Cluster Node Networking
Virtual Network Custom Resource


클러스터 노드와 연결된 맞춤형 리소스가 조정되고 있을 때 CAPW는 클러스터에 대한 네트워크 구성 정보를 저장하는 VirtualNetwork 맞춤형 리소스를 생성한다.
NCP는 그 자원을 감시하고 있으며, 환경의 활성 상태를 이 자원에 정의된 원하는 상태로 조정할 것이다. 즉, NSX API를 호출하여 클러스터에 대한 새 네트워크 세그먼트, Tier-1 게이트웨이 및 IP 서브넷을 생성한다.
Virtual Network Interfaces Custom Resources
VM Service Controller가 클러스터의 가상 시스템을 생성할 때, 각 VM에 대한 VirtualNetworkInterface를 생성한다. NCP는 이전에 생성한 네트워크 세그먼트에 인터페이스를 생성하고 VirtualMachineNetworkInterface 리소스에서 정보를 업데이트한다. VM Service Controller는 이 정보를 사용하여 VM의 가상 NIC를 구성하고 적절한 IP, MAC 및 게이트웨이 정보를 추가한다.

Tanzu Kubernetes 클러스터로 Ingress
이제 클러스터 노드 VM이 생성되고 노드 레벨의 네트워크 액세스 권한이 있으므로 클러스터로의 수신을 구성해야 한다. 방금 할당한 IP는 슈퍼바이저 클러스터 생성 시 정의된 포드 CIDR의 일부로서 클러스터 외부에서 라우팅할 수 없다.
Ingress를 얻으려면 제어부 노드의 끝점으로 구성된 가상 서버를 사용하여 Loadbalancer를 생성해야 한다. Loadbalancer는 또한 Supervisor Cluster 생성 시 정의된 수신 CIDR로부터 IP를 얻는다.
CAPW 컨트롤러는 VirtualMachineService 맞춤형 리소스를 생성하고, VM 서비스 컨트롤러는 로드 밸런서 사용자 지정 리소스 및 Kubernetes 로드 밸런서 서비스를 생성한다. NCP는 로드 밸런서 맞춤형 리소스를 NSX Load Balancer로 변환하고 Kubernetes Load Balancer 서비스를 엔드포인트 정보를 보유한 NSX 가상 서버로 변환한다. 그런 다음 이러한 엔드포인트가 Kubernetes 로드 밸런서 서비스로 업데이트된다.
만약 당신이 쿠버네티스의 맞춤형 자원을 처음 접했다면, 이것은 많은 정보다. 이 글 아래쪽에 있는 동영상은 어떻게 작동하는지 보여줄 것이다.
Calico를 사용한 오버레이 네트워킹
이제 우리의 클러스터 노드는 트래픽이 클러스터의 제어부 노드로 라우팅될 수 있도록 연결과 로드 밸런서를 가지고 있지만, 클러스터 내에 정의된 포드나 서비스에 대한 연결은 없다. Tanzu Kubernetes 클러스터는 네트워크 제공자를 Kubernetes 네트워킹에 연결하는 방법으로 CNI(Container Network Interface)를 사용한다. 여러 제공자가 사용할 수 있는 플러그인 프레임워크다. 초기에는 Calico가 TK 클러스터를 위해 지원되는 CNI이다. 향후 CNI가 추가될 예정이다.
Calico는 TK 클러스터의 각 노드에서 에이전트를 운영하고 있다. 이 에이전트는 Felix와 Bird라는 두 가지 주요 구성요소를 가지고 있다. 펠릭스는 호스트의 라우팅 테이블과 호스트의 포드나 서비스에 대한 연결을 제공하는 것과 관련된 다른 모든 것을 업데이트하는 일을 담당한다. 버드는 BGP(Border Gateway Protocol) 클라이언트다. 특정 노드에서 펠릭스에 의해 갱신된 경로를 클러스터의 다른 모든 노드에 광고할 책임이 있다.
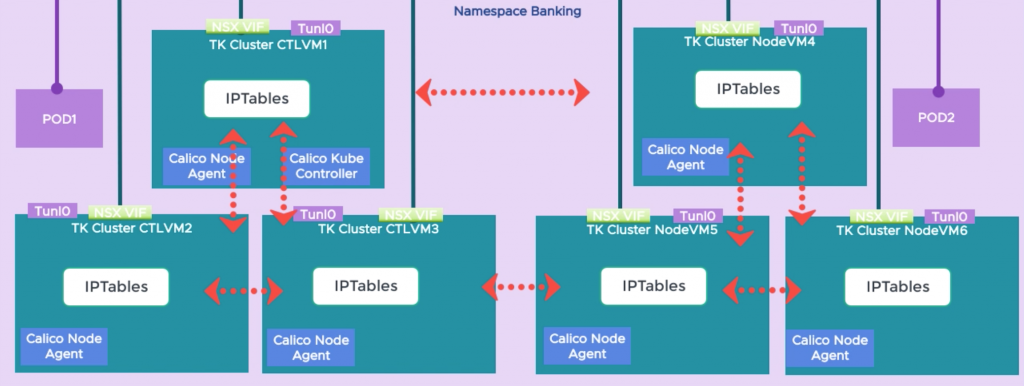
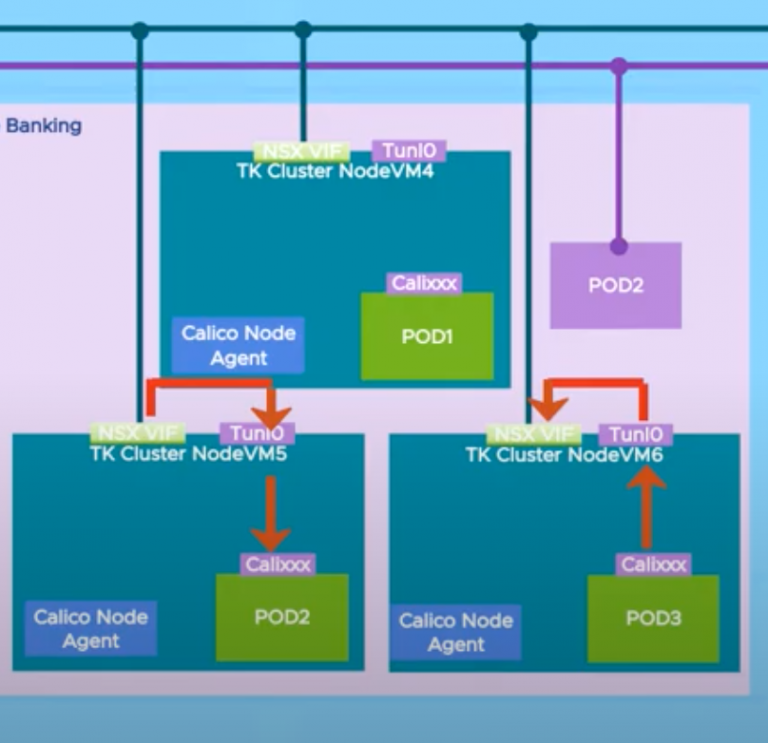
포드 간 통신
Kubernetes 네트워킹에 대한 요구 사항 중 하나는 NAT 없이 동일한 클러스터에 있는 포드 간의 통신이 이루어져야 한다는 것이다. 캘리코는 IP 터널링이 활성화된 상태로 구현된다. 포드가 생성되면 노드에 할당된 서브넷에서 가상 인터페이스(Calixxxx)와 IP를 얻는다. 라우팅 테이블은 Felix에 의해 클러스터의 각 노드에 대한 IP 서브넷으로 업데이트된다.
노드 간 포드 통신을 위해 트래픽은 Tunl0 인터페이스로 라우팅되고 대상 노드의 IP를 포함하는 새 헤더로 캡슐화된다. 노드는 또한 계층 3 게이트웨이로도 구성되고 Tunl0 트래픽은 NSX 가상 인터페이스를 벗어나 클러스터에 할당된 NSX 세그먼트를 통과하게 된다. 그런 다음 Tunl0에서 캡슐화되지 않은 적절한 노드로 라우팅되고 최종적으로 Calixxxxx veth 쌍을 통해 포드에 전달된다. NAT은 클러스터 외부 네트워크로 향하는 트래픽에만 발생한다.
TK 클러스터에서 실행되는 포드에 Ingress 제공
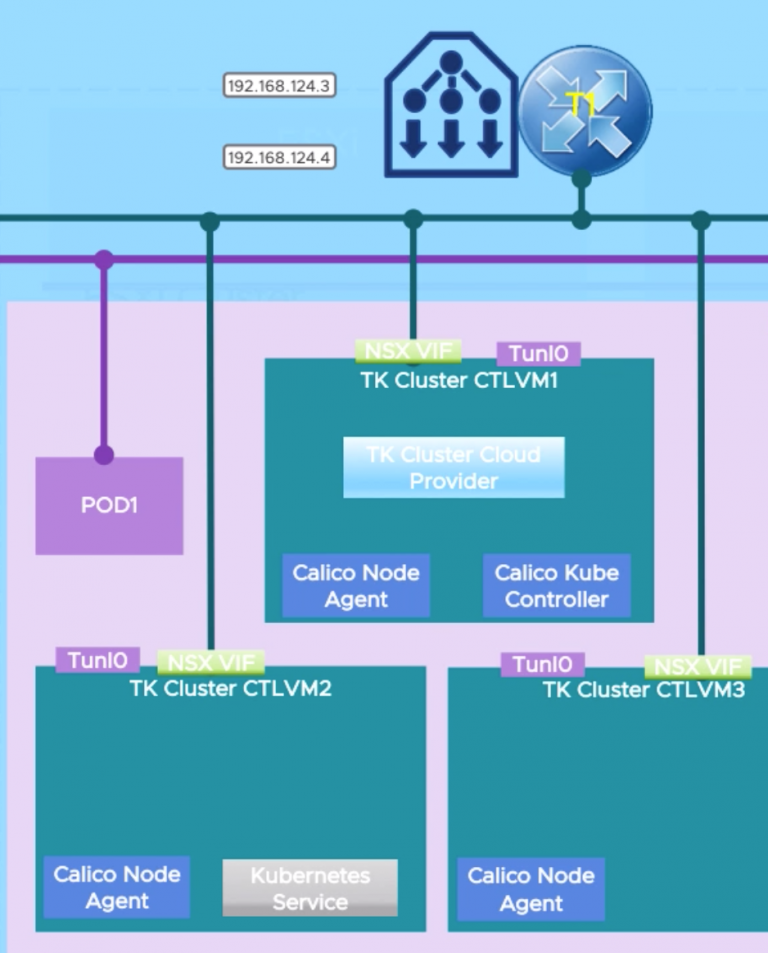
TK 클러스터는 클러스터 배포에서 생성된 로드 밸런서를 사용하여 외부 네트워크에서 클러스터에서 실행 중인 포드까지 수신 기능을 제공한다. 사용자가 클러스터에 Kubernetes 로드 밸런서 서비스를 생성해서 Ingress 기능을 제공한다.
네임스페이스 편집 권한이 있는 사용자는 TK 클러스터에 대한 클러스터 관리자 역할을 가지고 있으므로, 해당 사용자가 TK 클러스터에 저장된 모든 인증 정보에 액세스할 수 있다. 이러한 이유로 우리는 TK 클러스터에서 vCenter 또는 NSX에 직접 액세스하고 싶지 않다. NSX 가상 서버 또는 vSphere 스토리지 볼륨 생성과 같이 액세스가 필요한 작업은 Supervisor 클러스터에 프록시 처리된다.
이것은 자원의 프록시를 위한 과정이다. TK 클러스터의 제어면에서 TK클러스터 클라우드 제공자가 가동되고 있다. TK 클러스터에 Kubernetes Load Balancer 서비스가 생성되면 클라우드 제공자가 슈퍼바이저 클러스터의 Kubernetes API에 전화를 걸어 VirtualMachineService 사용자 지정 리소스를 생성한다. 앞에서 설명한 대로 VirtualMachineService는 슈퍼바이저 클러스터에서 새로운 Kubernetes 로드 밸런서 서비스로 조정된다. 그런 다음 NCP는 해당 서비스를 NSX Virtual Server로 조정하고 서비스에 액세스하는 데 필요한 엔드포인트를 조정한다. 이로 인해 사용자는 원래 클러스터 로드 밸런싱 장치에서 새 IP를 통해 서비스에 액세스하게 된다.
행동으로 보자!!
하나의 글에 담기에 내용이 너무 많다. 영상에서 좀 더 자세히 살펴보자.





